Transforms#
Generic Interfaces#
Transform#
- class monai.transforms.Transform[source]#
An abstract class of a
Transform. A transform is callable that processesdata.It could be stateful and may modify
datain place, the implementation should be aware of:thread safety when mutating its own states. When used from a multi-process context, transform’s instance variables are read-only. thread-unsafe transforms should inherit
monai.transforms.ThreadUnsafe.datacontent unused by this transform may still be used in the subsequent transforms in a composed transform.storing too much information in
datamay cause some memory issue or IPC sync issue, especially in the multi-processing environment of PyTorch DataLoader.
See Also
- abstract __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
MapTransform#
- class monai.transforms.MapTransform(keys, allow_missing_keys=False)[source]#
A subclass of
monai.transforms.Transformwith an assumption that thedatainput ofself.__call__is a MutableMapping such asdict.The
keysparameter will be used to get and set the actual data item to transform. That is, the callable of this transform should follow the pattern:def __call__(self, data): for key in self.keys: if key in data: # update output data with some_transform_function(data[key]). else: # raise exception unless allow_missing_keys==True. return data
- Raises:
ValueError – When
keysis an empty iterable.TypeError – When
keystype is not inUnion[Hashable, Iterable[Hashable]].
- abstract __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- call_update(data)[source]#
This function is to be called after every self.__call__(data), update data[key_transforms] and data[key_meta_dict] using the content from MetaTensor data[key], for MetaTensor backward compatibility 0.9.0.
- first_key(data)[source]#
Get the first available key of self.keys in the input data dictionary. If no available key, return an empty tuple ().
- Parameters:
data (
dict[Hashable,Any]) – data that the transform will be applied to.
- key_iterator(data, *extra_iterables)[source]#
Iterate across keys and optionally extra iterables. If key is missing, exception is raised if allow_missing_keys==False (default). If allow_missing_keys==True, key is skipped.
- Parameters:
data – data that the transform will be applied to
extra_iterables – anything else to be iterated through
RandomizableTrait#
- class monai.transforms.RandomizableTrait[source]#
An interface to indicate that the transform has the capability to perform randomized transforms to the data that it is called upon. This interface can be extended from by people adapting transforms to the MONAI framework as well as by implementors of MONAI transforms.
LazyTrait#
- class monai.transforms.LazyTrait[source]#
An interface to indicate that the transform has the capability to execute using MONAI’s lazy resampling feature. In order to do this, the implementing class needs to be able to describe its operation as an affine matrix or grid with accompanying metadata. This interface can be extended from by people adapting transforms to the MONAI framework as well as by implementors of MONAI transforms.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
MultiSampleTrait#
- class monai.transforms.MultiSampleTrait[source]#
An interface to indicate that the transform has the capability to return multiple samples given an input, such as when performing random crops of a sample. This interface can be extended from by people adapting transforms to the MONAI framework as well as by implementors of MONAI transforms.
Randomizable#
- class monai.transforms.Randomizable[source]#
An interface for handling random state locally, currently based on a class variable R, which is an instance of np.random.RandomState. This provides the flexibility of component-specific determinism without affecting the global states. It is recommended to use this API with
monai.data.DataLoaderfor deterministic behaviour of the preprocessing pipelines. This API is not thread-safe. Additionally, deepcopying instance of this class often causes insufficient randomness as the random states will be duplicated.- randomize(data)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
LazyTransform#
- class monai.transforms.LazyTransform(lazy=False)[source]#
An implementation of functionality for lazy transforms that can be subclassed by array and dictionary transforms to simplify implementation of new lazy transforms.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
RandomizableTransform#
- class monai.transforms.RandomizableTransform(prob=1.0, do_transform=True)[source]#
An interface for handling random state locally, currently based on a class variable R, which is an instance of np.random.RandomState. This class introduces a randomized flag _do_transform, is mainly for randomized data augmentation transforms. For example:
from monai.transforms import RandomizableTransform class RandShiftIntensity100(RandomizableTransform): def randomize(self): super().randomize(None) self._offset = self.R.uniform(low=0, high=100) def __call__(self, img): self.randomize() if not self._do_transform: return img return img + self._offset transform = RandShiftIntensity() transform.set_random_state(seed=0) print(transform(10))
- randomize(data)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
Compose#
- class monai.transforms.Compose(transforms=None, map_items=True, unpack_items=False, log_stats=False, lazy=False, overrides=None)[source]#
Composeprovides the ability to chain a series of callables together in a sequential manner. Each transform in the sequence must take a single argument and return a single value.Composecan be used in two ways:With a series of transforms that accept and return a single ndarray / tensor / tensor-like parameter.
With a series of transforms that accept and return a dictionary that contains one or more parameters. Such transforms must have pass-through semantics that unused values in the dictionary must be copied to the return dictionary. It is required that the dictionary is copied between input and output of each transform.
If some transform takes a data item dictionary as input, and returns a sequence of data items in the transform chain, all following transforms will be applied to each item of this list if map_items is True (the default). If map_items is False, the returned sequence is passed whole to the next callable in the chain.
For example:
A Compose([transformA, transformB, transformC], map_items=True)(data_dict) could achieve the following patch-based transformation on the data_dict input:
transformA normalizes the intensity of ‘img’ field in the data_dict.
transformB crops out image patches from the ‘img’ and ‘seg’ of data_dict, and return a list of three patch samples:
{'img': 3x100x100 data, 'seg': 1x100x100 data, 'shape': (100, 100)} applying transformB ----------> [{'img': 3x20x20 data, 'seg': 1x20x20 data, 'shape': (20, 20)}, {'img': 3x20x20 data, 'seg': 1x20x20 data, 'shape': (20, 20)}, {'img': 3x20x20 data, 'seg': 1x20x20 data, 'shape': (20, 20)},]
transformC then randomly rotates or flips ‘img’ and ‘seg’ of each dictionary item in the list returned by transformB.
The composed transforms will be set the same global random seed if user called set_determinism().
When using the pass-through dictionary operation, you can make use of
monai.transforms.adaptors.adaptorto wrap transforms that don’t conform to the requirements. This approach allows you to use transforms from otherwise incompatible libraries with minimal additional work.Note
In many cases, Compose is not the best way to create pre-processing pipelines. Pre-processing is often not a strictly sequential series of operations, and much of the complexity arises when a not-sequential set of functions must be called as if it were a sequence.
Example: images and labels Images typically require some kind of normalization that labels do not. Both are then typically augmented through the use of random rotations, flips, and deformations. Compose can be used with a series of transforms that take a dictionary that contains ‘image’ and ‘label’ entries. This might require wrapping torchvision transforms before passing them to compose. Alternatively, one can create a class with a __call__ function that calls your pre-processing functions taking into account that not all of them are called on the labels.
Lazy resampling:
Lazy resampling is an experimental feature introduced in 1.2. Its purpose is to reduce the number of resample operations that must be carried out when executing a pipeline of transforms. This can provide significant performance improvements in terms of pipeline executing speed and memory usage, and can also significantly reduce the loss of information that occurs when performing a number of spatial resamples in succession.
Lazy resampling can be enabled or disabled through the
lazyparameter, either by specifying it at initialisation time or overriding it at call time.False (default): Don’t perform any lazy resampling
None: Perform lazy resampling based on the ‘lazy’ properties of the transform instances.
True: Always perform lazy resampling if possible. This will ignore the
lazyproperties of the transform instances
Please see the Lazy Resampling topic for more details of this feature and examples of its use.
- Parameters:
transforms – sequence of callables.
map_items – whether to apply transform to each item in the input data if data is a list or tuple. defaults to True.
unpack_items – whether to unpack input data with * as parameters for the callable function of transform. defaults to False.
log_stats – this optional parameter allows you to specify a logger by name for logging of pipeline execution. Setting this to False disables logging. Setting it to True enables logging to the default loggers. Setting a string overrides the logger name to which logging is performed.
lazy – whether to enable Lazy Resampling for lazy transforms. If False, transforms will be carried out on a transform by transform basis. If True, all lazy transforms will be executed by accumulating changes and resampling as few times as possible. If lazy is None, Compose will perform lazy execution on lazy transforms that have their lazy property set to True.
overrides – this optional parameter allows you to specify a dictionary of parameters that should be overridden when executing a pipeline. These each parameter that is compatible with a given transform is then applied to that transform before it is executed. Note that overrides are currently only applied when Lazy Resampling is enabled for the pipeline or a given transform. If lazy is False they are ignored. Currently supported args are: {
"mode","padding_mode","dtype","align_corners","resample_mode",device}.
- flatten()[source]#
Return a Composition with a simple list of transforms, as opposed to any nested Compositions.
e.g., t1 = Compose([x, x, x, x, Compose([Compose([x, x]), x, x])]).flatten() will result in the equivalent of t1 = Compose([x, x, x, x, x, x, x, x]).
- get_index_of_first(predicate)[source]#
get_index_of_first takes a
predicateand returns the index of the first transform that satisfies the predicate (ie. makes the predicate return True). If it is unable to find a transform that satisfies thepredicate, it returns None.Example
c = Compose([Flip(…), Rotate90(…), Zoom(…), RandRotate(…), Resize(…)])
print(c.get_index_of_first(lambda t: isinstance(t, RandomTrait))) >>> 3 print(c.get_index_of_first(lambda t: isinstance(t, Compose))) >>> None
Note
This is only performed on the transforms directly held by this instance. If this instance has nested
Composetransforms or other transforms that contain transforms, it does not iterate into them.- Parameters:
predicate – a callable that takes a single argument and returns a bool. When called
compose (it is passed a transform from the sequence of transforms contained by this)
instance.
- Returns:
The index of the first transform in the sequence for which
predicatereturns True. None if no transform satisfies thepredicate
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
InvertibleTransform#
- class monai.transforms.InvertibleTransform[source]#
Classes for invertible transforms.
This class exists so that an
invertmethod can be implemented. This allows, for example, images to be cropped, rotated, padded, etc., during training and inference, and after be returned to their original size before saving to file for comparison in an external viewer.When the
inversemethod is called:the inverse is called on each key individually, which allows for different parameters being passed to each label (e.g., different interpolation for image and label).
the inverse transforms are applied in a last-in-first-out order. As the inverse is applied, its entry is removed from the list detailing the applied transformations. That is to say that during the forward pass, the list of applied transforms grows, and then during the inverse it shrinks back down to an empty list.
We currently check that the
id()of the transform is the same in the forward and inverse directions. This is a useful check to ensure that the inverses are being processed in the correct order.Note to developers: When converting a transform to an invertible transform, you need to:
Inherit from this class.
In
__call__, add a call topush_transform.Any extra information that might be needed for the inverse can be included with the dictionary
extra_info. This dictionary should have the same keys regardless of whetherdo_transformwas True or False and can only contain objects that are accepted in pytorch data loader’s collate function (e.g., None is not allowed).Implement an
inversemethod. Make sure that after performing the inverse,pop_transformis called.
TraceableTransform#
- class monai.transforms.TraceableTransform[source]#
Maintains a stack of applied transforms to data.
- Data can be one of two types:
A MetaTensor (this is the preferred data type).
- A dictionary of data containing arrays/tensors and auxiliary metadata. In
this case, a key must be supplied (this dictionary-based approach is deprecated).
If data is of type MetaTensor, then the applied transform will be added to
data.applied_operations.- If data is a dictionary, then one of two things can happen:
If data[key] is a MetaTensor, the applied transform will be added to
data[key].applied_operations.- Else, the applied transform will be appended to an adjacent list using
trace_key. If, for example, the key is image, then the transform will be appended to image_transforms (this dictionary-based approach is deprecated).
- Hopefully it is clear that there are three total possibilities:
data is MetaTensor
data is dictionary, data[key] is MetaTensor
data is dictionary, data[key] is not MetaTensor (this is a deprecated approach).
The
__call__method of this transform class must be implemented so that the transformation information is stored during the data transformation.The information in the stack of applied transforms must be compatible with the default collate, by only storing strings, numbers and arrays.
tracing could be enabled by self.set_tracing or setting MONAI_TRACE_TRANSFORM when initializing the class.
- get_most_recent_transform(data, key=None, check=True, pop=False)[source]#
Get most recent transform for the stack.
- Parameters:
data – dictionary of data or MetaTensor.
key (
Optional[Hashable]) – if data is a dictionary, data[key] will be modified.check (
bool) – if true, check that self is the same type as the most recently-applied transform.pop (
bool) – if true, remove the transform as it is returned.
- Returns:
Dictionary of most recently applied transform
- Raises:
- RuntimeError – data is neither MetaTensor nor dictionary
- get_transform_info()[source]#
Return a dictionary with the relevant information pertaining to an applied transform.
- Return type:
dict
- pop_transform(data, key=None, check=True)[source]#
Return and pop the most recent transform.
- Parameters:
data – dictionary of data or MetaTensor
key (
Optional[Hashable]) – if data is a dictionary, data[key] will be modifiedcheck (
bool) – if true, check that self is the same type as the most recently-applied transform.
- Returns:
Dictionary of most recently applied transform
- Raises:
- RuntimeError – data is neither MetaTensor nor dictionary
- push_transform(data, *args, **kwargs)[source]#
Push to a stack of applied transforms of
data.- Parameters:
data – dictionary of data or MetaTensor.
args – additional positional arguments to track_transform_meta.
kwargs – additional keyword arguments to track_transform_meta, set
replace=True(default False) to rewrite the last transform infor in applied_operation/pending_operation based onself.get_transform_info().
- trace_transform(to_trace)[source]#
Temporarily set the tracing status of a transform with a context manager.
- classmethod track_transform_meta(data, key=None, sp_size=None, affine=None, extra_info=None, orig_size=None, transform_info=None, lazy=False)[source]#
Update a stack of applied/pending transforms metadata of
data.- Parameters:
data – dictionary of data or MetaTensor.
key – if data is a dictionary, data[key] will be modified.
sp_size – the expected output spatial size when the transform is applied. it can be tensor or numpy, but will be converted to a list of integers.
affine – the affine representation of the (spatial) transform in the image space. When the transform is applied, meta_tensor.affine will be updated to
meta_tensor.affine @ affine.extra_info – if desired, any extra information pertaining to the applied transform can be stored in this dictionary. These are often needed for computing the inverse transformation.
orig_size – sometimes during the inverse it is useful to know what the size of the original image was, in which case it can be supplied here.
transform_info – info from self.get_transform_info().
lazy – whether to push the transform to pending_operations or applied_operations.
- Returns:
For backward compatibility, if
datais a dictionary, it returns the dictionary with updateddata[key]. Otherwise, this function returns a MetaObj with updated transform metadata.
BatchInverseTransform#
- class monai.transforms.BatchInverseTransform(transform, loader, collate_fn=<function no_collation>, num_workers=0, detach=True, pad_batch=True, fill_value=None)[source]#
Perform inverse on a batch of data. This is useful if you have inferred a batch of images and want to invert them all.
- __init__(transform, loader, collate_fn=<function no_collation>, num_workers=0, detach=True, pad_batch=True, fill_value=None)[source]#
- Parameters:
transform – a callable data transform on input data.
loader – data loader used to run transforms and generate the batch of data.
collate_fn – how to collate data after inverse transformations. default won’t do any collation, so the output will be a list of size batch size.
num_workers – number of workers when run data loader for inverse transforms, default to 0 as only run 1 iteration and multi-processing may be even slower. if the transforms are really slow, set num_workers for multi-processing. if set to None, use the num_workers of the transform data loader.
detach – whether to detach the tensors. Scalars tensors will be detached into number types instead of torch tensors.
pad_batch – when the items in a batch indicate different batch size, whether to pad all the sequences to the longest. If False, the batch size will be the length of the shortest sequence.
fill_value – the value to fill the padded sequences when pad_batch=True.
Decollated#
- class monai.transforms.Decollated(keys=None, detach=True, pad_batch=True, fill_value=None, allow_missing_keys=False)[source]#
Decollate a batch of data. If input is a dictionary, it also supports to only decollate specified keys. Note that unlike most MapTransforms, it will delete the other keys that are not specified. if keys=None, it will decollate all the data in the input. It replicates the scalar values to every item of the decollated list.
- Parameters:
keys – keys of the corresponding items to decollate, note that it will delete other keys not specified. if None, will decollate all the keys. see also:
monai.transforms.compose.MapTransform.detach – whether to detach the tensors. Scalars tensors will be detached into number types instead of torch tensors.
pad_batch – when the items in a batch indicate different batch size, whether to pad all the sequences to the longest. If False, the batch size will be the length of the shortest sequence.
fill_value – the value to fill the padded sequences when pad_batch=True.
allow_missing_keys – don’t raise exception if key is missing.
OneOf#
- class monai.transforms.OneOf(transforms=None, weights=None, map_items=True, unpack_items=False, log_stats=False, lazy=False, overrides=None)[source]#
OneOfprovides the ability to randomly choose one transform out of a list of callables with pre-defined probabilities for each.- Parameters:
transforms – sequence of callables.
weights – probabilities corresponding to each callable in transforms. Probabilities are normalized to sum to one.
map_items – whether to apply transform to each item in the input data if data is a list or tuple. defaults to True.
unpack_items – whether to unpack input data with * as parameters for the callable function of transform. defaults to False.
log_stats – this optional parameter allows you to specify a logger by name for logging of pipeline execution. Setting this to False disables logging. Setting it to True enables logging to the default loggers. Setting a string overrides the logger name to which logging is performed.
lazy – whether to enable Lazy Resampling for lazy transforms. If False, transforms will be carried out on a transform by transform basis. If True, all lazy transforms will be executed by accumulating changes and resampling as few times as possible. If lazy is None, Compose will perform lazy execution on lazy transforms that have their lazy property set to True.
overrides – this optional parameter allows you to specify a dictionary of parameters that should be overridden when executing a pipeline. These each parameter that is compatible with a given transform is then applied to that transform before it is executed. Note that overrides are currently only applied when Lazy Resampling is enabled for the pipeline or a given transform. If lazy is False they are ignored. Currently supported args are: {
"mode","padding_mode","dtype","align_corners","resample_mode",device}.
RandomOrder#
- class monai.transforms.RandomOrder(transforms=None, map_items=True, unpack_items=False, log_stats=False, lazy=False, overrides=None)[source]#
RandomOrderprovides the ability to apply a list of transformations in random order.- Parameters:
transforms – sequence of callables.
map_items – whether to apply transform to each item in the input data if data is a list or tuple. defaults to True.
unpack_items – whether to unpack input data with * as parameters for the callable function of transform. defaults to False.
log_stats – this optional parameter allows you to specify a logger by name for logging of pipeline execution. Setting this to False disables logging. Setting it to True enables logging to the default loggers. Setting a string overrides the logger name to which logging is performed.
lazy – whether to enable Lazy Resampling for lazy transforms. If False, transforms will be carried out on a transform by transform basis. If True, all lazy transforms will be executed by accumulating changes and resampling as few times as possible. If lazy is None, Compose will perform lazy execution on lazy transforms that have their lazy property set to True.
overrides – this optional parameter allows you to specify a dictionary of parameters that should be overridden when executing a pipeline. These each parameter that is compatible with a given transform is then applied to that transform before it is executed. Note that overrides are currently only applied when Lazy Resampling is enabled for the pipeline or a given transform. If lazy is False they are ignored. Currently supported args are: {
"mode","padding_mode","dtype","align_corners","resample_mode",device}.
SomeOf#
- class monai.transforms.SomeOf(transforms=None, map_items=True, unpack_items=False, log_stats=False, num_transforms=None, replace=False, weights=None, lazy=False, overrides=None)[source]#
SomeOfsamples a different sequence of transforms to apply each time it is called.It can be configured to sample a fixed or varying number of transforms each time its called. Samples are drawn uniformly, or from user supplied transform weights. When varying the number of transforms sampled per call, the number of transforms to sample that call is sampled uniformly from a range supplied by the user.
- Parameters:
transforms – list of callables.
map_items – whether to apply transform to each item in the input data if data is a list or tuple. Defaults to True.
unpack_items – whether to unpack input data with * as parameters for the callable function of transform. Defaults to False.
log_stats – this optional parameter allows you to specify a logger by name for logging of pipeline execution. Setting this to False disables logging. Setting it to True enables logging to the default loggers. Setting a string overrides the logger name to which logging is performed.
num_transforms – a 2-tuple, int, or None. The 2-tuple specifies the minimum and maximum (inclusive) number of transforms to sample at each iteration. If an int is given, the lower and upper bounds are set equal. None sets it to len(transforms). Default to None.
replace – whether to sample with replacement. Defaults to False.
weights – weights to use in for sampling transforms. Will be normalized to 1. Default: None (uniform).
lazy – whether to enable Lazy Resampling for lazy transforms. If False, transforms will be carried out on a transform by transform basis. If True, all lazy transforms will be executed by accumulating changes and resampling as few times as possible. If lazy is None, Compose will perform lazy execution on lazy transforms that have their lazy property set to True.
overrides – this optional parameter allows you to specify a dictionary of parameters that should be overridden when executing a pipeline. These each parameter that is compatible with a given transform is then applied to that transform before it is executed. Note that overrides are currently only applied when Lazy Resampling is enabled for the pipeline or a given transform. If lazy is False they are ignored. Currently supported args are: {
"mode","padding_mode","dtype","align_corners","resample_mode",device}.
Functionals#
Crop and Pad (functional)#
A collection of “functional” transforms for spatial operations.
- monai.transforms.croppad.functional.crop_func(img, slices, lazy, transform_info)[source]#
Functional implementation of cropping a MetaTensor. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img (
Tensor) – data to be transformed, assuming img is channel-first and cropping doesn’t apply to the channel dim.slices (
tuple[slice, …]) – the crop slices computed based on specified center & size or start & end or slices.lazy (
bool) – a flag indicating whether the operation should be performed in a lazy fashion or not.transform_info (
dict) – a dictionary with the relevant information pertaining to an applied transform.
- Return type:
Tensor
- monai.transforms.croppad.functional.crop_or_pad_nd(img, translation_mat, spatial_size, mode, **kwargs)[source]#
Crop or pad using the translation matrix and spatial size. The translation coefficients are rounded to the nearest integers. For a more generic implementation, please see
monai.transforms.SpatialResample.- Parameters:
img (
Tensor) – data to be transformed, assuming img is channel-first and padding doesn’t apply to the channel dim.translation_mat – the translation matrix to be applied to the image. A translation matrix generated by, for example,
monai.transforms.utils.create_translate(). The translation coefficients are rounded to the nearest integers.spatial_size (
tuple[int, …]) – the spatial size of the output image.mode (
str) – the padding mode.kwargs – other arguments for the np.pad or torch.pad function.
- monai.transforms.croppad.functional.pad_func(img, to_pad, transform_info, mode=constant, lazy=False, **kwargs)[source]#
Functional implementation of padding a MetaTensor. This function operates eagerly or lazily according to
lazy(defaultFalse).torch.nn.functional.pad is used unless the mode or kwargs are not available in torch, in which case np.pad will be used.
- Parameters:
img (
Tensor) – data to be transformed, assuming img is channel-first and padding doesn’t apply to the channel dim.to_pad (
tuple[tuple[int,int]]) – the amount to be padded in each dimension [(low_H, high_H), (low_W, high_W), …]. note that it including channel dimension.transform_info (
dict) – a dictionary with the relevant information pertaining to an applied transform.mode (
str) – available modes: (Numpy) {"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/stable/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmllazy (
bool) – a flag indicating whether the operation should be performed in a lazy fashion or not.transform_info – a dictionary with the relevant information pertaining to an applied transform.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- Return type:
Tensor
- monai.transforms.croppad.functional.pad_nd(img, to_pad, mode=constant, **kwargs)[source]#
Pad img for a given an amount of padding in each dimension.
torch.nn.functional.pad is used unless the mode or kwargs are not available in torch, in which case np.pad will be used.
- Parameters:
img (~NdarrayTensor) – data to be transformed, assuming img is channel-first and padding doesn’t apply to the channel dim.
to_pad (
list[tuple[int,int]]) – the amount to be padded in each dimension [(low_H, high_H), (low_W, high_W), …]. default to self.to_pad.mode (
str) – available modes: (Numpy) {"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/stable/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlkwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- Return type:
~NdarrayTensor
Spatial (functional)#
A collection of “functional” transforms for spatial operations.
- monai.transforms.spatial.functional.affine_func(img, affine, grid, resampler, sp_size, mode, padding_mode, do_resampling, image_only, lazy, transform_info)[source]#
Functional implementation of affine. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img – data to be changed, assuming img is channel-first.
affine – the affine transformation to be applied, it can be a 3x3 or 4x4 matrix. This should be defined for the voxel space spatial centers (
float(size - 1)/2).grid – used in non-lazy mode to pre-compute the grid to do the resampling.
resampler – the resampler function, see also:
monai.transforms.Resample.sp_size – output image spatial size.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldo_resampling – whether to do the resampling, this is a flag for the use case of updating metadata but skipping the actual (potentially heavy) resampling operation.
image_only – if True return only the image volume, otherwise return (image, affine).
lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
- monai.transforms.spatial.functional.flip(img, sp_axes, lazy, transform_info)[source]#
Functional implementation of flip. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img – data to be changed, assuming img is channel-first.
sp_axes – spatial axes along which to flip over. If None, will flip over all of the axes of the input array. If axis is negative it counts from the last to the first axis. If axis is a tuple of ints, flipping is performed on all of the axes specified in the tuple.
lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
- monai.transforms.spatial.functional.orientation(img, original_affine, spatial_ornt, lazy, transform_info)[source]#
Functional implementation of changing the input image’s orientation into the specified based on spatial_ornt. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img – data to be changed, assuming img is channel-first.
original_affine – original affine of the input image.
spatial_ornt – orientations of the spatial axes, see also https://nipy.org/nibabel/reference/nibabel.orientations.html
lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
- Return type:
Tensor
- monai.transforms.spatial.functional.resize(img, out_size, mode, align_corners, dtype, input_ndim, anti_aliasing, anti_aliasing_sigma, lazy, transform_info)[source]#
Functional implementation of resize. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img – data to be changed, assuming img is channel-first.
out_size – expected shape of spatial dimensions after resize operation.
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’.
dtype – data type for resampling computation. If None, use the data type of input data.
input_ndim – number of spatial dimensions.
anti_aliasing – whether to apply a Gaussian filter to smooth the image prior to downsampling. It is crucial to filter when downsampling the image to avoid aliasing artifacts. See also
skimage.transform.resizeanti_aliasing_sigma – {float, tuple of floats}, optional Standard deviation for Gaussian filtering used when anti-aliasing.
lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
- monai.transforms.spatial.functional.rotate(img, angle, output_shape, mode, padding_mode, align_corners, dtype, lazy, transform_info)[source]#
Functional implementation of rotate. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img – data to be changed, assuming img is channel-first.
angle – Rotation angle(s) in radians. should a float for 2D, three floats for 3D.
output_shape – output shape of the rotated data.
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – data type for resampling computation. If None, use the data type of input data. To be compatible with other modules, the output data type is always
float32.lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
- monai.transforms.spatial.functional.rotate90(img, axes, k, lazy, transform_info)[source]#
Functional implementation of rotate90. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img – data to be changed, assuming img is channel-first.
axes – 2 int numbers, defines the plane to rotate with 2 spatial axes. If axis is negative it counts from the last to the first axis.
k – number of times to rotate by 90 degrees.
lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
- monai.transforms.spatial.functional.spatial_resample(img, dst_affine, spatial_size, mode, padding_mode, align_corners, dtype_pt, lazy, transform_info)[source]#
Functional implementation of resampling the input image to the specified
dst_affinematrix andspatial_size. This function operates eagerly or lazily according tolazy(defaultFalse).- Parameters:
img – data to be resampled, assuming img is channel-first.
dst_affine – target affine matrix, if None, use the input affine matrix, effectively no resampling.
spatial_size – output spatial size, if the component is
-1, use the corresponding input spatial size.mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – Geometrically, we consider the pixels of the input as squares rather than points. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype_pt – data dtype for resampling computation.
lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
- Return type:
Tensor
- monai.transforms.spatial.functional.zoom(img, scale_factor, keep_size, mode, padding_mode, align_corners, dtype, lazy, transform_info)[source]#
Functional implementation of zoom. This function operates eagerly or lazily according to
lazy(defaultFalse).- Parameters:
img – data to be changed, assuming img is channel-first.
scale_factor – The zoom factor along the spatial axes. If a float, zoom is the same for each spatial axis. If a sequence, zoom should contain one value for each spatial axis.
keep_size – Whether keep original size (padding/slicing if needed).
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – data type for resampling computation. If None, use the data type of input data. To be compatible with other modules, the output data type is always
float32.lazy – a flag that indicates whether the operation should be performed lazily or not
transform_info – a dictionary with the relevant information pertaining to an applied transform.
Vanilla Transforms#
Crop and Pad#
PadListDataCollate#
- class monai.transforms.PadListDataCollate(method=symmetric, mode=constant, **kwargs)[source]#
Same as MONAI’s
list_data_collate, except any tensors are centrally padded to match the shape of the biggest tensor in each dimension. This transform is useful if some of the applied transforms generate batch data of different sizes.This can be used on both list and dictionary data. Note that in the case of the dictionary data, it may add the transform information to the list of invertible transforms if input batch have different spatial shape, so need to call static method: inverse before inverting other transforms.
Note that normally, a user won’t explicitly use the __call__ method. Rather this would be passed to the DataLoader. This means that __call__ handles data as it comes out of a DataLoader, containing batch dimension. However, the inverse operates on dictionaries containing images of shape C,H,W,[D]. This asymmetry is necessary so that we can pass the inverse through multiprocessing.
- Parameters:
method (
str) – padding method (seemonai.transforms.SpatialPad)mode (
str) – padding mode (seemonai.transforms.SpatialPad)kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
Pad#
- class monai.transforms.Pad(to_pad=None, mode=constant, lazy=False, **kwargs)[source]#
Perform padding for a given an amount of padding in each dimension.
torch.nn.functional.pad is used unless the mode or kwargs are not available in torch, in which case np.pad will be used.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
to_pad – the amount to pad in each dimension (including the channel) [(low_H, high_H), (low_W, high_W), …]. if None, must provide in the __call__ at runtime.
mode – available modes: (Numpy) {
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html requires pytorch >= 1.10 for best compatibility.lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- __call__(img, to_pad=None, mode=None, lazy=None, **kwargs)[source]#
- Parameters:
img – data to be transformed, assuming img is channel-first and padding doesn’t apply to the channel dim.
to_pad – the amount to be padded in each dimension [(low_H, high_H), (low_W, high_W), …]. default to self.to_pad.
mode – available modes: (Numpy) {
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmllazy – a flag to override the lazy behaviour for this call, if set. Defaults to None.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- compute_pad_width(spatial_shape)[source]#
dynamically compute the pad width according to the spatial shape. the output is the amount of padding for all dimensions including the channel.
- Parameters:
spatial_shape (
Sequence[int]) – spatial shape of the original image.- Return type:
tuple[tuple[int,int]]
SpatialPad#
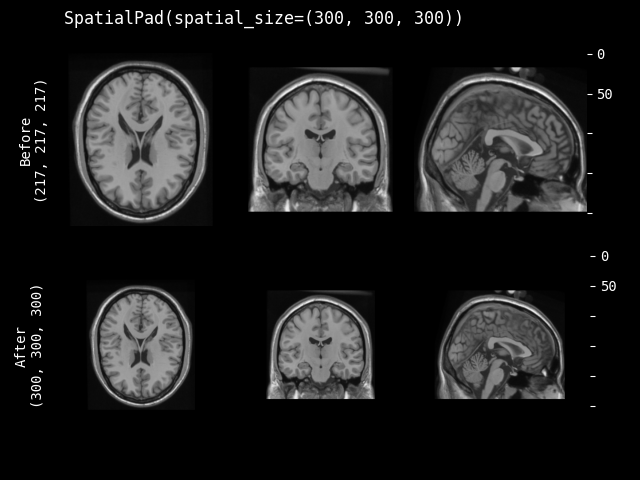
- class monai.transforms.SpatialPad(spatial_size, method=symmetric, mode=constant, lazy=False, **kwargs)[source]#
Performs padding to the data, symmetric for all sides or all on one side for each dimension.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_size – the spatial size of output data after padding, if a dimension of the input data size is larger than the pad size, will not pad that dimension. If its components have non-positive values, the corresponding size of input image will be used (no padding). for example: if the spatial size of input data is [30, 30, 30] and spatial_size=[32, 25, -1], the spatial size of output data will be [32, 30, 30].
method – {
"symmetric","end"} Pad image symmetrically on every side or only pad at the end sides. Defaults to"symmetric".mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmllazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
BorderPad#
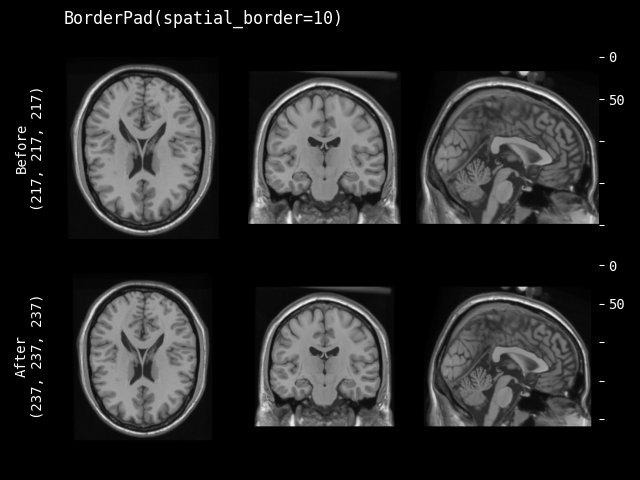
- class monai.transforms.BorderPad(spatial_border, mode=constant, lazy=False, **kwargs)[source]#
Pad the input data by adding specified borders to every dimension.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_border –
specified size for every spatial border. Any -ve values will be set to 0. It can be 3 shapes:
single int number, pad all the borders with the same size.
length equals the length of image shape, pad every spatial dimension separately. for example, image shape(CHW) is [1, 4, 4], spatial_border is [2, 1], pad every border of H dim with 2, pad every border of W dim with 1, result shape is [1, 8, 6].
length equals 2 x (length of image shape), pad every border of every dimension separately. for example, image shape(CHW) is [1, 4, 4], spatial_border is [1, 2, 3, 4], pad top of H dim with 1, pad bottom of H dim with 2, pad left of W dim with 3, pad right of W dim with 4. the result shape is [1, 7, 11].
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmllazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- compute_pad_width(spatial_shape)[source]#
dynamically compute the pad width according to the spatial shape. the output is the amount of padding for all dimensions including the channel.
- Parameters:
spatial_shape (
Sequence[int]) – spatial shape of the original image.- Return type:
tuple[tuple[int,int]]
DivisiblePad#
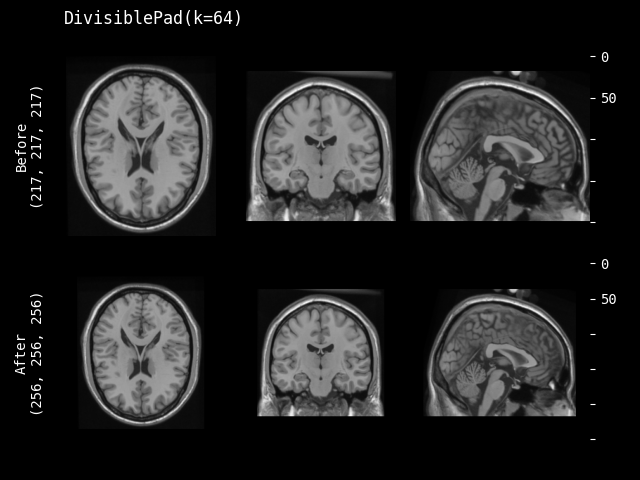
- class monai.transforms.DivisiblePad(k, mode=constant, method=symmetric, lazy=False, **kwargs)[source]#
Pad the input data, so that the spatial sizes are divisible by k.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __init__(k, mode=constant, method=symmetric, lazy=False, **kwargs)[source]#
- Parameters:
k – the target k for each spatial dimension. if k is negative or 0, the original size is preserved. if k is an int, the same k be applied to all the input spatial dimensions.
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlmethod – {
"symmetric","end"} Pad image symmetrically on every side or only pad at the end sides. Defaults to"symmetric".lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
See also
monai.transforms.SpatialPad
- compute_pad_width(spatial_shape)[source]#
dynamically compute the pad width according to the spatial shape. the output is the amount of padding for all dimensions including the channel.
- Parameters:
spatial_shape (
Sequence[int]) – spatial shape of the original image.- Return type:
tuple[tuple[int,int]]
Crop#
- class monai.transforms.Crop(lazy=False)[source]#
Perform crop operations on the input image.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(img, slices, lazy=None)[source]#
Apply the transform to img, assuming img is channel-first and slicing doesn’t apply to the channel dim.
- static compute_slices(roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None)[source]#
Compute the crop slices based on specified center & size or start & end or slices.
- Parameters:
roi_center – voxel coordinates for center of the crop ROI.
roi_size – size of the crop ROI, if a dimension of ROI size is larger than image size, will not crop that dimension of the image.
roi_start – voxel coordinates for start of the crop ROI.
roi_end – voxel coordinates for end of the crop ROI, if a coordinate is out of image, use the end coordinate of image.
roi_slices – list of slices for each of the spatial dimensions.
SpatialCrop#
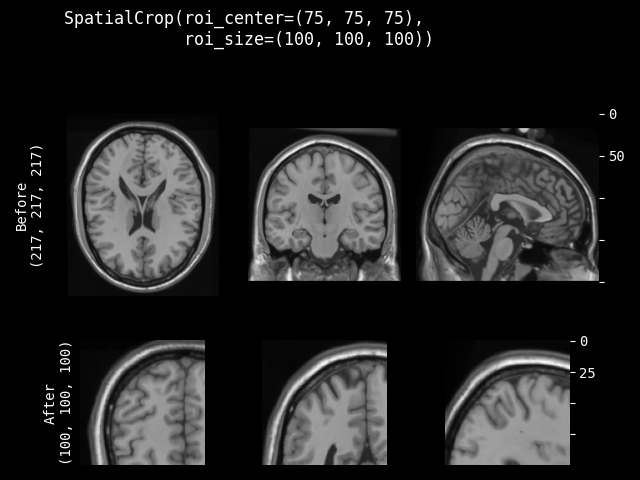
- class monai.transforms.SpatialCrop(roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None, lazy=False)[source]#
General purpose cropper to produce sub-volume region of interest (ROI). If a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape. It can support to crop ND spatial (channel-first) data.
- The cropped region can be parameterised in various ways:
a list of slices for each spatial dimension (allows for use of negative indexing and None)
a spatial center and size
the start and end coordinates of the ROI
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, lazy=None)[source]#
Apply the transform to img, assuming img is channel-first and slicing doesn’t apply to the channel dim.
- __init__(roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None, lazy=False)[source]#
- Parameters:
roi_center – voxel coordinates for center of the crop ROI.
roi_size – size of the crop ROI, if a dimension of ROI size is larger than image size, will not crop that dimension of the image.
roi_start – voxel coordinates for start of the crop ROI.
roi_end – voxel coordinates for end of the crop ROI, if a coordinate is out of image, use the end coordinate of image.
roi_slices – list of slices for each of the spatial dimensions.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
CenterSpatialCrop#
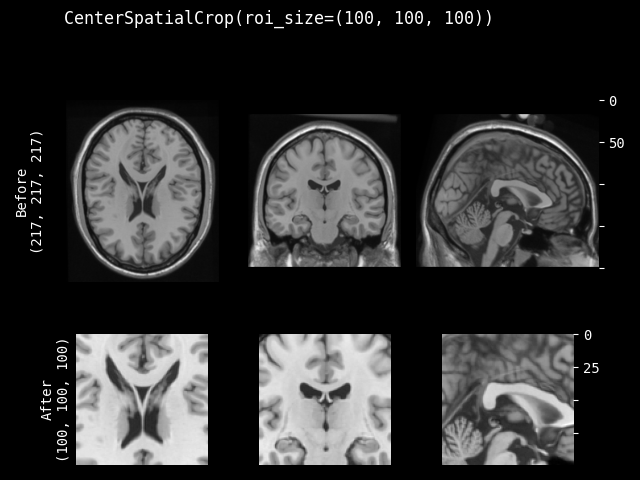
- class monai.transforms.CenterSpatialCrop(roi_size, lazy=False)[source]#
Crop at the center of image with specified ROI size. If a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
roi_size – the spatial size of the crop region e.g. [224,224,128] if a dimension of ROI size is larger than image size, will not crop that dimension of the image. If its components have non-positive values, the corresponding size of input image will be used. for example: if the spatial size of input data is [40, 40, 40] and roi_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(img, lazy=None)[source]#
Apply the transform to img, assuming img is channel-first and slicing doesn’t apply to the channel dim.
- compute_slices(spatial_size)[source]#
Compute the crop slices based on specified center & size or start & end or slices.
- Parameters:
roi_center – voxel coordinates for center of the crop ROI.
roi_size – size of the crop ROI, if a dimension of ROI size is larger than image size, will not crop that dimension of the image.
roi_start – voxel coordinates for start of the crop ROI.
roi_end – voxel coordinates for end of the crop ROI, if a coordinate is out of image, use the end coordinate of image.
roi_slices – list of slices for each of the spatial dimensions.
- Return type:
tuple[slice]
RandSpatialCrop#
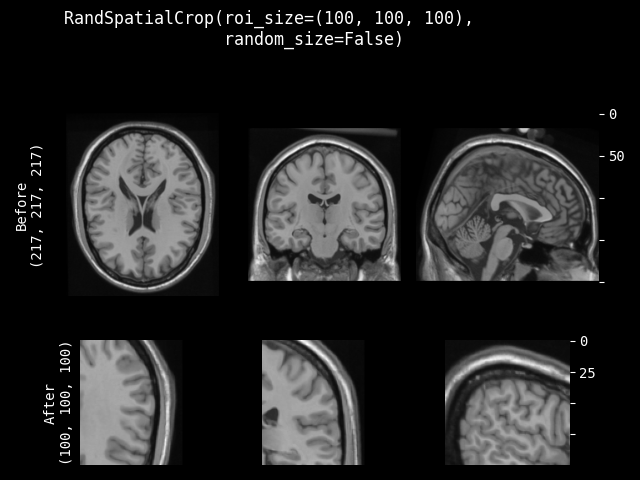
- class monai.transforms.RandSpatialCrop(roi_size, max_roi_size=None, random_center=True, random_size=False, lazy=False)[source]#
Crop image with random size or specific size ROI. It can crop at a random position as center or at the image center. And allows to set the minimum and maximum size to limit the randomly generated ROI.
Note: even random_size=False, if a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
roi_size – if random_size is True, it specifies the minimum crop region. if random_size is False, it specifies the expected ROI size to crop. e.g. [224, 224, 128] if a dimension of ROI size is larger than image size, will not crop that dimension of the image. If its components have non-positive values, the corresponding size of input image will be used. for example: if the spatial size of input data is [40, 40, 40] and roi_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
max_roi_size – if random_size is True and roi_size specifies the min crop region size, max_roi_size can specify the max crop region size. if None, defaults to the input image size. if its components have non-positive values, the corresponding size of input image will be used.
random_center – crop at random position as center or the image center.
random_size – crop with random size or specific size ROI. if True, the actual size is sampled from randint(roi_size, max_roi_size + 1).
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(img, randomize=True, lazy=None)[source]#
Apply the transform to img, assuming img is channel-first and slicing doesn’t apply to the channel dim.
- randomize(img_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
RandSpatialCropSamples#
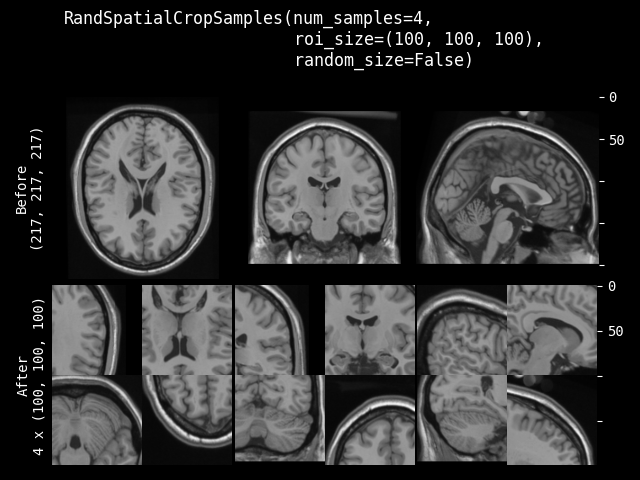
- class monai.transforms.RandSpatialCropSamples(roi_size, num_samples, max_roi_size=None, random_center=True, random_size=False, lazy=False)[source]#
Crop image with random size or specific size ROI to generate a list of N samples. It can crop at a random position as center or at the image center. And allows to set the minimum size to limit the randomly generated ROI. It will return a list of cropped images.
Note: even random_size=False, if a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
roi_size – if random_size is True, it specifies the minimum crop region. if random_size is False, it specifies the expected ROI size to crop. e.g. [224, 224, 128] if a dimension of ROI size is larger than image size, will not crop that dimension of the image. If its components have non-positive values, the corresponding size of input image will be used. for example: if the spatial size of input data is [40, 40, 40] and roi_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
num_samples – number of samples (crop regions) to take in the returned list.
max_roi_size – if random_size is True and roi_size specifies the min crop region size, max_roi_size can specify the max crop region size. if None, defaults to the input image size. if its components have non-positive values, the corresponding size of input image will be used.
random_center – crop at random position as center or the image center.
random_size – crop with random size or specific size ROI. The actual size is sampled from randint(roi_size, img_size).
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- Raises:
ValueError – When
num_samplesis nonpositive.
- __call__(img, lazy=None)[source]#
Apply the transform to img, assuming img is channel-first and cropping doesn’t change the channel dim.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
CropForeground#
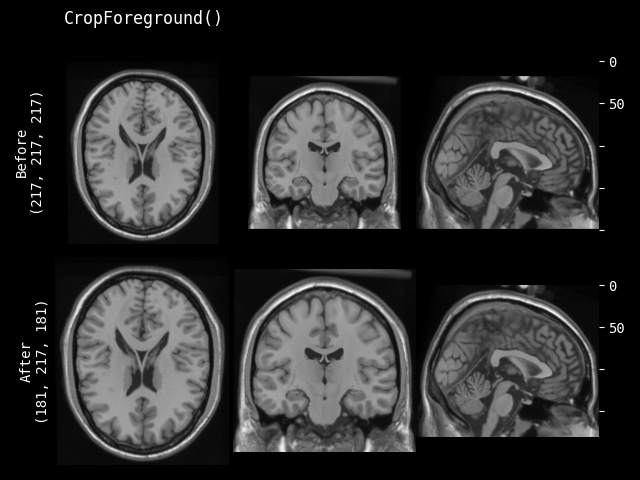
- class monai.transforms.CropForeground(select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, return_coords=False, k_divisible=1, mode=constant, lazy=False, **pad_kwargs)[source]#
Crop an image using a bounding box. The bounding box is generated by selecting foreground using select_fn at channels channel_indices. margin is added in each spatial dimension of the bounding box. The typical usage is to help training and evaluation if the valid part is small in the whole medical image. Users can define arbitrary function to select expected foreground from the whole image or specified channels. And it can also add margin to every dim of the bounding box of foreground object. For example:
image = np.array( [[[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [0, 1, 3, 2, 0], [0, 1, 2, 1, 0], [0, 0, 0, 0, 0]]]) # 1x5x5, single channel 5x5 image def threshold_at_one(x): # threshold at 1 return x > 1 cropper = CropForeground(select_fn=threshold_at_one, margin=0) print(cropper(image)) [[[2, 1], [3, 2], [2, 1]]]
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, mode=None, lazy=None, **pad_kwargs)[source]#
Apply the transform to img, assuming img is channel-first and slicing doesn’t change the channel dim.
- __init__(select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, return_coords=False, k_divisible=1, mode=constant, lazy=False, **pad_kwargs)[source]#
- Parameters:
select_fn – function to select expected foreground, default is to select values > 0.
channel_indices – if defined, select foreground only on the specified channels of image. if None, select foreground on the whole image.
margin – add margin value to spatial dims of the bounding box, if only 1 value provided, use it for all dims.
allow_smaller – when computing box size with margin, whether to allow the image edges to be smaller than the final box edges. If False, part of a padded output box might be outside of the original image, if True, the image edges will be used as the box edges. Default to True.
return_coords – whether return the coordinates of spatial bounding box for foreground.
k_divisible – make each spatial dimension to be divisible by k, default to 1. if k_divisible is an int, the same k be applied to all the input spatial dimensions.
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmllazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- compute_bounding_box(img)[source]#
Compute the start points and end points of bounding box to crop. And adjust bounding box coords to be divisible by k.
- Return type:
tuple[ndarray,ndarray]
- crop_pad(img, box_start, box_end, mode=None, lazy=False, **pad_kwargs)[source]#
Crop and pad based on the bounding box.
- inverse(img)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
RandWeightedCrop#
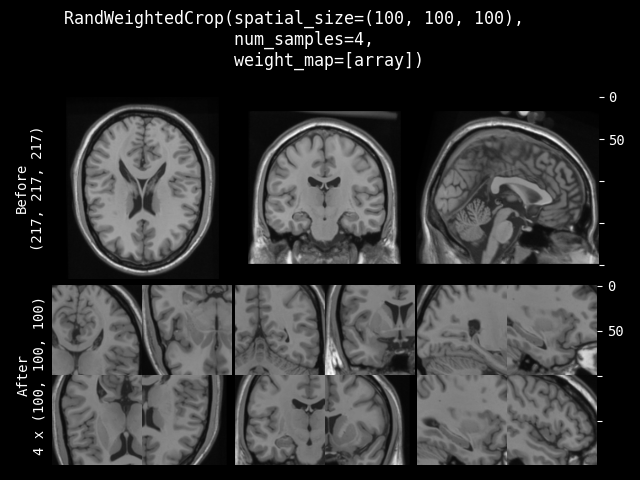
- class monai.transforms.RandWeightedCrop(spatial_size, num_samples=1, weight_map=None, lazy=False)[source]#
Samples a list of num_samples image patches according to the provided weight_map.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_size – the spatial size of the image patch e.g. [224, 224, 128]. If its components have non-positive values, the corresponding size of img will be used.
num_samples – number of samples (image patches) to take in the returned list.
weight_map – weight map used to generate patch samples. The weights must be non-negative. Each element denotes a sampling weight of the spatial location. 0 indicates no sampling. It should be a single-channel array in shape, for example, (1, spatial_dim_0, spatial_dim_1, …).
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(img, weight_map=None, randomize=True, lazy=None)[source]#
- Parameters:
img – input image to sample patches from. assuming img is a channel-first array.
weight_map – weight map used to generate patch samples. The weights must be non-negative. Each element denotes a sampling weight of the spatial location. 0 indicates no sampling. It should be a single-channel array in shape, for example, (1, spatial_dim_0, spatial_dim_1, …)
randomize – whether to execute random operations, default to True.
lazy – a flag to override the lazy behaviour for this call, if set. Defaults to None.
- Returns:
A list of image patches
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(weight_map)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
RandCropByPosNegLabel#
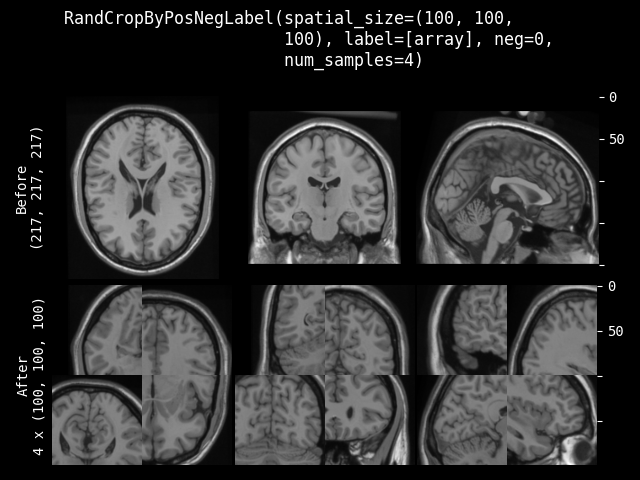
- class monai.transforms.RandCropByPosNegLabel(spatial_size, label=None, pos=1.0, neg=1.0, num_samples=1, image=None, image_threshold=0.0, fg_indices=None, bg_indices=None, allow_smaller=False, lazy=False)[source]#
Crop random fixed sized regions with the center being a foreground or background voxel based on the Pos Neg Ratio. And will return a list of arrays for all the cropped images. For example, crop two (3 x 3) arrays from (5 x 5) array with pos/neg=1:
[[[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [[0, 1, 2], [[2, 1, 0], [0, 1, 3, 0, 0], --> [0, 1, 3], [3, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0]] [0, 0, 0]] [0, 0, 0, 0, 0]]]
If a dimension of the expected spatial size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than expected size, and the cropped results of several images may not have exactly same shape. And if the crop ROI is partly out of the image, will automatically adjust the crop center to ensure the valid crop ROI.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_size – the spatial size of the crop region e.g. [224, 224, 128]. if a dimension of ROI size is larger than image size, will not crop that dimension of the image. if its components have non-positive values, the corresponding size of label will be used. for example: if the spatial size of input data is [40, 40, 40] and spatial_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
label – the label image that is used for finding foreground/background, if None, must set at self.__call__. Non-zero indicates foreground, zero indicates background.
pos – used with neg together to calculate the ratio
pos / (pos + neg)for the probability to pick a foreground voxel as a center rather than a background voxel.neg – used with pos together to calculate the ratio
pos / (pos + neg)for the probability to pick a foreground voxel as a center rather than a background voxel.num_samples – number of samples (crop regions) to take in each list.
image – optional image data to help select valid area, can be same as img or another image array. if not None, use
label == 0 & image > image_thresholdto select the negative sample (background) center. So the crop center will only come from the valid image areas.image_threshold – if enabled image, use
image > image_thresholdto determine the valid image content areas.fg_indices – if provided pre-computed foreground indices of label, will ignore above image and image_threshold, and randomly select crop centers based on them, need to provide fg_indices and bg_indices together, expect to be 1 dim array of spatial indices after flattening. a typical usage is to call FgBgToIndices transform first and cache the results.
bg_indices – if provided pre-computed background indices of label, will ignore above image and image_threshold, and randomly select crop centers based on them, need to provide fg_indices and bg_indices together, expect to be 1 dim array of spatial indices after flattening. a typical usage is to call FgBgToIndices transform first and cache the results.
allow_smaller – if False, an exception will be raised if the image is smaller than the requested ROI in any dimension. If True, any smaller dimensions will be set to match the cropped size (i.e., no cropping in that dimension).
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- Raises:
ValueError – When
posornegare negative.ValueError – When
pos=0andneg=0. Incompatible values.
- __call__(img, label=None, image=None, fg_indices=None, bg_indices=None, randomize=True, lazy=None)[source]#
- Parameters:
img – input data to crop samples from based on the pos/neg ratio of label and image. Assumes img is a channel-first array.
label – the label image that is used for finding foreground/background, if None, use self.label.
image – optional image data to help select valid area, can be same as img or another image array. use
label == 0 & image > image_thresholdto select the negative sample(background) center. so the crop center will only exist on valid image area. if None, use self.image.fg_indices – foreground indices to randomly select crop centers, need to provide fg_indices and bg_indices together.
bg_indices – background indices to randomly select crop centers, need to provide fg_indices and bg_indices together.
randomize – whether to execute the random operations, default to True.
lazy – a flag to override the lazy behaviour for this call, if set. Defaults to None.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(label=None, fg_indices=None, bg_indices=None, image=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
RandCropByLabelClasses#
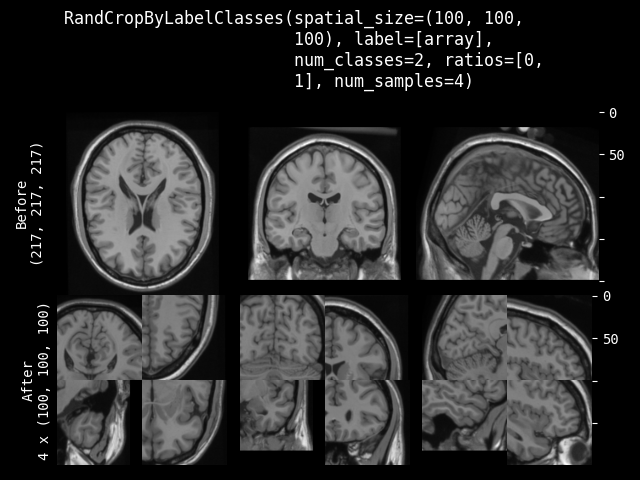
- class monai.transforms.RandCropByLabelClasses(spatial_size, ratios=None, label=None, num_classes=None, num_samples=1, image=None, image_threshold=0.0, indices=None, allow_smaller=False, warn=True, max_samples_per_class=None, lazy=False)[source]#
Crop random fixed sized regions with the center being a class based on the specified ratios of every class. The label data can be One-Hot format array or Argmax data. And will return a list of arrays for all the cropped images. For example, crop two (3 x 3) arrays from (5 x 5) array with ratios=[1, 2, 3, 1]:
image = np.array([ [[0.0, 0.3, 0.4, 0.2, 0.0], [0.0, 0.1, 0.2, 0.1, 0.4], [0.0, 0.3, 0.5, 0.2, 0.0], [0.1, 0.2, 0.1, 0.1, 0.0], [0.0, 0.1, 0.2, 0.1, 0.0]] ]) label = np.array([ [[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [0, 1, 3, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]] ]) cropper = RandCropByLabelClasses( spatial_size=[3, 3], ratios=[1, 2, 3, 1], num_classes=4, num_samples=2, ) label_samples = cropper(img=label, label=label, image=image) The 2 randomly cropped samples of `label` can be: [[0, 1, 2], [[0, 0, 0], [0, 1, 3], [1, 2, 1], [0, 0, 0]] [1, 3, 0]]If a dimension of the expected spatial size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than expected size, and the cropped results of several images may not have exactly same shape. And if the crop ROI is partly out of the image, will automatically adjust the crop center to ensure the valid crop ROI.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_size – the spatial size of the crop region e.g. [224, 224, 128]. if a dimension of ROI size is larger than image size, will not crop that dimension of the image. if its components have non-positive values, the corresponding size of label will be used. for example: if the spatial size of input data is [40, 40, 40] and spatial_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
ratios – specified ratios of every class in the label to generate crop centers, including background class. if None, every class will have the same ratio to generate crop centers.
label – the label image that is used for finding every class, if None, must set at self.__call__.
num_classes – number of classes for argmax label, not necessary for One-Hot label.
num_samples – number of samples (crop regions) to take in each list.
image – if image is not None, only return the indices of every class that are within the valid region of the image (
image > image_threshold).image_threshold – if enabled image, use
image > image_thresholdto determine the valid image content area and select class indices only in this area.indices – if provided pre-computed indices of every class, will ignore above image and image_threshold, and randomly select crop centers based on them, expect to be 1 dim array of spatial indices after flattening. a typical usage is to call ClassesToIndices transform first and cache the results for better performance.
allow_smaller – if False, an exception will be raised if the image is smaller than the requested ROI in any dimension. If True, any smaller dimensions will remain unchanged.
warn – if True prints a warning if a class is not present in the label.
max_samples_per_class – maximum length of indices to sample in each class to reduce memory consumption. Default is None, no subsampling.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(img, label=None, image=None, indices=None, randomize=True, lazy=None)[source]#
- Parameters:
img – input data to crop samples from based on the ratios of every class, assumes img is a channel-first array.
label – the label image that is used for finding indices of every class, if None, use self.label.
image – optional image data to help select valid area, can be same as img or another image array. use
image > image_thresholdto select the centers only in valid region. if None, use self.image.indices – list of indices for every class in the image, used to randomly select crop centers.
randomize – whether to execute the random operations, default to True.
lazy – a flag to override the lazy behaviour for this call, if set. Defaults to None.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(label=None, indices=None, image=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
ResizeWithPadOrCrop#
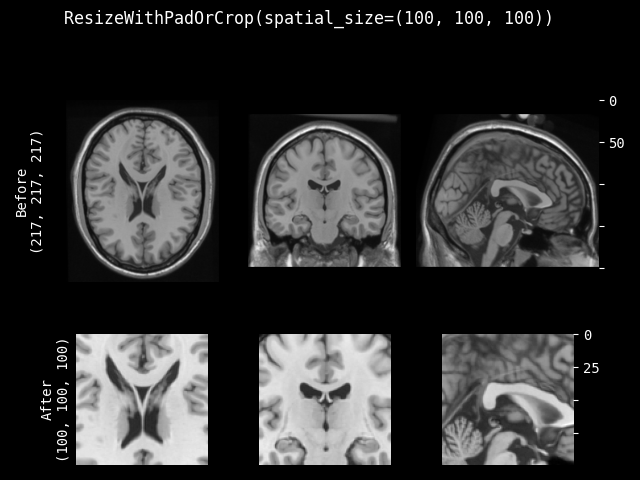
- class monai.transforms.ResizeWithPadOrCrop(spatial_size, method=symmetric, mode=constant, lazy=False, **pad_kwargs)[source]#
Resize an image to a target spatial size by either centrally cropping the image or padding it evenly with a user-specified mode. When the dimension is smaller than the target size, do symmetric padding along that dim. When the dimension is larger than the target size, do central cropping along that dim.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_size – the spatial size of output data after padding or crop. If has non-positive values, the corresponding size of input image will be used (no padding).
method – {
"symmetric","end"} Pad image symmetrically on every side or only pad at the end sides. Defaults to"symmetric".mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlpad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(img, mode=None, lazy=None, **pad_kwargs)[source]#
- Parameters:
img – data to pad or crop, assuming img is channel-first and padding or cropping doesn’t apply to the channel dim.
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmllazy – a flag to override the lazy behaviour for this call, if set. Defaults to None.
pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- inverse(img)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
BoundingRect#
- class monai.transforms.BoundingRect(select_fn=<function is_positive>)[source]#
Compute coordinates of axis-aligned bounding rectangles from input image img. The output format of the coordinates is (shape is [channel, 2 * spatial dims]):
- [[1st_spatial_dim_start, 1st_spatial_dim_end,
2nd_spatial_dim_start, 2nd_spatial_dim_end, …, Nth_spatial_dim_start, Nth_spatial_dim_end],
…
[1st_spatial_dim_start, 1st_spatial_dim_end, 2nd_spatial_dim_start, 2nd_spatial_dim_end, …, Nth_spatial_dim_start, Nth_spatial_dim_end]]
The bounding boxes edges are aligned with the input image edges. This function returns [0, 0, …] if there’s no positive intensity.
- Parameters:
select_fn (
Callable) – function to select expected foreground, default is to select values > 0.
- __call__(img)[source]#
See also:
monai.transforms.utils.generate_spatial_bounding_box.- Return type:
ndarray
RandScaleCrop#
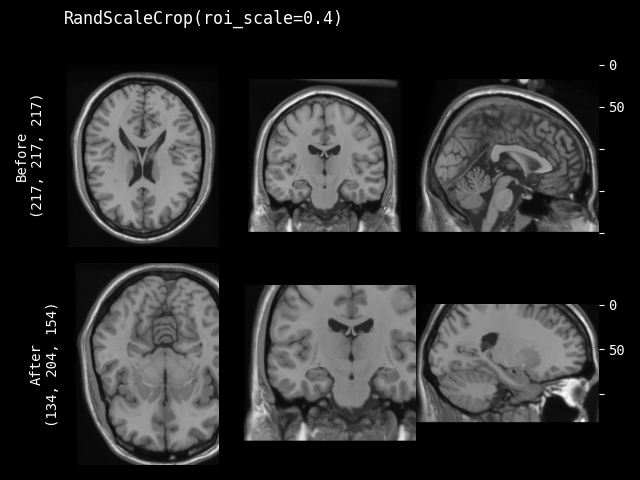
- class monai.transforms.RandScaleCrop(roi_scale, max_roi_scale=None, random_center=True, random_size=False, lazy=False)[source]#
Subclass of
monai.transforms.RandSpatialCrop. Crop image with random size or specific size ROI. It can crop at a random position as center or at the image center. And allows to set the minimum and maximum scale of image size to limit the randomly generated ROI.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
roi_scale – if random_size is True, it specifies the minimum crop size: roi_scale * image spatial size. if random_size is False, it specifies the expected scale of image size to crop. e.g. [0.3, 0.4, 0.5]. If its components have non-positive values, will use 1.0 instead, which means the input image size.
max_roi_scale – if random_size is True and roi_scale specifies the min crop region size, max_roi_scale can specify the max crop region size: max_roi_scale * image spatial size. if None, defaults to the input image size. if its components have non-positive values, will use 1.0 instead, which means the input image size.
random_center – crop at random position as center or the image center.
random_size – crop with random size or specified size ROI by roi_scale * image spatial size. if True, the actual size is sampled from randint(roi_scale * image spatial size, max_roi_scale * image spatial size + 1).
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(img, randomize=True, lazy=None)[source]#
Apply the transform to img, assuming img is channel-first and slicing doesn’t apply to the channel dim.
- randomize(img_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
CenterScaleCrop#
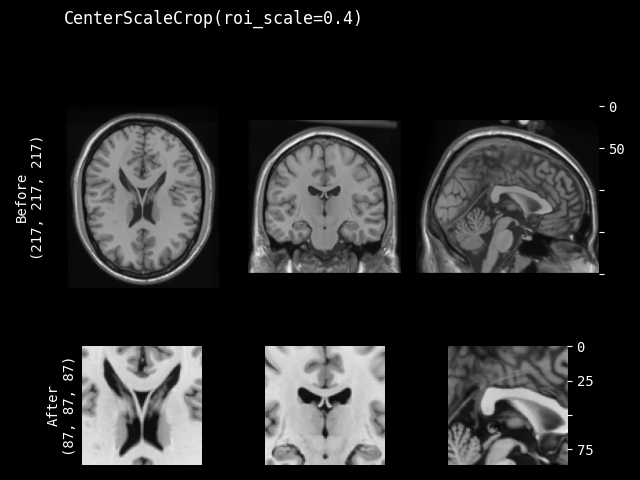
- class monai.transforms.CenterScaleCrop(roi_scale, lazy=False)[source]#
Crop at the center of image with specified scale of ROI size.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
roi_scale – specifies the expected scale of image size to crop. e.g. [0.3, 0.4, 0.5] or a number for all dims. If its components have non-positive values, will use 1.0 instead, which means the input image size.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
Intensity#
RandGaussianNoise#
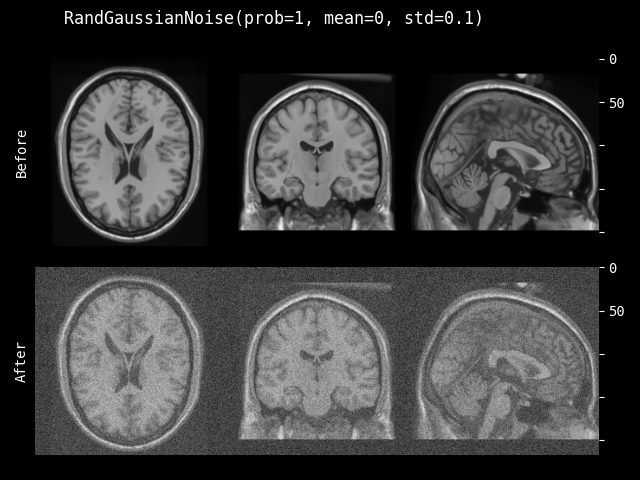
- class monai.transforms.RandGaussianNoise(prob=0.1, mean=0.0, std=0.1, dtype=<class 'numpy.float32'>, sample_std=True)[source]#
Add Gaussian noise to image.
- Parameters:
prob (
float) – Probability to add Gaussian noise.mean (
float) – Mean or “centre” of the distribution.std (
float) – Standard deviation (spread) of distribution.dtype (
Union[dtype,type,str,None]) – output data type, if None, same as input image. defaults to float32.sample_std (
bool) – If True, sample the spread of the Gaussian distribution uniformly from 0 to std.
- randomize(img, mean=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
ShiftIntensity#
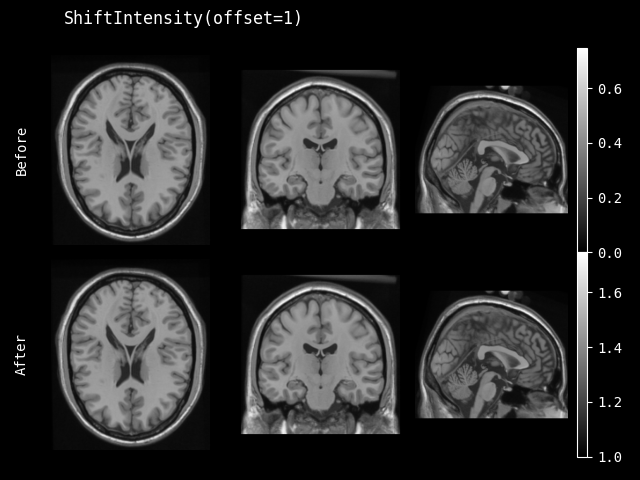
- class monai.transforms.ShiftIntensity(offset, safe=False)[source]#
Shift intensity uniformly for the entire image with specified offset.
- Parameters:
offset (
float) – offset value to shift the intensity of image.safe (
bool) – if True, then do safe dtype convert when intensity overflow. default to False. E.g., [256, -12] -> [array(0), array(244)]. If True, then [256, -12] -> [array(255), array(0)].
RandShiftIntensity#
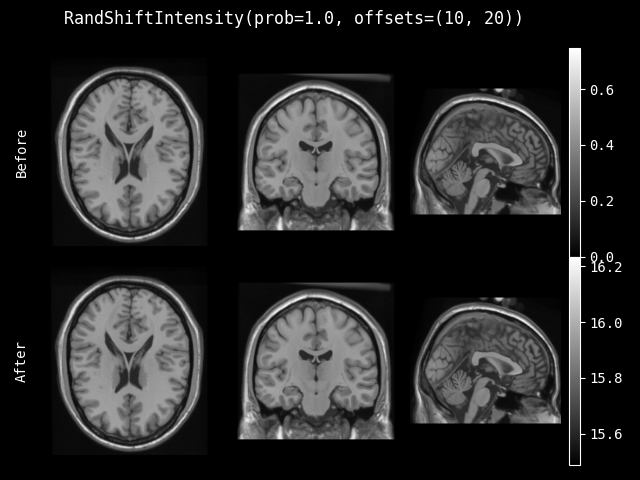
- class monai.transforms.RandShiftIntensity(offsets, safe=False, prob=0.1, channel_wise=False)[source]#
Randomly shift intensity with randomly picked offset.
- __call__(img, factor=None, randomize=True)[source]#
Apply the transform to img.
- Parameters:
img – input image to shift intensity.
factor – a factor to multiply the random offset, then shift. can be some image specific value at runtime, like: max(img), etc.
- __init__(offsets, safe=False, prob=0.1, channel_wise=False)[source]#
- Parameters:
offsets – offset range to randomly shift. if single number, offset value is picked from (-offsets, offsets).
safe – if True, then do safe dtype convert when intensity overflow. default to False. E.g., [256, -12] -> [array(0), array(244)]. If True, then [256, -12] -> [array(255), array(0)].
prob – probability of shift.
channel_wise – if True, shift intensity on each channel separately. For each channel, a random offset will be chosen. Please ensure that the first dimension represents the channel of the image if True.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
StdShiftIntensity#
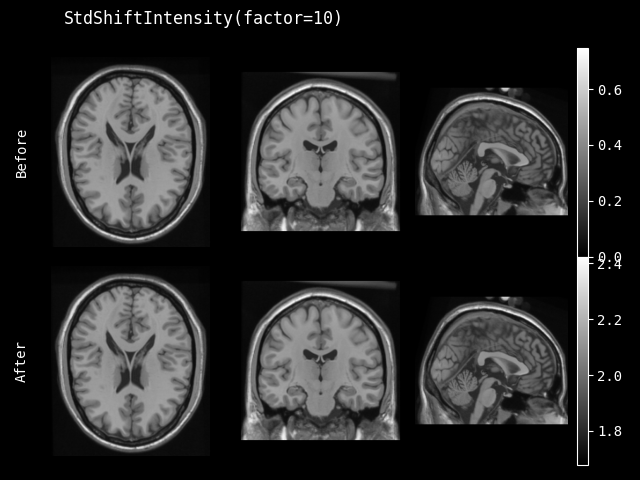
- class monai.transforms.StdShiftIntensity(factor, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
Shift intensity for the image with a factor and the standard deviation of the image by:
v = v + factor * std(v). This transform can focus on only non-zero values or the entire image, and can also calculate the std on each channel separately.- Parameters:
factor (
float) – factor shift byv = v + factor * std(v).nonzero (
bool) – whether only count non-zero values.channel_wise (
bool) – if True, calculate on each channel separately. Please ensure that the first dimension represents the channel of the image if True.dtype (
Union[dtype,type,str,None]) – output data type, if None, same as input image. defaults to float32.
RandStdShiftIntensity#
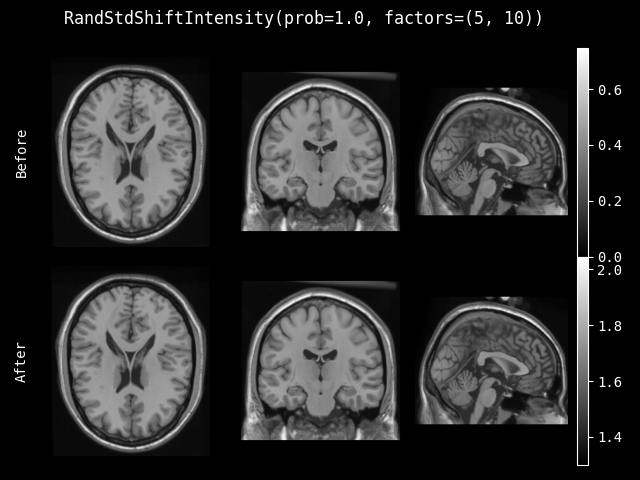
- class monai.transforms.RandStdShiftIntensity(factors, prob=0.1, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
Shift intensity for the image with a factor and the standard deviation of the image by:
v = v + factor * std(v)where the factor is randomly picked.- __call__(img, randomize=True)[source]#
Apply the transform to img.
- Return type:
Union[ndarray,Tensor]
- __init__(factors, prob=0.1, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- Parameters:
factors – if tuple, the randomly picked range is (min(factors), max(factors)). If single number, the range is (-factors, factors).
prob – probability of std shift.
nonzero – whether only count non-zero values.
channel_wise – if True, calculate on each channel separately.
dtype – output data type, if None, same as input image. defaults to float32.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
RandBiasField#
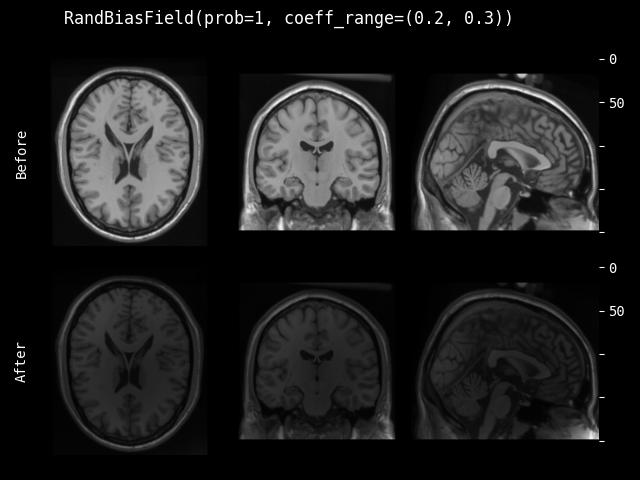
- class monai.transforms.RandBiasField(degree=3, coeff_range=(0.0, 0.1), dtype=<class 'numpy.float32'>, prob=0.1)[source]#
Random bias field augmentation for MR images. The bias field is considered as a linear combination of smoothly varying basis (polynomial) functions, as described in Automated Model-Based Tissue Classification of MR Images of the Brain. This implementation adapted from NiftyNet. Referred to Longitudinal segmentation of age-related white matter hyperintensities.
- Parameters:
degree (
int) – degree of freedom of the polynomials. The value should be no less than 1. Defaults to 3.coeff_range (
tuple[float,float]) – range of the random coefficients. Defaults to (0.0, 0.1).dtype (
Union[dtype,type,str,None]) – output data type, if None, same as input image. defaults to float32.prob (
float) – probability to do random bias field.
- __call__(img, randomize=True)[source]#
Apply the transform to img.
- Return type:
Union[ndarray,Tensor]
- randomize(img_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
ScaleIntensity#
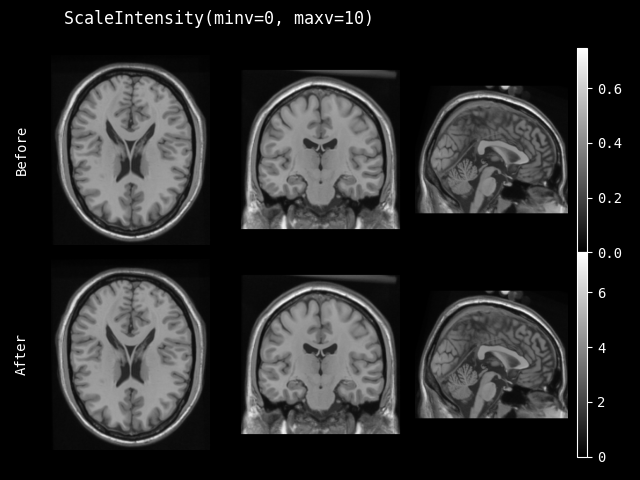
- class monai.transforms.ScaleIntensity(minv=0.0, maxv=1.0, factor=None, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
Scale the intensity of input image to the given value range (minv, maxv). If minv and maxv not provided, use factor to scale image by
v = v * (1 + factor).- __call__(img)[source]#
Apply the transform to img.
- Raises:
ValueError – When
self.minv=Noneorself.maxv=Noneandself.factor=None. Incompatible values.- Return type:
Union[ndarray,Tensor]
- __init__(minv=0.0, maxv=1.0, factor=None, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- Parameters:
minv – minimum value of output data.
maxv – maximum value of output data.
factor – factor scale by
v = v * (1 + factor). In order to use this parameter, please set both minv and maxv into None.channel_wise – if True, scale on each channel separately. Please ensure that the first dimension represents the channel of the image if True.
dtype – output data type, if None, same as input image. defaults to float32.
ClipIntensityPercentiles#
- class monai.transforms.ClipIntensityPercentiles(lower, upper, sharpness_factor=None, channel_wise=False, return_clipping_values=False, dtype=<class 'numpy.float32'>)[source]#
Apply clip based on the intensity distribution of input image. If sharpness_factor is provided, the intensity values will be soft clipped according to f(x) = x + (1/sharpness_factor)*softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv)) From https://medium.com/life-at-hopper/clip-it-clip-it-good-1f1bf711b291
Soft clipping preserves the order of the values and maintains the gradient everywhere. For example:
image = torch.Tensor( [[[1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5]]]) # Hard clipping from lower and upper image intensity percentiles hard_clipper = ClipIntensityPercentiles(30, 70) print(hard_clipper(image)) metatensor([[[2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.]]]) # Soft clipping from lower and upper image intensity percentiles soft_clipper = ClipIntensityPercentiles(30, 70, 10.) print(soft_clipper(image)) metatensor([[[2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000]]])
- __init__(lower, upper, sharpness_factor=None, channel_wise=False, return_clipping_values=False, dtype=<class 'numpy.float32'>)[source]#
- Parameters:
lower – lower intensity percentile. In the case of hard clipping, None will have the same effect as 0 by not clipping the lowest input values. However, in the case of soft clipping, None and zero will have two different effects: None will not apply clipping to low values, whereas zero will still transform the lower values according to the soft clipping transformation. Please check for more details: https://medium.com/life-at-hopper/clip-it-clip-it-good-1f1bf711b291.
upper – upper intensity percentile. The same as for lower, but this time with the highest values. If we are looking to perform soft clipping, if None then there will be no effect on this side whereas if set to 100, the values will be passed via the corresponding clipping equation.
sharpness_factor – if not None, the intensity values will be soft clipped according to f(x) = x + (1/sharpness_factor)*softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv)). defaults to None.
channel_wise – if True, compute intensity percentile and normalize every channel separately. default to False.
return_clipping_values – whether to return the calculated percentiles in tensor meta information. If soft clipping and requested percentile is None, return None as the corresponding clipping values in meta information. Clipping values are stored in a list with each element corresponding to a channel if channel_wise is set to True. defaults to False.
dtype – output data type, if None, same as input image. defaults to float32.
RandScaleIntensity#
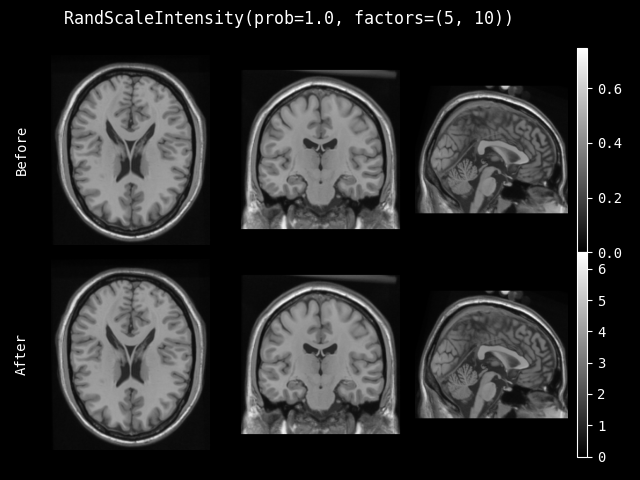
- class monai.transforms.RandScaleIntensity(factors, prob=0.1, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
Randomly scale the intensity of input image by
v = v * (1 + factor)where the factor is randomly picked.- __call__(img, randomize=True)[source]#
Apply the transform to img.
- Return type:
Union[ndarray,Tensor]
- __init__(factors, prob=0.1, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- Parameters:
factors – factor range to randomly scale by
v = v * (1 + factor). if single number, factor value is picked from (-factors, factors).prob – probability of scale.
channel_wise – if True, scale on each channel separately. Please ensure that the first dimension represents the channel of the image if True.
dtype – output data type, if None, same as input image. defaults to float32.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
ScaleIntensityFixedMean#
- class monai.transforms.ScaleIntensityFixedMean(factor=0, preserve_range=False, fixed_mean=True, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
Scale the intensity of input image by
v = v * (1 + factor), then shift the output so that the output image has the same mean as the input.- __call__(img, factor=None)[source]#
Apply the transform to img. :type img:
Union[ndarray,Tensor] :param img: the input tensor/array :param factor: factor scale byv = v * (1 + factor)- Return type:
Union[ndarray,Tensor]
- __init__(factor=0, preserve_range=False, fixed_mean=True, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- Parameters:
factor (
float) – factor scale byv = v * (1 + factor).preserve_range (
bool) – clips the output array/tensor to the range of the input array/tensorfixed_mean (
bool) – subtract the mean intensity before scaling with factor, then add the same value after scaling to ensure that the output has the same mean as the input.channel_wise (
bool) – if True, scale on each channel separately. preserve_range and fixed_mean are also applied on each channel separately if channel_wise is True. Please ensure that the first dimension represents the channel of the image if True.dtype (
Union[dtype,type,str,None]) – output data type, if None, same as input image. defaults to float32.
RandScaleIntensityFixedMean#
- class monai.transforms.RandScaleIntensityFixedMean(prob=0.1, factors=0, fixed_mean=True, preserve_range=False, dtype=<class 'numpy.float32'>)[source]#
Randomly scale the intensity of input image by
v = v * (1 + factor)where the factor is randomly picked. Subtract the mean intensity before scaling with factor, then add the same value after scaling to ensure that the output has the same mean as the input.- __call__(img, randomize=True)[source]#
Apply the transform to img.
- Return type:
Union[ndarray,Tensor]
- __init__(prob=0.1, factors=0, fixed_mean=True, preserve_range=False, dtype=<class 'numpy.float32'>)[source]#
- Parameters:
factors – factor range to randomly scale by
v = v * (1 + factor). if single number, factor value is picked from (-factors, factors).preserve_range – clips the output array/tensor to the range of the input array/tensor
fixed_mean – subtract the mean intensity before scaling with factor, then add the same value after scaling to ensure that the output has the same mean as the input.
channel_wise – if True, scale on each channel separately. preserve_range and fixed_mean are also applied
the (on each channel separately if channel_wise is True. Please ensure that the first dimension represents)
True. (channel of the image if)
dtype – output data type, if None, same as input image. defaults to float32.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
NormalizeIntensity#
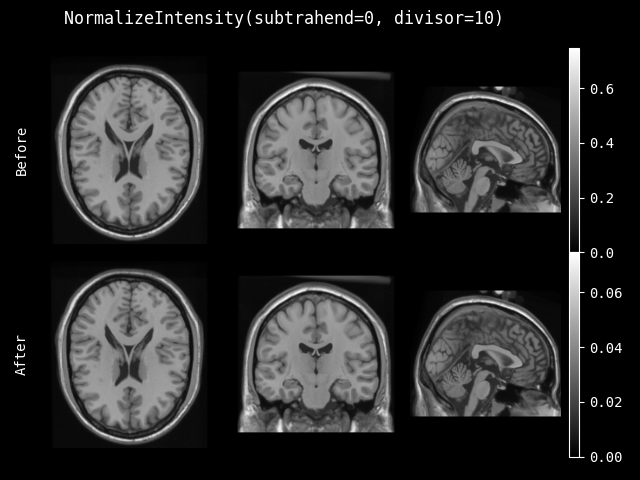
- class monai.transforms.NormalizeIntensity(subtrahend=None, divisor=None, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
Normalize input based on the subtrahend and divisor: (img - subtrahend) / divisor. Use calculated mean or std value of the input image if no subtrahend or divisor provided. This transform can normalize only non-zero values or entire image, and can also calculate mean and std on each channel separately. When channel_wise is True, the first dimension of subtrahend and divisor should be the number of image channels if they are not None.
- Parameters:
subtrahend – the amount to subtract by (usually the mean).
divisor – the amount to divide by (usually the standard deviation).
nonzero – whether only normalize non-zero values.
channel_wise – if True, calculate on each channel separately, otherwise, calculate on the entire image directly. default to False.
dtype – output data type, if None, same as input image. defaults to float32.
ThresholdIntensity#
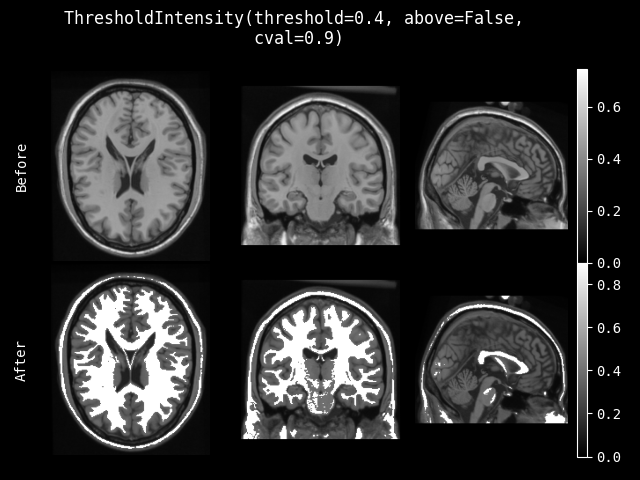
- class monai.transforms.ThresholdIntensity(threshold, above=True, cval=0.0)[source]#
Filter the intensity values of whole image to below threshold or above threshold. And fill the remaining parts of the image to the cval value.
- Parameters:
threshold (
float) – the threshold to filter intensity values.above (
bool) – filter values above the threshold or below the threshold, default is True.cval (
float) – value to fill the remaining parts of the image, default is 0.
ScaleIntensityRange#
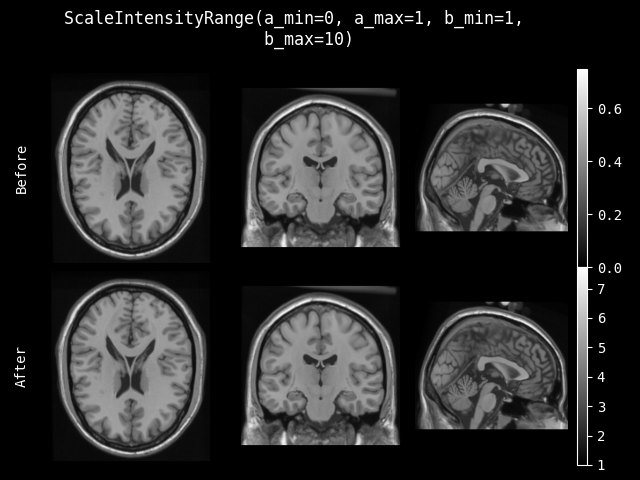
- class monai.transforms.ScaleIntensityRange(a_min, a_max, b_min=None, b_max=None, clip=False, dtype=<class 'numpy.float32'>)[source]#
Apply specific intensity scaling to the whole numpy array. Scaling from [a_min, a_max] to [b_min, b_max] with clip option.
When b_min or b_max are None, scaled_array * (b_max - b_min) + b_min will be skipped. If clip=True, when b_min/b_max is None, the clipping is not performed on the corresponding edge.
- Parameters:
a_min – intensity original range min.
a_max – intensity original range max.
b_min – intensity target range min.
b_max – intensity target range max.
clip – whether to perform clip after scaling.
dtype – output data type, if None, same as input image. defaults to float32.
ScaleIntensityRangePercentiles#
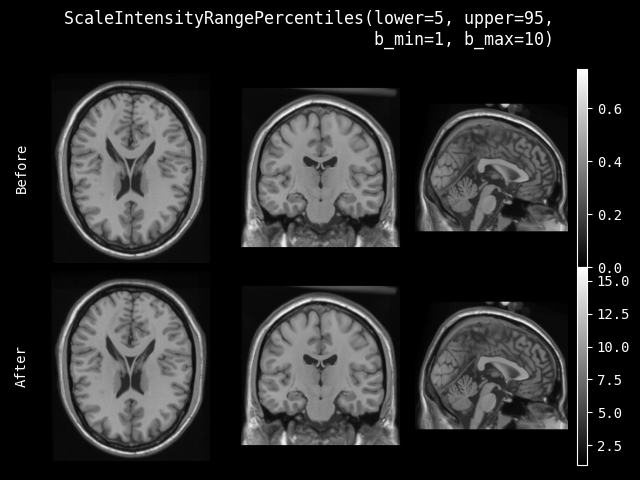
- class monai.transforms.ScaleIntensityRangePercentiles(lower, upper, b_min, b_max, clip=False, relative=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
Apply range scaling to a numpy array based on the intensity distribution of the input.
By default this transform will scale from [lower_intensity_percentile, upper_intensity_percentile] to [b_min, b_max], where {lower,upper}_intensity_percentile are the intensity values at the corresponding percentiles of
img.The
relativeparameter can also be set to scale from [lower_intensity_percentile, upper_intensity_percentile] to the lower and upper percentiles of the output range [b_min, b_max].For example:
image = torch.Tensor( [[[1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5]]]) # Scale from lower and upper image intensity percentiles # to output range [b_min, b_max] scaler = ScaleIntensityRangePercentiles(10, 90, 0, 200, False, False) print(scaler(image)) metatensor([[[ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.]]]) # Scale from lower and upper image intensity percentiles # to lower and upper percentiles of the output range [b_min, b_max] rel_scaler = ScaleIntensityRangePercentiles(10, 90, 0, 200, False, True) print(rel_scaler(image)) metatensor([[[ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.]]])
See also
- Parameters:
lower – lower intensity percentile.
upper – upper intensity percentile.
b_min – intensity target range min.
b_max – intensity target range max.
clip – whether to perform clip after scaling.
relative – whether to scale to the corresponding percentiles of [b_min, b_max].
channel_wise – if True, compute intensity percentile and normalize every channel separately. default to False.
dtype – output data type, if None, same as input image. defaults to float32.
AdjustContrast#
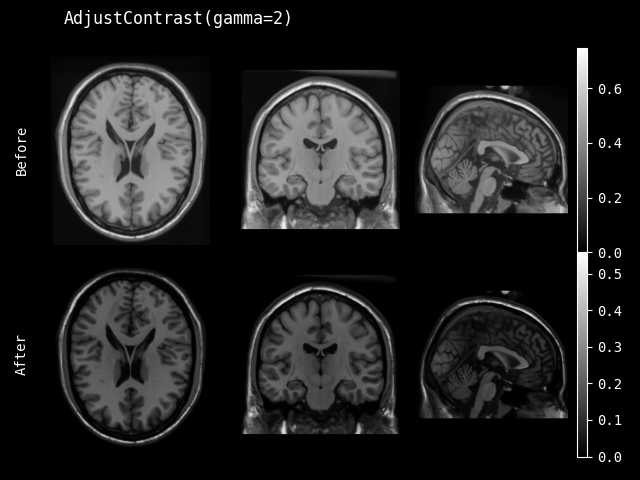
- class monai.transforms.AdjustContrast(gamma, invert_image=False, retain_stats=False)[source]#
Changes image intensity with gamma transform. Each pixel/voxel intensity is updated as:
x = ((x - min) / intensity_range) ^ gamma * intensity_range + min
- Parameters:
gamma (
float) – gamma value to adjust the contrast as function.invert_image (
bool) – whether to invert the image before applying gamma augmentation. If True, multiply all intensity values with -1 before the gamma transform and again after the gamma transform. This behaviour is mimicked from nnU-Net, specifically this function.retain_stats (
bool) –if True, applies a scaling factor and an offset to all intensity values after gamma transform to ensure that the output intensity distribution has the same mean and standard deviation as the intensity distribution of the input. This behaviour is mimicked from nnU-Net, specifically this function.
RandAdjustContrast#
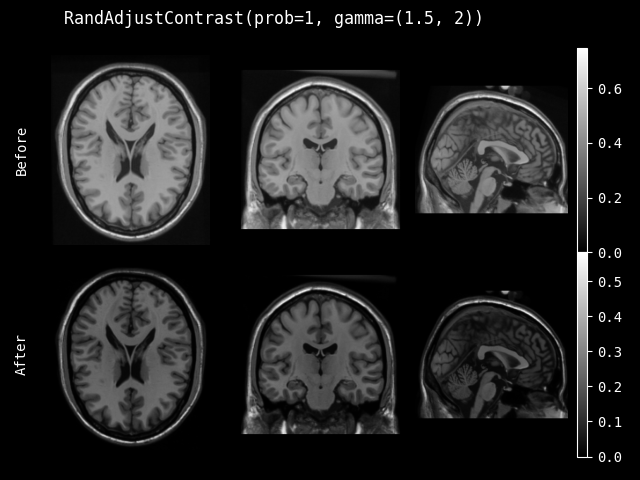
- class monai.transforms.RandAdjustContrast(prob=0.1, gamma=(0.5, 4.5), invert_image=False, retain_stats=False)[source]#
Randomly changes image intensity with gamma transform. Each pixel/voxel intensity is updated as:
x = ((x - min) / intensity_range) ^ gamma * intensity_range + min
- Parameters:
prob – Probability of adjustment.
gamma – Range of gamma values. If single number, value is picked from (0.5, gamma), default is (0.5, 4.5).
invert_image –
whether to invert the image before applying gamma augmentation. If True, multiply all intensity values with -1 before the gamma transform and again after the gamma transform. This behaviour is mimicked from nnU-Net, specifically this function.
retain_stats –
if True, applies a scaling factor and an offset to all intensity values after gamma transform to ensure that the output intensity distribution has the same mean and standard deviation as the intensity distribution of the input. This behaviour is mimicked from nnU-Net, specifically this function.
- __call__(img, randomize=True)[source]#
Apply the transform to img.
- Return type:
Union[ndarray,Tensor]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
MaskIntensity#
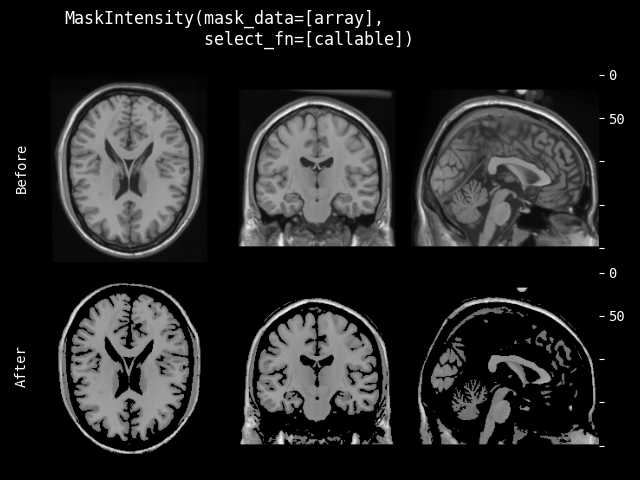
- class monai.transforms.MaskIntensity(mask_data=None, select_fn=<function is_positive>)[source]#
Mask the intensity values of input image with the specified mask data. Mask data must have the same spatial size as the input image, and all the intensity values of input image corresponding to the selected values in the mask data will keep the original value, others will be set to 0.
- Parameters:
mask_data – if mask_data is single channel, apply to every channel of input image. if multiple channels, the number of channels must match the input data. the intensity values of input image corresponding to the selected values in the mask data will keep the original value, others will be set to 0. if None, must specify the mask_data at runtime.
select_fn – function to select valid values of the mask_data, default is to select values > 0.
- __call__(img, mask_data=None)[source]#
- Parameters:
mask_data – if mask data is single channel, apply to every channel of input image. if multiple channels, the channel number must match input data. mask_data will be converted to bool values by mask_data > 0 before applying transform to input image.
- Raises:
- ValueError – When both
mask_dataandself.mask_dataare None.- ValueError – When
mask_dataandimgchannels differ andmask_datais not single channel.
SavitzkyGolaySmooth#
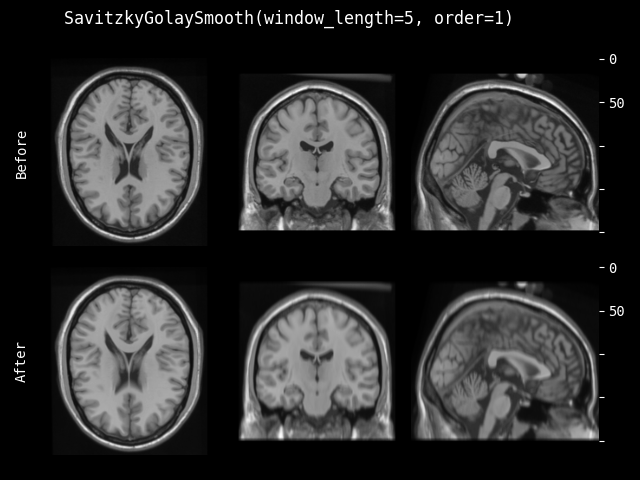
- class monai.transforms.SavitzkyGolaySmooth(window_length, order, axis=1, mode='zeros')[source]#
Smooth the input data along the given axis using a Savitzky-Golay filter.
- Parameters:
window_length (
int) – Length of the filter window, must be a positive odd integer.order (
int) – Order of the polynomial to fit to each window, must be less thanwindow_length.axis (
int) – Optional axis along which to apply the filter kernel. Default 1 (first spatial dimension).mode (
str) – Optional padding mode, passed to convolution class.'zeros','reflect','replicate'or'circular'. Default:'zeros'. Seetorch.nn.Conv1d()for more information.
MedianSmooth#
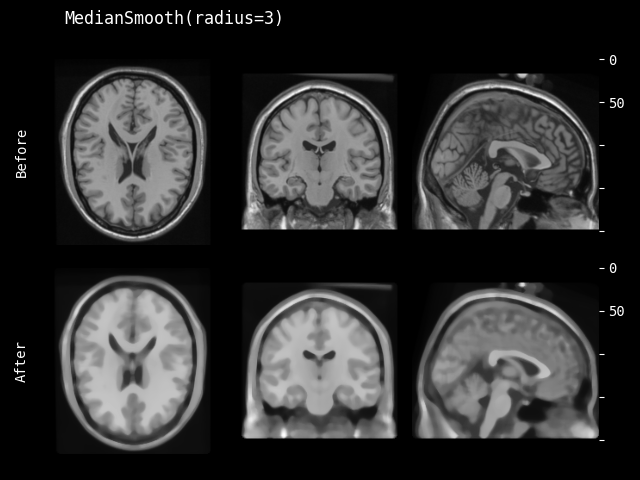
- class monai.transforms.MedianSmooth(radius=1)[source]#
Apply median filter to the input data based on specified radius parameter. A default value radius=1 is provided for reference.
See also:
monai.networks.layers.median_filter()- Parameters:
radius – if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
- __call__(img)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
~NdarrayTensor
GaussianSmooth#
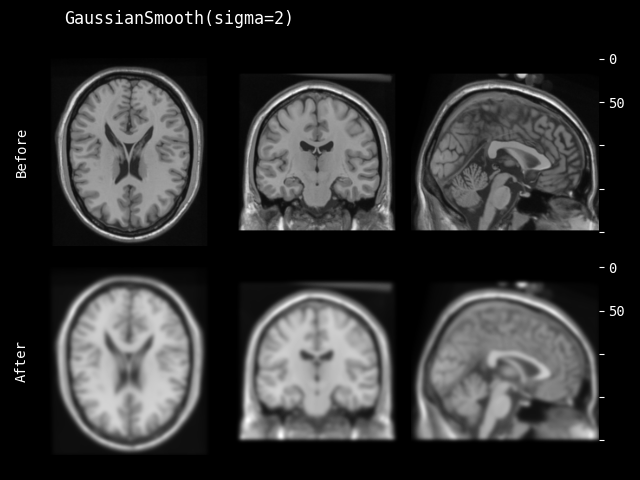
- class monai.transforms.GaussianSmooth(sigma=1.0, approx='erf')[source]#
Apply Gaussian smooth to the input data based on specified sigma parameter. A default value sigma=1.0 is provided for reference.
- Parameters:
sigma – if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
approx – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see also
monai.networks.layers.GaussianFilter().
- __call__(img)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
~NdarrayTensor
RandGaussianSmooth#
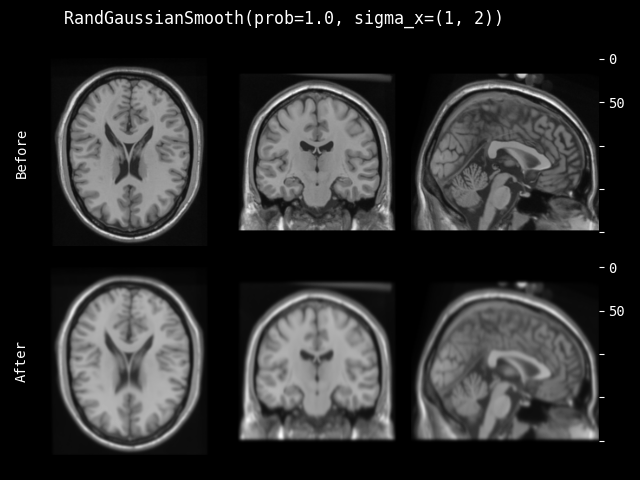
- class monai.transforms.RandGaussianSmooth(sigma_x=(0.25, 1.5), sigma_y=(0.25, 1.5), sigma_z=(0.25, 1.5), prob=0.1, approx='erf')[source]#
Apply Gaussian smooth to the input data based on randomly selected sigma parameters.
- Parameters:
sigma_x (
tuple[float,float]) – randomly select sigma value for the first spatial dimension.sigma_y (
tuple[float,float]) – randomly select sigma value for the second spatial dimension if have.sigma_z (
tuple[float,float]) – randomly select sigma value for the third spatial dimension if have.prob (
float) – probability of Gaussian smooth.approx (
str) – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see alsomonai.networks.layers.GaussianFilter().
- __call__(img, randomize=True)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Union[ndarray,Tensor]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
GaussianSharpen#
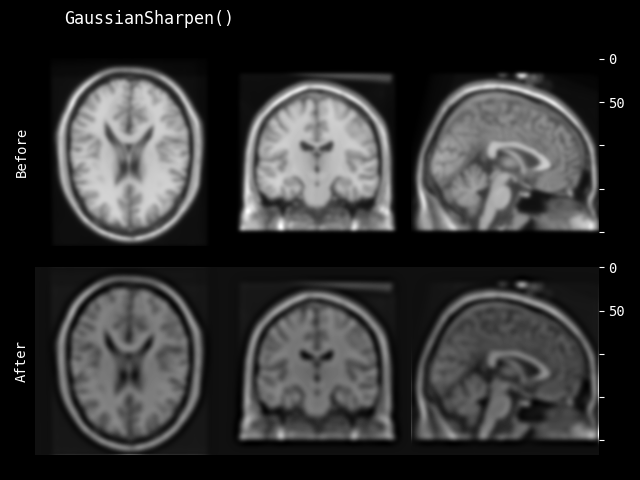
- class monai.transforms.GaussianSharpen(sigma1=3.0, sigma2=1.0, alpha=30.0, approx='erf')[source]#
Sharpen images using the Gaussian Blur filter. Referring to: http://scipy-lectures.org/advanced/image_processing/auto_examples/plot_sharpen.html. The algorithm is shown as below
blurred_f = gaussian_filter(img, sigma1) filter_blurred_f = gaussian_filter(blurred_f, sigma2) img = blurred_f + alpha * (blurred_f - filter_blurred_f)
A set of default values sigma1=3.0, sigma2=1.0 and alpha=30.0 is provide for reference.
- Parameters:
sigma1 – sigma parameter for the first gaussian kernel. if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
sigma2 – sigma parameter for the second gaussian kernel. if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
alpha – weight parameter to compute the final result.
approx – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see also
monai.networks.layers.GaussianFilter().
- __call__(img)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
~NdarrayTensor
RandGaussianSharpen#
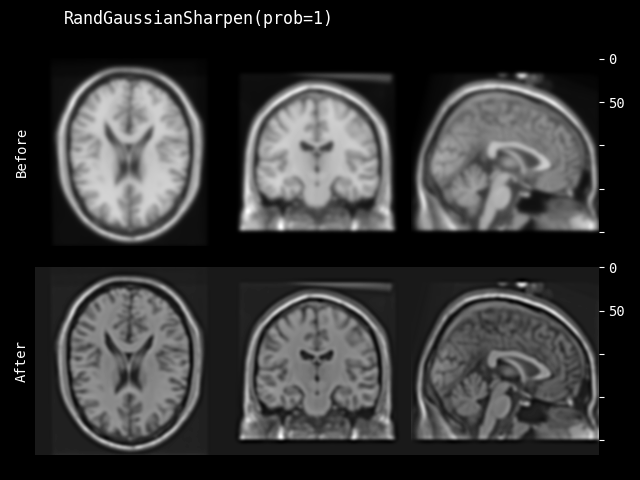
- class monai.transforms.RandGaussianSharpen(sigma1_x=(0.5, 1.0), sigma1_y=(0.5, 1.0), sigma1_z=(0.5, 1.0), sigma2_x=0.5, sigma2_y=0.5, sigma2_z=0.5, alpha=(10.0, 30.0), approx='erf', prob=0.1)[source]#
Sharpen images using the Gaussian Blur filter based on randomly selected sigma1, sigma2 and alpha. The algorithm is
monai.transforms.GaussianSharpen.- Parameters:
sigma1_x – randomly select sigma value for the first spatial dimension of first gaussian kernel.
sigma1_y – randomly select sigma value for the second spatial dimension(if have) of first gaussian kernel.
sigma1_z – randomly select sigma value for the third spatial dimension(if have) of first gaussian kernel.
sigma2_x – randomly select sigma value for the first spatial dimension of second gaussian kernel. if only 1 value X provided, it must be smaller than sigma1_x and randomly select from [X, sigma1_x].
sigma2_y – randomly select sigma value for the second spatial dimension(if have) of second gaussian kernel. if only 1 value Y provided, it must be smaller than sigma1_y and randomly select from [Y, sigma1_y].
sigma2_z – randomly select sigma value for the third spatial dimension(if have) of second gaussian kernel. if only 1 value Z provided, it must be smaller than sigma1_z and randomly select from [Z, sigma1_z].
alpha – randomly select weight parameter to compute the final result.
approx – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see also
monai.networks.layers.GaussianFilter().prob – probability of Gaussian sharpen.
- __call__(img, randomize=True)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Union[ndarray,Tensor]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
RandHistogramShift#
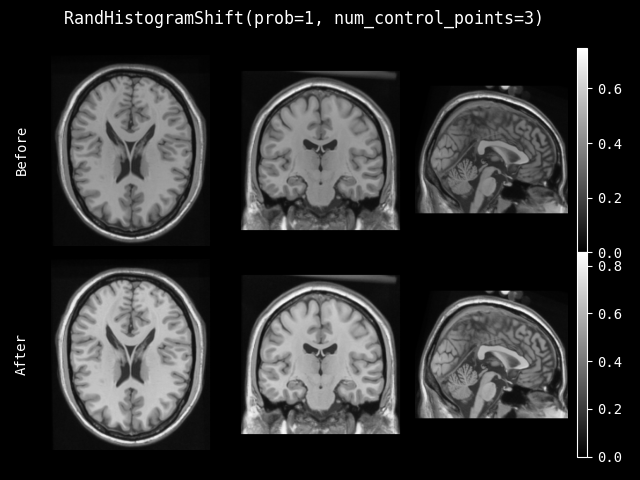
- class monai.transforms.RandHistogramShift(num_control_points=10, prob=0.1)[source]#
Apply random nonlinear transform to the image’s intensity histogram.
- Parameters:
num_control_points – number of control points governing the nonlinear intensity mapping. a smaller number of control points allows for larger intensity shifts. if two values provided, number of control points selecting from range (min_value, max_value).
prob – probability of histogram shift.
- __call__(img, randomize=True)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Union[ndarray,Tensor]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
DetectEnvelope#
- class monai.transforms.DetectEnvelope(axis=1, n=None)[source]#
Find the envelope of the input data along the requested axis using a Hilbert transform.
- Parameters:
axis – Axis along which to detect the envelope. Default 1, i.e. the first spatial dimension.
n – FFT size. Default img.shape[axis]. Input will be zero-padded or truncated to this size along dimension
axis.
GibbsNoise#
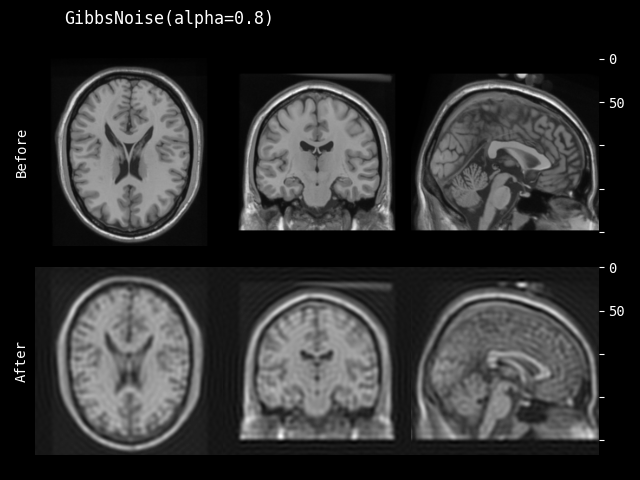
- class monai.transforms.GibbsNoise(alpha=0.1)[source]#
The transform applies Gibbs noise to 2D/3D MRI images. Gibbs artifacts are one of the common type of type artifacts appearing in MRI scans.
The transform is applied to all the channels in the data.
For general information on Gibbs artifacts, please refer to:
An Image-based Approach to Understanding the Physics of MR Artifacts.
The AAPM/RSNA Physics Tutorial for Residents
- Parameters:
alpha (
float) – Parametrizes the intensity of the Gibbs noise filter applied. Takes values in the interval [0,1] with alpha = 0 acting as the identity mapping.
- __call__(img)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Union[ndarray,Tensor]
RandGibbsNoise#
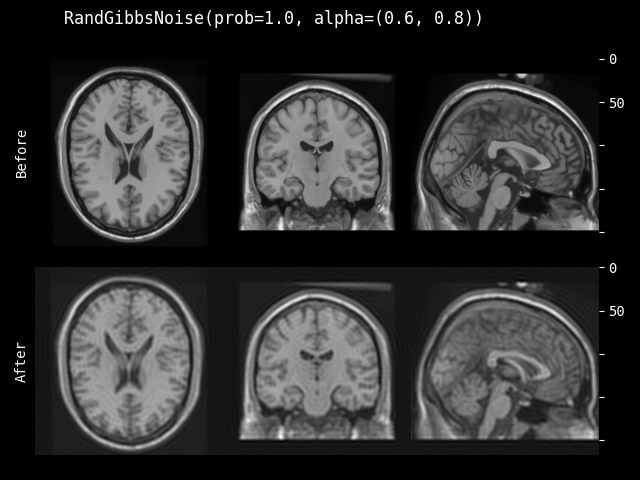
- class monai.transforms.RandGibbsNoise(prob=0.1, alpha=(0.0, 1.0))[source]#
Naturalistic image augmentation via Gibbs artifacts. The transform randomly applies Gibbs noise to 2D/3D MRI images. Gibbs artifacts are one of the common type of type artifacts appearing in MRI scans.
The transform is applied to all the channels in the data.
For general information on Gibbs artifacts, please refer to: https://pubs.rsna.org/doi/full/10.1148/rg.313105115 https://pubs.rsna.org/doi/full/10.1148/radiographics.22.4.g02jl14949
- Parameters:
prob (float) – probability of applying the transform.
alpha (float, Sequence(float)) – Parametrizes the intensity of the Gibbs noise filter applied. Takes values in the interval [0,1] with alpha = 0 acting as the identity mapping. If a length-2 list is given as [a,b] then the value of alpha will be sampled uniformly from the interval [a,b]. 0 <= a <= b <= 1. If a float is given, then the value of alpha will be sampled uniformly from the interval [0, alpha].
- __call__(img, randomize=True)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
KSpaceSpikeNoise#
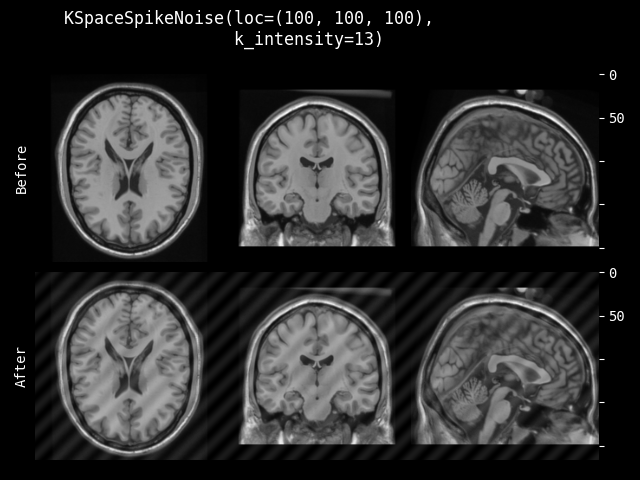
- class monai.transforms.KSpaceSpikeNoise(loc, k_intensity=None)[source]#
Apply localized spikes in k-space at the given locations and intensities. Spike (Herringbone) artifact is a type of data acquisition artifact which may occur during MRI scans.
For general information on spike artifacts, please refer to:
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- Parameters:
loc – spatial location for the spikes. For images with 3D spatial dimensions, the user can provide (C, X, Y, Z) to fix which channel C is affected, or (X, Y, Z) to place the same spike in all channels. For 2D cases, the user can provide (C, X, Y) or (X, Y).
k_intensity – value for the log-intensity of the k-space version of the image. If one location is passed to
locor the channel is not specified, then this argument should receive a float. Iflocis given a sequence of locations, then this argument should receive a sequence of intensities. This value should be tested as it is data-dependent. The default values are the 2.5 the mean of the log-intensity for each channel.
Example
When working with 4D data,
KSpaceSpikeNoise(loc = ((3,60,64,32), (64,60,32)), k_intensity = (13,14))will place a spike at [3, 60, 64, 32] with log-intensity = 13, and one spike per channel located respectively at [: , 64, 60, 32] with log-intensity = 14.
RandKSpaceSpikeNoise#
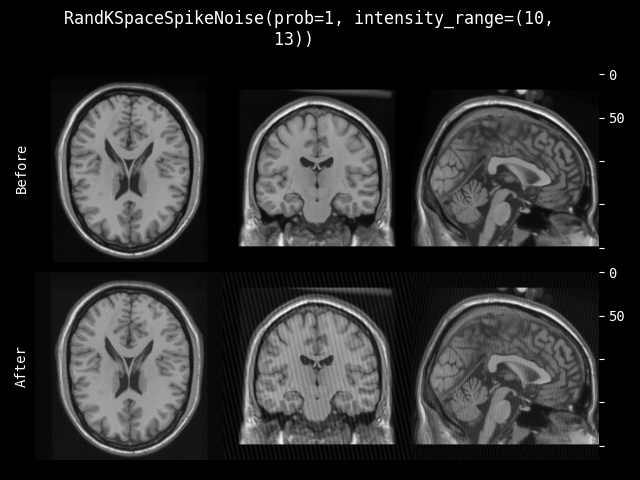
- class monai.transforms.RandKSpaceSpikeNoise(prob=0.1, intensity_range=None, channel_wise=True)[source]#
Naturalistic data augmentation via spike artifacts. The transform applies localized spikes in k-space, and it is the random version of
monai.transforms.KSpaceSpikeNoise.Spike (Herringbone) artifact is a type of data acquisition artifact which may occur during MRI scans. For general information on spike artifacts, please refer to:
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- Parameters:
prob – probability of applying the transform, either on all channels at once, or channel-wise if
channel_wise = True.intensity_range – pass a tuple (a, b) to sample the log-intensity from the interval (a, b) uniformly for all channels. Or pass sequence of intervals ((a0, b0), (a1, b1), …) to sample for each respective channel. In the second case, the number of 2-tuples must match the number of channels. Default ranges is (0.95x, 1.10x) where x is the mean log-intensity for each channel.
channel_wise – treat each channel independently. True by default.
Example
To apply k-space spikes randomly with probability 0.5, and log-intensity sampled from the interval [11, 12] for each channel independently, one uses
RandKSpaceSpikeNoise(prob=0.5, intensity_range=(11, 12), channel_wise=True)- __call__(img, randomize=True)[source]#
Apply transform to img. Assumes data is in channel-first form.
- Parameters:
img (
Union[ndarray,Tensor]) – image with dimensions (C, H, W) or (C, H, W, D)
- randomize(img, intensity_range)[source]#
Helper method to sample both the location and intensity of the spikes. When not working channel wise (channel_wise=False) it use the random variable
self._do_transformto decide whether to sample a location and intensity.When working channel wise, the method randomly samples a location and intensity for each channel depending on
self._do_transform.- Return type:
None
RandRicianNoise#
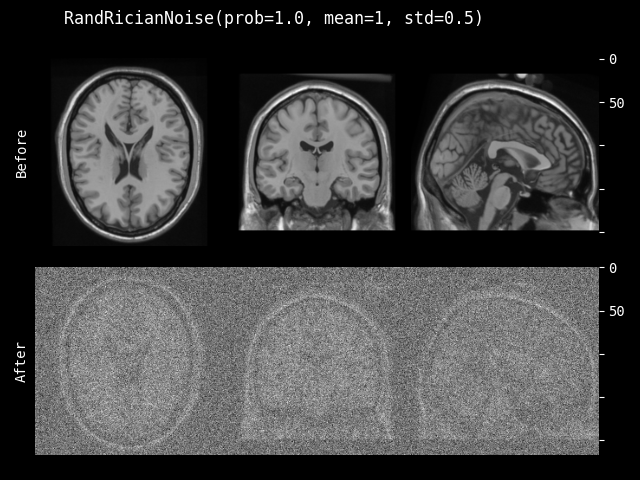
- class monai.transforms.RandRicianNoise(prob=0.1, mean=0.0, std=1.0, channel_wise=False, relative=False, sample_std=True, dtype=<class 'numpy.float32'>)[source]#
Add Rician noise to image. Rician noise in MRI is the result of performing a magnitude operation on complex data with Gaussian noise of the same variance in both channels, as described in Noise in Magnitude Magnetic Resonance Images. This transform is adapted from DIPY. See also: The rician distribution of noisy mri data.
- Parameters:
prob – Probability to add Rician noise.
mean – Mean or “centre” of the Gaussian distributions sampled to make up the Rician noise.
std – Standard deviation (spread) of the Gaussian distributions sampled to make up the Rician noise.
channel_wise – If True, treats each channel of the image separately.
relative – If True, the spread of the sampled Gaussian distributions will be std times the standard deviation of the image or channel’s intensity histogram.
sample_std – If True, sample the spread of the Gaussian distributions uniformly from 0 to std.
dtype – output data type, if None, same as input image. defaults to float32.
RandCoarseTransform#
- class monai.transforms.RandCoarseTransform(holes, spatial_size, max_holes=None, max_spatial_size=None, prob=0.1)[source]#
Randomly select coarse regions in the image, then execute transform operations for the regions. It’s the base class of all kinds of region transforms. Refer to papers: https://arxiv.org/abs/1708.04552
- Parameters:
holes – number of regions to dropout, if max_holes is not None, use this arg as the minimum number to randomly select the expected number of regions.
spatial_size – spatial size of the regions to dropout, if max_spatial_size is not None, use this arg as the minimum spatial size to randomly select size for every region. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
max_holes – if not None, define the maximum number to randomly select the expected number of regions.
max_spatial_size – if not None, define the maximum spatial size to randomly select size for every region. if some components of the max_spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, max_spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
prob – probability of applying the transform.
- __call__(img, randomize=True)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Union[ndarray,Tensor]
- randomize(img_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
RandCoarseDropout#
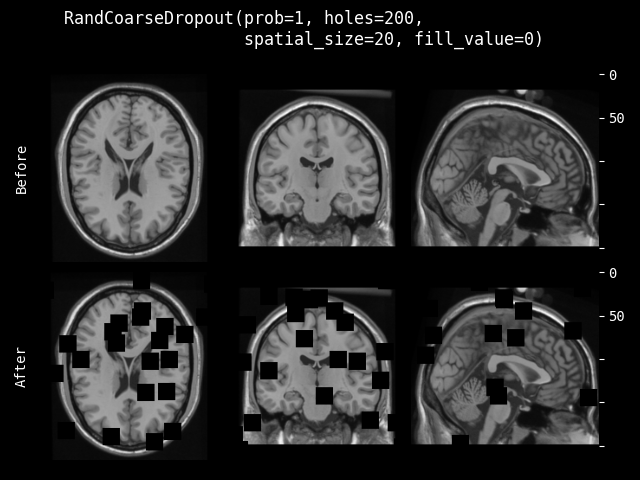
- class monai.transforms.RandCoarseDropout(holes, spatial_size, dropout_holes=True, fill_value=None, max_holes=None, max_spatial_size=None, prob=0.1)[source]#
Randomly coarse dropout regions in the image, then fill in the rectangular regions with specified value. Or keep the rectangular regions and fill in the other areas with specified value. Refer to papers: https://arxiv.org/abs/1708.04552, https://arxiv.org/pdf/1604.07379 And other implementation: https://albumentations.ai/docs/api_reference/augmentations/transforms/ #albumentations.augmentations.transforms.CoarseDropout.
- Parameters:
holes – number of regions to dropout, if max_holes is not None, use this arg as the minimum number to randomly select the expected number of regions.
spatial_size – spatial size of the regions to dropout, if max_spatial_size is not None, use this arg as the minimum spatial size to randomly select size for every region. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
dropout_holes – if True, dropout the regions of holes and fill value, if False, keep the holes and dropout the outside and fill value. default to True.
fill_value – target value to fill the dropout regions, if providing a number, will use it as constant value to fill all the regions. if providing a tuple for the min and max, will randomly select value for every pixel / voxel from the range [min, max). if None, will compute the min and max value of input image then randomly select value to fill, default to None.
max_holes – if not None, define the maximum number to randomly select the expected number of regions.
max_spatial_size – if not None, define the maximum spatial size to randomly select size for every region. if some components of the max_spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, max_spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
prob – probability of applying the transform.
RandCoarseShuffle#
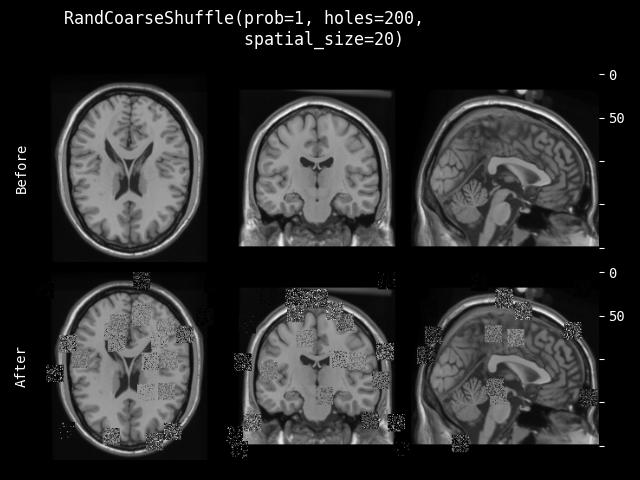
- class monai.transforms.RandCoarseShuffle(holes, spatial_size, max_holes=None, max_spatial_size=None, prob=0.1)[source]#
Randomly select regions in the image, then shuffle the pixels within every region. It shuffles every channel separately. Refer to paper: Kang, Guoliang, et al. “Patchshuffle regularization.” arXiv preprint arXiv:1707.07103 (2017). https://arxiv.org/abs/1707.07103
- Parameters:
holes – number of regions to dropout, if max_holes is not None, use this arg as the minimum number to randomly select the expected number of regions.
spatial_size – spatial size of the regions to dropout, if max_spatial_size is not None, use this arg as the minimum spatial size to randomly select size for every region. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
max_holes – if not None, define the maximum number to randomly select the expected number of regions.
max_spatial_size – if not None, define the maximum spatial size to randomly select size for every region. if some components of the max_spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, max_spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
prob – probability of applying the transform.
HistogramNormalize#
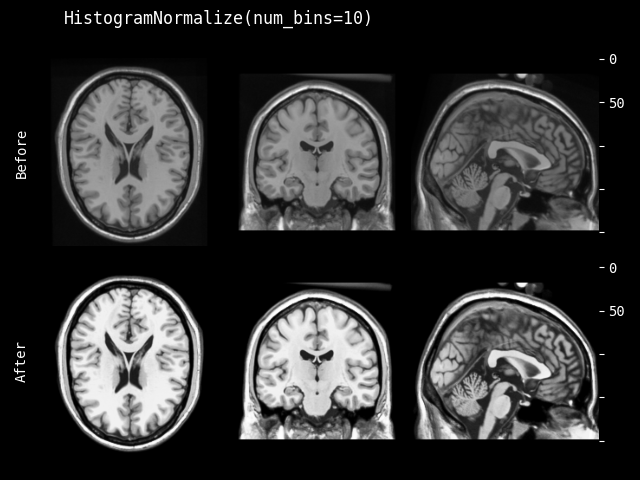
- class monai.transforms.HistogramNormalize(num_bins=256, min=0, max=255, mask=None, dtype=<class 'numpy.float32'>)[source]#
Apply the histogram normalization to input image. Refer to: facebookresearch/CovidPrognosis.
- Parameters:
num_bins – number of the bins to use in histogram, default to 256. for more details: https://numpy.org/doc/stable/reference/generated/numpy.histogram.html.
min – the min value to normalize input image, default to 0.
max – the max value to normalize input image, default to 255.
mask – if provided, must be ndarray of bools or 0s and 1s, and same shape as image. only points at which mask==True are used for the equalization. can also provide the mask along with img at runtime.
dtype – data type of the output, if None, same as input image. default to float32.
- __call__(img, mask=None)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
ForegroundMask#
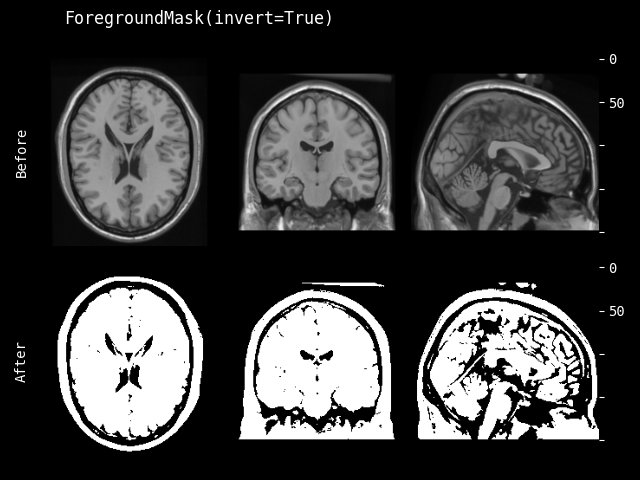
- class monai.transforms.ForegroundMask(threshold='otsu', hsv_threshold=None, invert=False)[source]#
Creates a binary mask that defines the foreground based on thresholds in RGB or HSV color space. This transform receives an RGB (or grayscale) image where by default it is assumed that the foreground has low values (dark) while the background has high values (white). Otherwise, set invert argument to True.
- Parameters:
threshold – an int or a float number that defines the threshold that values less than that are foreground. It also can be a callable that receives each dimension of the image and calculate the threshold, or a string that defines such callable from skimage.filter.threshold_…. For the list of available threshold functions, please refer to https://scikit-image.org/docs/stable/api/skimage.filters.html Moreover, a dictionary can be passed that defines such thresholds for each channel, like {“R”: 100, “G”: “otsu”, “B”: skimage.filter.threshold_mean}
hsv_threshold – similar to threshold but HSV color space (“H”, “S”, and “V”). Unlike RBG, in HSV, value greater than hsv_threshold are considered foreground.
invert – invert the intensity range of the input image, so that the dtype maximum is now the dtype minimum, and vice-versa.
- __call__(image)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
ComputeHoVerMaps#
- class monai.transforms.ComputeHoVerMaps(dtype='float32')[source]#
Compute horizontal and vertical maps from an instance mask It generates normalized horizontal and vertical distances to the center of mass of each region. Input data with the size of [1xHxW[xD]], which channel dim will temporarily removed for calculating coordinates.
- Parameters:
dtype (
Union[dtype,type,str,None]) – the data type of output Tensor. Defaults to “float32”.- Returns:
A torch.Tensor with the size of [2xHxW[xD]], which is stack horizontal and vertical maps
- __call__(mask)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
IO#
LoadImage#
- class monai.transforms.LoadImage(reader=None, image_only=True, dtype=<class 'numpy.float32'>, ensure_channel_first=False, simple_keys=False, prune_meta_pattern=None, prune_meta_sep='.', expanduser=True, *args, **kwargs)[source]#
Load image file or files from provided path based on reader. If reader is not specified, this class automatically chooses readers based on the supported suffixes and in the following order:
User-specified reader at runtime when calling this loader.
User-specified reader in the constructor of LoadImage.
Readers from the last to the first in the registered list.
Current default readers: (nii, nii.gz -> NibabelReader), (png, jpg, bmp -> PILReader), (npz, npy -> NumpyReader), (nrrd -> NrrdReader), (DICOM file -> ITKReader).
Please note that for png, jpg, bmp, and other 2D formats, readers by default swap axis 0 and 1 after loading the array with
reverse_indexingset toTruebecause the spatial axes definition for non-medical specific file formats is different from other common medical packages.See also
tutorial: Project-MONAI/tutorials
- __call__(filename, reader=None)[source]#
Load image file and metadata from the given filename(s). If reader is not specified, this class automatically chooses readers based on the reversed order of registered readers self.readers.
- Parameters:
filename – path file or file-like object or a list of files. will save the filename to meta_data with key filename_or_obj. if provided a list of files, use the filename of first file to save, and will stack them together as multi-channels data. if provided directory path instead of file path, will treat it as DICOM images series and read.
reader – runtime reader to load image file and metadata.
- __init__(reader=None, image_only=True, dtype=<class 'numpy.float32'>, ensure_channel_first=False, simple_keys=False, prune_meta_pattern=None, prune_meta_sep='.', expanduser=True, *args, **kwargs)[source]#
- Parameters:
reader – reader to load image file and metadata - if reader is None, a default set of SUPPORTED_READERS will be used. - if reader is a string, it’s treated as a class name or dotted path (such as
"monai.data.ITKReader"), the supported built-in reader classes are"ITKReader","NibabelReader","NumpyReader","PydicomReader". a reader instance will be constructed with the *args and **kwargs parameters. - if reader is a reader class/instance, it will be registered to this loader accordingly.image_only – if True return only the image MetaTensor, otherwise return image and header dict.
dtype – if not None convert the loaded image to this data type.
ensure_channel_first – if True and loaded both image array and metadata, automatically convert the image array shape to channel first. default to False.
simple_keys – whether to remove redundant metadata keys, default to False for backward compatibility.
prune_meta_pattern – combined with prune_meta_sep, a regular expression used to match and prune keys in the metadata (nested dictionary), default to None, no key deletion.
prune_meta_sep – combined with prune_meta_pattern, used to match and prune keys in the metadata (nested dictionary). default is “.”, see also
monai.transforms.DeleteItemsd. e.g.prune_meta_pattern=".*_code$", prune_meta_sep=" "removes meta keys that ends with"_code".expanduser – if True cast filename to Path and call .expanduser on it, otherwise keep filename as is.
args – additional parameters for reader if providing a reader name.
kwargs – additional parameters for reader if providing a reader name.
Note
The transform returns a MetaTensor, unless set_track_meta(False) has been used, in which case, a torch.Tensor will be returned.
If reader is specified, the loader will attempt to use the specified readers and the default supported readers. This might introduce overheads when handling the exceptions of trying the incompatible loaders. In this case, it is therefore recommended setting the most appropriate reader as the last item of the reader parameter.
- register(reader)[source]#
Register image reader to load image file and metadata.
- Parameters:
reader (
ImageReader) – reader instance to be registered with this loader.
SaveImage#
- class monai.transforms.SaveImage(output_dir='./', output_postfix='trans', output_ext='.nii.gz', output_dtype=<class 'numpy.float32'>, resample=False, mode='nearest', padding_mode=border, scale=None, dtype=<class 'numpy.float64'>, squeeze_end_dims=True, data_root_dir='', separate_folder=True, print_log=True, output_format='', writer=None, channel_dim=0, output_name_formatter=None, folder_layout=None, savepath_in_metadict=False)[source]#
Save the image (in the form of torch tensor or numpy ndarray) and metadata dictionary into files.
The name of saved file will be {input_image_name}_{output_postfix}{output_ext}, where the input_image_name is extracted from the provided metadata dictionary. If no metadata provided, a running index starting from 0 will be used as the filename prefix.
- Parameters:
output_dir – output image directory.
instead (Handled by folder_layout)
None. (if folder_layout is not)
output_postfix – a string appended to all output file names, default to trans.
instead
None.
output_ext – output file extension name.
instead
None.
output_dtype – data type (if not None) for saving data. Defaults to
np.float32.resample – whether to resample image (if needed) before saving the data array, based on the
"spatial_shape"(and"original_affine") from metadata.mode –
This option is used when
resample=True. Defaults to"nearest". Depending on the writers, the possible options are{
"bilinear","nearest","bicubic"}. See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample{
"nearest","linear","bilinear","bicubic","trilinear","area"}. See also: https://pytorch.org/docs/stable/nn.functional.html#interpolate
padding_mode – This option is used when
resample = True. Defaults to"border". Possible options are {"zeros","border","reflection"} See also: https://pytorch.org/docs/stable/nn.functional.html#grid-samplescale – {
255,65535} postprocess data by clipping to [0, 1] and scaling [0, 255] (uint8) or [0, 65535] (uint16). Default isNone(no scaling).dtype – data type during resampling computation. Defaults to
np.float64for best precision. ifNone, use the data type of input data. To set the output data type, useoutput_dtype.squeeze_end_dims – if
True, any trailing singleton dimensions will be removed (after the channel has been moved to the end). So if input is (C,H,W,D), this will be altered to (H,W,D,C), and then if C==1, it will be saved as (H,W,D). If D is also 1, it will be saved as (H,W). IfFalse, image will always be saved as (H,W,D,C).data_root_dir –
if not empty, it specifies the beginning parts of the input file’s absolute path. It’s used to compute
input_file_rel_path, the relative path to the file fromdata_root_dirto preserve folder structure when saving in case there are files in different folders with the same file names. For example, with the following inputs:input_file_name:
/foo/bar/test1/image.niioutput_postfix:
segoutput_ext:
.nii.gzoutput_dir:
/outputdata_root_dir:
/foo/bar
The output will be:
/output/test1/image/image_seg.nii.gzHandled by
folder_layoutinstead, iffolder_layoutis notNone.separate_folder – whether to save every file in a separate folder. For example: for the input filename
image.nii, postfixsegandfolder_pathoutput, ifseparate_folder=True, it will be saved as:output/image/image_seg.nii, ifFalse, saving asoutput/image_seg.nii. Default toTrue. Handled byfolder_layoutinstead, iffolder_layoutis notNone.print_log – whether to print logs when saving. Default to
True.output_format – an optional string of filename extension to specify the output image writer. see also:
monai.data.image_writer.SUPPORTED_WRITERS.writer – a customised
monai.data.ImageWritersubclass to save data arrays. ifNone, use the default writer frommonai.data.image_writeraccording tooutput_ext. if it’s a string, it’s treated as a class name or dotted path (such as"monai.data.ITKWriter"); the supported built-in writer classes are"NibabelWriter","ITKWriter","PILWriter".channel_dim – the index of the channel dimension. Default to
0.Noneto indicate no channel dimension.output_name_formatter – a callable function (returning a kwargs dict) to format the output file name. If using a custom
monai.data.FolderLayoutBaseclass infolder_layout, consider providing your own formatter. see also:monai.data.folder_layout.default_name_formatter().folder_layout – A customized
monai.data.FolderLayoutBasesubclass to define file naming schemes. ifNone, uses the defaultFolderLayout.savepath_in_metadict – if
True, adds a key"saved_to"to the metadata, which contains the path to where the input image has been saved.
- __call__(img, meta_data=None, filename=None)[source]#
- Parameters:
img – target data content that save into file. The image should be channel-first, shape: [C,H,W,[D]].
meta_data – key-value pairs of metadata corresponding to the data.
filename – str or file-like object which to save img. If specified, will ignore self.output_name_formatter and self.folder_layout.
- set_options(init_kwargs=None, data_kwargs=None, meta_kwargs=None, write_kwargs=None)[source]#
Set the options for the underlying writer by updating the self.*_kwargs dictionaries.
The arguments correspond to the following usage:
writer = ImageWriter(**init_kwargs)
writer.set_data_array(array, **data_kwargs)
writer.set_metadata(meta_data, **meta_kwargs)
writer.write(filename, **write_kwargs)
NVIDIA Tool Extension (NVTX)#
RangePush#
RandRangePush#
RangePop#
RandRangePop#
Mark#
RandMark#
Post-processing#
Activations#
- class monai.transforms.Activations(sigmoid=False, softmax=False, other=None, **kwargs)[source]#
Activation operations, typically Sigmoid or Softmax.
- Parameters:
sigmoid – whether to execute sigmoid function on model output before transform. Defaults to
False.softmax – whether to execute softmax function on model output before transform. Defaults to
False.other – callable function to execute other activation layers, for example: other = lambda x: torch.tanh(x). Defaults to
None.kwargs – additional parameters to torch.softmax (used when
softmax=True). Defaults todim=0, unrecognized parameters will be ignored.
- Raises:
TypeError – When
otheris not anOptional[Callable].
- __call__(img, sigmoid=None, softmax=None, other=None)[source]#
- Parameters:
sigmoid – whether to execute sigmoid function on model output before transform. Defaults to
self.sigmoid.softmax – whether to execute softmax function on model output before transform. Defaults to
self.softmax.other – callable function to execute other activation layers, for example: other = torch.tanh. Defaults to
self.other.
- Raises:
ValueError – When
sigmoid=Trueandsoftmax=True. Incompatible values.TypeError – When
otheris not anOptional[Callable].ValueError – When
self.other=Noneandother=None. Incompatible values.
AsDiscrete#
- class monai.transforms.AsDiscrete(argmax=False, to_onehot=None, threshold=None, rounding=None, **kwargs)[source]#
Convert the input tensor/array into discrete values, possible operations are:
argmax.
threshold input value to binary values.
convert input value to One-Hot format (set
to_one_hot=N, N is the number of classes).round the value to the closest integer.
- Parameters:
argmax – whether to execute argmax function on input data before transform. Defaults to
False.to_onehot – if not None, convert input data into the one-hot format with specified number of classes. Defaults to
None.threshold – if not None, threshold the float values to int number 0 or 1 with specified threshold. Defaults to
None.rounding – if not None, round the data according to the specified option, available options: [“torchrounding”].
kwargs – additional parameters to torch.argmax, monai.networks.one_hot. currently
dim,keepdim,dtypeare supported, unrecognized parameters will be ignored. These default to0,True,torch.floatrespectively.
Example
>>> transform = AsDiscrete(argmax=True) >>> print(transform(np.array([[[0.0, 1.0]], [[2.0, 3.0]]]))) # [[[1.0, 1.0]]]
>>> transform = AsDiscrete(threshold=0.6) >>> print(transform(np.array([[[0.0, 0.5], [0.8, 3.0]]]))) # [[[0.0, 0.0], [1.0, 1.0]]]
>>> transform = AsDiscrete(argmax=True, to_onehot=2, threshold=0.5) >>> print(transform(np.array([[[0.0, 1.0]], [[2.0, 3.0]]]))) # [[[0.0, 0.0]], [[1.0, 1.0]]]
- __call__(img, argmax=None, to_onehot=None, threshold=None, rounding=None)[source]#
- Parameters:
img – the input tensor data to convert, if no channel dimension when converting to One-Hot, will automatically add it.
argmax – whether to execute argmax function on input data before transform. Defaults to
self.argmax.to_onehot – if not None, convert input data into the one-hot format with specified number of classes. Defaults to
self.to_onehot.threshold – if not None, threshold the float values to int number 0 or 1 with specified threshold value. Defaults to
self.threshold.rounding – if not None, round the data according to the specified option, available options: [“torchrounding”].
KeepLargestConnectedComponent#
- class monai.transforms.KeepLargestConnectedComponent(applied_labels=None, is_onehot=None, independent=True, connectivity=None, num_components=1)[source]#
Keeps only the largest connected component in the image. This transform can be used as a post-processing step to clean up over-segment areas in model output.
- The input is assumed to be a channel-first PyTorch Tensor:
1) For not OneHot format data, the values correspond to expected labels, 0 will be treated as background and the over-segment pixels will be set to 0. 2) For OneHot format data, the values should be 0, 1 on each labels, the over-segment pixels will be set to 0 in its channel.
For example: Use with applied_labels=[1], is_onehot=False, connectivity=1:
[1, 0, 0] [0, 0, 0] [0, 1, 1] => [0, 1 ,1] [0, 1, 1] [0, 1, 1]
Use with applied_labels=[1, 2], is_onehot=False, independent=False, connectivity=1:
[0, 0, 1, 0 ,0] [0, 0, 1, 0 ,0] [0, 2, 1, 1 ,1] [0, 2, 1, 1 ,1] [1, 2, 1, 0 ,0] => [1, 2, 1, 0 ,0] [1, 2, 0, 1 ,0] [1, 2, 0, 0 ,0] [2, 2, 0, 0 ,2] [2, 2, 0, 0 ,0]
Use with applied_labels=[1, 2], is_onehot=False, independent=True, connectivity=1:
[0, 0, 1, 0 ,0] [0, 0, 1, 0 ,0] [0, 2, 1, 1 ,1] [0, 2, 1, 1 ,1] [1, 2, 1, 0 ,0] => [0, 2, 1, 0 ,0] [1, 2, 0, 1 ,0] [0, 2, 0, 0 ,0] [2, 2, 0, 0 ,2] [2, 2, 0, 0 ,0]
Use with applied_labels=[1, 2], is_onehot=False, independent=False, connectivity=2:
[0, 0, 1, 0 ,0] [0, 0, 1, 0 ,0] [0, 2, 1, 1 ,1] [0, 2, 1, 1 ,1] [1, 2, 1, 0 ,0] => [1, 2, 1, 0 ,0] [1, 2, 0, 1 ,0] [1, 2, 0, 1 ,0] [2, 2, 0, 0 ,2] [2, 2, 0, 0 ,2]
- __call__(img)[source]#
- Parameters:
img (
Union[ndarray,Tensor]) – shape must be (C, spatial_dim1[, spatial_dim2, …]).- Return type:
Union[ndarray,Tensor]- Returns:
An array with shape (C, spatial_dim1[, spatial_dim2, …]).
- __init__(applied_labels=None, is_onehot=None, independent=True, connectivity=None, num_components=1)[source]#
- Parameters:
applied_labels – Labels for applying the connected component analysis on. If given, voxels whose value is in this list will be analyzed. If None, all non-zero values will be analyzed.
is_onehot – if True, treat the input data as OneHot format data, otherwise, not OneHot format data. default to None, which treats multi-channel data as OneHot and single channel data as not OneHot.
independent – whether to treat
applied_labelsas a union of foreground labels. IfTrue, the connected component analysis will be performed on each foreground label independently and return the intersection of the largest components. IfFalse, the analysis will be performed on the union of foreground labels. default is True.connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. If
None, a full connectivity ofinput.ndimis used. for more details: https://scikit-image.org/docs/dev/api/skimage.measure.html#skimage.measure.label.num_components – The number of largest components to preserve.
DistanceTransformEDT#
- class monai.transforms.DistanceTransformEDT(sampling=None)[source]#
Applies the Euclidean distance transform on the input. Either GPU based with CuPy / cuCIM or CPU based with scipy. To use the GPU implementation, make sure cuCIM is available and that the data is a torch.tensor on a GPU device.
Note that the results of the libraries can differ, so stick to one if possible. For details, check out the SciPy and cuCIM documentation and / or
monai.transforms.utils.distance_transform_edt().- __call__(img)[source]#
- Parameters:
img (
Union[ndarray,Tensor]) – Input image on which the distance transform shall be run. Has to be a channel first array, must have shape: (num_channels, H, W [,D]). Can be of any type but will be converted into binary: 1 wherever image equates to True, 0 elsewhere. Input gets passed channel-wise to the distance-transform, thus results from this function will differ from directly callingdistance_transform_edt()in CuPy or SciPy.sampling – Spacing of elements along each dimension. If a sequence, must be of length equal to the input rank -1; if a single number, this is used for all axes. If not specified, a grid spacing of unity is implied.
- Return type:
Union[ndarray,Tensor]- Returns:
An array with the same shape and data type as img
RemoveSmallObjects#
- class monai.transforms.RemoveSmallObjects(min_size=64, connectivity=1, independent_channels=True, by_measure=False, pixdim=None)[source]#
Use skimage.morphology.remove_small_objects to remove small objects from images. See: https://scikit-image.org/docs/dev/api/skimage.morphology.html#remove-small-objects.
Data should be one-hotted.
- Parameters:
min_size – objects smaller than this size (in number of voxels; or surface area/volume value in whatever units your image is if by_measure is True) are removed.
connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. If
None, a full connectivity ofinput.ndimis used. For more details refer to linked scikit-image documentation.independent_channels – Whether or not to consider channels as independent. If true, then conjoining islands from different labels will be removed if they are below the threshold. If false, the overall size islands made from all non-background voxels will be used.
by_measure – Whether the specified min_size is in number of voxels. if this is True then min_size represents a surface area or volume value of whatever units your image is in (mm^3, cm^2, etc.) default is False. e.g. if min_size is 3, by_measure is True and the units of your data is mm, objects smaller than 3mm^3 are removed.
pixdim – the pixdim of the input image. if a single number, this is used for all axes. If a sequence of numbers, the length of the sequence must be equal to the image dimensions.
Example:
.. code-block:: python from monai.transforms import RemoveSmallObjects, Spacing, Compose from monai.data import MetaTensor data1 = torch.tensor([[[0, 0, 0, 0, 0], [0, 1, 1, 0, 1], [0, 0, 0, 1, 1]]]) affine = torch.as_tensor([[2,0,0,0], [0,1,0,0], [0,0,1,0], [0,0,0,1]], dtype=torch.float64) data2 = MetaTensor(data1, affine=affine) # remove objects smaller than 3mm^3, input is MetaTensor trans = RemoveSmallObjects(min_size=3, by_measure=True) out = trans(data2) # remove objects smaller than 3mm^3, input is not MetaTensor trans = RemoveSmallObjects(min_size=3, by_measure=True, pixdim=(2, 1, 1)) out = trans(data1) # remove objects smaller than 3 (in pixel) trans = RemoveSmallObjects(min_size=3) out = trans(data2) # If the affine of the data is not identity, you can also add Spacing before. trans = Compose([ Spacing(pixdim=(1, 1, 1)), RemoveSmallObjects(min_size=3) ])
LabelFilter#
- class monai.transforms.LabelFilter(applied_labels)[source]#
This transform filters out labels and can be used as a processing step to view only certain labels.
The list of applied labels defines which labels will be kept.
Note
All labels which do not match the applied_labels are set to the background label (0).
For example:
Use LabelFilter with applied_labels=[1, 5, 9]:
[1, 2, 3] [1, 0, 0] [4, 5, 6] => [0, 5 ,0] [7, 8, 9] [0, 0, 9]
- __call__(img)[source]#
Filter the image on the applied_labels.
- Parameters:
img (
Union[ndarray,Tensor]) – Pytorch tensor or numpy array of any shape.- Raises:
NotImplementedError – The provided image was not a Pytorch Tensor or numpy array.
- Return type:
Union[ndarray,Tensor]- Returns:
Pytorch tensor or numpy array of the same shape as the input.
FillHoles#
- class monai.transforms.FillHoles(applied_labels=None, connectivity=None)[source]#
This transform fills holes in the image and can be used to remove artifacts inside segments.
An enclosed hole is defined as a background pixel/voxel which is only enclosed by a single class. The definition of enclosed can be defined with the connectivity parameter:
1-connectivity 2-connectivity diagonal connection close-up [ ] [ ] [ ] [ ] [ ] | \ | / | <- hop 2 [ ]--[x]--[ ] [ ]--[x]--[ ] [x]--[ ] | / | \ hop 1 [ ] [ ] [ ] [ ]
It is possible to define for which labels the hole filling should be applied. The input image is assumed to be a PyTorch Tensor or numpy array with shape [C, spatial_dim1[, spatial_dim2, …]]. If C = 1, then the values correspond to expected labels. If C > 1, then a one-hot-encoding is expected where the index of C matches the label indexing.
Note
The label 0 will be treated as background and the enclosed holes will be set to the neighboring class label.
The performance of this method heavily depends on the number of labels. It is a bit faster if the list of applied_labels is provided. Limiting the number of applied_labels results in a big decrease in processing time.
For example:
Use FillHoles with default parameters:
[1, 1, 1, 2, 2, 2, 3, 3] [1, 1, 1, 2, 2, 2, 3, 3] [1, 0, 1, 2, 0, 0, 3, 0] => [1, 1 ,1, 2, 0, 0, 3, 0] [1, 1, 1, 2, 2, 2, 3, 3] [1, 1, 1, 2, 2, 2, 3, 3]
The hole in label 1 is fully enclosed and therefore filled with label 1. The background label near label 2 and 3 is not fully enclosed and therefore not filled.
- __call__(img)[source]#
Fill the holes in the provided image.
Note
The value 0 is assumed as background label.
- Parameters:
img (
Union[ndarray,Tensor]) – Pytorch Tensor or numpy array of shape [C, spatial_dim1[, spatial_dim2, …]].- Raises:
NotImplementedError – The provided image was not a Pytorch Tensor or numpy array.
- Return type:
Union[ndarray,Tensor]- Returns:
Pytorch Tensor or numpy array of shape [C, spatial_dim1[, spatial_dim2, …]].
- __init__(applied_labels=None, connectivity=None)[source]#
Initialize the connectivity and limit the labels for which holes are filled.
- Parameters:
applied_labels – Labels for which to fill holes. Defaults to None, that is filling holes for all labels.
connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. Defaults to a full connectivity of
input.ndim.
LabelToContour#
- class monai.transforms.LabelToContour(kernel_type='Laplace')[source]#
Return the contour of binary input images that only compose of 0 and 1, with Laplacian kernel set as default for edge detection. Typical usage is to plot the edge of label or segmentation output.
- Parameters:
kernel_type (
str) – the method applied to do edge detection, default is “Laplace”.- Raises:
NotImplementedError – When
kernel_typeis not “Laplace”.
- __call__(img)[source]#
- Parameters:
img (
Union[ndarray,Tensor]) – torch tensor data to extract the contour, with shape: [channels, height, width[, depth]]- Raises:
ValueError – When
imagendim is not one of [3, 4].- Returns:
it’s the binary classification result of whether a pixel is edge or not.
in order to keep the original shape of mask image, we use padding as default.
the edge detection is just approximate because it defects inherent to Laplace kernel, ideally the edge should be thin enough, but now it has a thickness.
- Return type:
A torch tensor with the same shape as img, note
MeanEnsemble#
- class monai.transforms.MeanEnsemble(weights=None)[source]#
Execute mean ensemble on the input data. The input data can be a list or tuple of PyTorch Tensor with shape: [C[, H, W, D]], Or a single PyTorch Tensor with shape: [E, C[, H, W, D]], the E dimension represents the output data from different models. Typically, the input data is model output of segmentation task or classification task. And it also can support to add weights for the input data.
- Parameters:
weights – can be a list or tuple of numbers for input data with shape: [E, C, H, W[, D]]. or a Numpy ndarray or a PyTorch Tensor data. the weights will be added to input data from highest dimension, for example: 1. if the weights only has 1 dimension, it will be added to the E dimension of input data. 2. if the weights has 2 dimensions, it will be added to E and C dimensions. it’s a typical practice to add weights for different classes: to ensemble 3 segmentation model outputs, every output has 4 channels(classes), so the input data shape can be: [3, 4, H, W, D]. and add different weights for different classes, so the weights shape can be: [3, 4]. for example: weights = [[1, 2, 3, 4], [4, 3, 2, 1], [1, 1, 1, 1]].
ProbNMS#
- class monai.transforms.ProbNMS(spatial_dims=2, sigma=0.0, prob_threshold=0.5, box_size=48)[source]#
Performs probability based non-maximum suppression (NMS) on the probabilities map via iteratively selecting the coordinate with highest probability and then move it as well as its surrounding values. The remove range is determined by the parameter box_size. If multiple coordinates have the same highest probability, only one of them will be selected.
- Parameters:
spatial_dims – number of spatial dimensions of the input probabilities map. Defaults to 2.
sigma – the standard deviation for gaussian filter. It could be a single value, or spatial_dims number of values. Defaults to 0.0.
prob_threshold – the probability threshold, the function will stop searching if the highest probability is no larger than the threshold. The value should be no less than 0.0. Defaults to 0.5.
box_size – the box size (in pixel) to be removed around the pixel with the maximum probability. It can be an integer that defines the size of a square or cube, or a list containing different values for each dimensions. Defaults to 48.
- Returns:
a list of selected lists, where inner lists contain probability and coordinates. For example, for 3D input, the inner lists are in the form of [probability, x, y, z].
- Raises:
ValueError – When
prob_thresholdis less than 0.0.ValueError – When
box_sizeis a list or tuple, and its length is not equal to spatial_dims.ValueError – When
box_sizehas a less than 1 value.
SobelGradients#
- class monai.transforms.SobelGradients(kernel_size=3, spatial_axes=None, normalize_kernels=True, normalize_gradients=False, padding_mode='reflect', dtype=torch.float32)[source]#
Calculate Sobel gradients of a grayscale image with the shape of CxH[xWxDx…] or BxH[xWxDx…].
- Parameters:
kernel_size – the size of the Sobel kernel. Defaults to 3.
spatial_axes – the axes that define the direction of the gradient to be calculated. It calculate the gradient along each of the provide axis. By default it calculate the gradient for all spatial axes.
normalize_kernels – if normalize the Sobel kernel to provide proper gradients. Defaults to True.
normalize_gradients – if normalize the output gradient to 0 and 1. Defaults to False.
padding_mode – the padding mode of the image when convolving with Sobel kernels. Defaults to “reflect”. Acceptable values are
'zeros','reflect','replicate'or'circular'. Seetorch.nn.Conv1d()for more information.dtype – kernel data type (torch.dtype). Defaults to torch.float32.
- __call__(image)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
VoteEnsemble#
- class monai.transforms.VoteEnsemble(num_classes=None)[source]#
Execute vote ensemble on the input data. The input data can be a list or tuple of PyTorch Tensor with shape: [C[, H, W, D]], Or a single PyTorch Tensor with shape: [E[, C, H, W, D]], the E dimension represents the output data from different models. Typically, the input data is model output of segmentation task or classification task.
Note
This vote transform expects the input data is discrete values. It can be multiple channels data in One-Hot format or single channel data. It will vote to select the most common data between items. The output data has the same shape as every item of the input data.
- Parameters:
num_classes – if the input is single channel data instead of One-Hot, we can’t get class number from channel, need to explicitly specify the number of classes to vote.
Regularization#
CutMix#
- class monai.transforms.CutMix(batch_size, alpha=1.0)[source]#
- CutMix augmentation as described in:
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features, ICCV 2019
Class derived from
monai.transforms.Mixer. See corresponding documentation for details on the constructor parameters. Here, alpha not only determines the mixing weight but also the size of the random rectangles used during for mixing. Please refer to the paper for details.The most common use case is something close to:
cm = CutMix(batch_size=8, alpha=0.5) for batch in loader: images, labels = batch augimg, auglabels = cm(images, labels) output = model(augimg) loss = loss_function(output, auglabels) ...
- __call__(data, labels=None)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
CutOut#
- class monai.transforms.CutOut(batch_size, alpha=1.0)[source]#
Cutout as described in the paper: Terrance DeVries, Graham W. Taylor. Improved Regularization of Convolutional Neural Networks with Cutout, arXiv:1708.04552
Class derived from
monai.transforms.Mixer. See corresponding documentation for details on the constructor parameters. Here, alpha not only determines the mixing weight but also the size of the random rectangles being cut put. Please refer to the paper for details.- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
MixUp#
- class monai.transforms.MixUp(batch_size, alpha=1.0)[source]#
MixUp as described in: Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, David Lopez-Paz. mixup: Beyond Empirical Risk Minimization, ICLR 2018
Class derived from
monai.transforms.Mixer. See corresponding documentation for details on the constructor parameters.- __call__(data, labels=None)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
Signal#
SignalRandDrop#
SignalRandScale#
SignalRandShift#
- class monai.transforms.SignalRandShift(mode='wrap', filling=0.0, boundaries=(-1.0, 1.0))[source]#
Apply a random shift on a signal
- __call__(signal)[source]#
- Parameters:
signal (
Union[ndarray,Tensor]) – input 1 dimension signal to be shifted- Return type:
Union[ndarray,Tensor]
- __init__(mode='wrap', filling=0.0, boundaries=(-1.0, 1.0))[source]#
- Parameters:
mode – define how the extension of the input array is done beyond its boundaries, see for more details : https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.shift.html.
filling – value to fill past edges of input if mode is ‘constant’. Default is 0.0. see for mode details : https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.shift.html.
boundaries – list defining lower and upper boundaries for the signal shift, default :
[-1.0, 1.0]
SignalRandAddSine#
- class monai.transforms.SignalRandAddSine(boundaries=(0.1, 0.3), frequencies=(0.001, 0.02))[source]#
Add a random sinusoidal signal to the input signal
- __call__(signal)[source]#
- Parameters:
signal (
Union[ndarray,Tensor]) – input 1 dimension signal to which sinusoidal signal will be added- Return type:
Union[ndarray,Tensor]
- __init__(boundaries=(0.1, 0.3), frequencies=(0.001, 0.02))[source]#
- Parameters:
boundaries (
Sequence[float]) – list defining lower and upper boundaries for the sinusoidal magnitude, lower and upper values need to be positive ,default :[0.1, 0.3]frequencies (
Sequence[float]) – list defining lower and upper frequencies for sinusoidal signal generation ,default :[0.001, 0.02]
SignalRandAddSquarePulse#
- class monai.transforms.SignalRandAddSquarePulse(boundaries=(0.01, 0.2), frequencies=(0.001, 0.02))[source]#
Add a random square pulse signal to the input signal
- __call__(signal)[source]#
- Parameters:
signal (
Union[ndarray,Tensor]) – input 1 dimension signal to which square pulse will be added- Return type:
Union[ndarray,Tensor]
- __init__(boundaries=(0.01, 0.2), frequencies=(0.001, 0.02))[source]#
- Parameters:
boundaries (
Sequence[float]) – list defining lower and upper boundaries for the square pulse magnitude, lower and upper values need to be positive , default :[0.01, 0.2]frequencies (
Sequence[float]) – list defining lower and upper frequencies for the square pulse signal generation , default :[0.001, 0.02]
SignalRandAddGaussianNoise#
- class monai.transforms.SignalRandAddGaussianNoise(boundaries=(0.001, 0.02))[source]#
Add a random gaussian noise to the input signal
SignalRandAddSinePartial#
- class monai.transforms.SignalRandAddSinePartial(boundaries=(0.1, 0.3), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
Add a random partial sinusoidal signal to the input signal
- __call__(signal)[source]#
- Parameters:
signal (
Union[ndarray,Tensor]) – input 1 dimension signal to which a partial sinusoidal signaladded (will be)
- Return type:
Union[ndarray,Tensor]
- __init__(boundaries=(0.1, 0.3), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
- Parameters:
boundaries (
Sequence[float]) – list defining lower and upper boundaries for the sinusoidal magnitude, lower and upper values need to be positive , default :[0.1, 0.3]frequencies (
Sequence[float]) – list defining lower and upper frequencies for sinusoidal signal generation , default :[0.001, 0.02]fraction (
Sequence[float]) – list defining lower and upper boundaries for partial signal generation default :[0.01, 0.2]
SignalRandAddSquarePulsePartial#
- class monai.transforms.SignalRandAddSquarePulsePartial(boundaries=(0.01, 0.2), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
Add a random partial square pulse to a signal
- __call__(signal)[source]#
- Parameters:
signal (
Union[ndarray,Tensor]) – input 1 dimension signal to which a partial square pulse will be added- Return type:
Union[ndarray,Tensor]
- __init__(boundaries=(0.01, 0.2), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
- Parameters:
boundaries (
Sequence[float]) – list defining lower and upper boundaries for the square pulse magnitude, lower and upper values need to be positive , default :[0.01, 0.2]frequencies (
Sequence[float]) – list defining lower and upper frequencies for square pulse signal generation example :[0.001, 0.02]fraction (
Sequence[float]) – list defining lower and upper boundaries for partial square pulse generation default:[0.01, 0.2]
SignalFillEmpty#
SignalRemoveFrequency#
- class monai.transforms.SignalRemoveFrequency(frequency=None, quality_factor=None, sampling_freq=None)[source]#
Remove a frequency from a signal
- __call__(signal)[source]#
- Parameters:
signal (
ndarray) – signal to be frequency removed- Return type:
Any
- __init__(frequency=None, quality_factor=None, sampling_freq=None)[source]#
- Parameters:
frequency – frequency to be removed from the signal
quality_factor – quality factor for notch filter see : https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.iirnotch.html
sampling_freq – sampling frequency of the input signal
SignalContinuousWavelet#
- class monai.transforms.SignalContinuousWavelet(type='mexh', length=125.0, frequency=500.0)[source]#
Generate continuous wavelet transform of a signal
- __call__(signal)[source]#
- Parameters:
signal (
ndarray) – signal for which to generate continuous wavelet transform- Return type:
Any
- __init__(type='mexh', length=125.0, frequency=500.0)[source]#
- Parameters:
type (
str) – mother wavelet type. Available options are: {"mexh","morl","cmorB-C", ,"gausP"}see – https://pywavelets.readthedocs.io/en/latest/ref/cwt.html
length (
float) – expected length, default125.0frequency (
float) – signal frequency, default500.0
Spatial#
SpatialResample#
- class monai.transforms.SpatialResample(mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, lazy=False)[source]#
Resample input image from the orientation/spacing defined by
src_affineaffine matrix into the ones specified bydst_affineaffine matrix.Internally this transform computes the affine transform matrix from
src_affinetodst_affine, byxform = linalg.solve(src_affine, dst_affine), and callmonai.transforms.Affinewithxform.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, dst_affine=None, spatial_size=None, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- Parameters:
img – input image to be resampled. It currently supports channel-first arrays with at most three spatial dimensions.
dst_affine – destination affine matrix. Defaults to
None, which means the same as img.affine. the shape should be (r+1, r+1) where r is the spatial rank ofimg. when dst_affine and spatial_size are None, the input will be returned without resampling, but the data type will be float32.spatial_size – output image spatial size. if spatial_size and self.spatial_size are not defined, the transform will compute a spatial size automatically containing the previous field of view. if spatial_size is
-1are the transform will use the corresponding input img size.mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – Geometrically, we consider the pixels of the input as squares rather than points. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html Defaults to
None, effectively using the value of self.align_corners.dtype – data type for resampling computation. Defaults to
self.dtypeornp.float64(for best precision). IfNone, use the data type of input data. To be compatible with other modules, the output data type is always float32.lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
The spatial rank is determined by the smallest among
img.ndim -1,len(src_affine) - 1, and3.When both
monai.config.USE_COMPILEDandalign_cornersare set toTrue, MONAI’s resampling implementation will be used. Set dst_affine and spatial_size to None to turn off the resampling step.
- __init__(mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, lazy=False)[source]#
- Parameters:
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldtype – data type for resampling computation. Defaults to
float64for best precision. IfNone, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32.lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
ResampleToMatch#
- class monai.transforms.ResampleToMatch(mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, lazy=False)[source]#
Resample an image to match given metadata. The affine matrix will be aligned, and the size of the output image will match.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, img_dst, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- Parameters:
img – input image to be resampled to match
img_dst. It currently supports channel-first arrays with at most three spatial dimensions.mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – Geometrically, we consider the pixels of the input as squares rather than points. Defaults to
None, effectively using the value of self.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmldtype – data type for resampling computation. Defaults to
self.dtypeornp.float64(for best precision). IfNone, use the data type of input data. To be compatible with other modules, the output data type is always float32.lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Raises:
ValueError – When the affine matrix of the source image is not invertible.
- Returns:
Resampled input tensor or MetaTensor.
Spacing#
- class monai.transforms.Spacing(pixdim, diagonal=False, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, scale_extent=False, recompute_affine=False, min_pixdim=None, max_pixdim=None, lazy=False)[source]#
Resample input image into the specified pixdim.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data_array, mode=None, padding_mode=None, align_corners=None, dtype=None, scale_extent=None, output_spatial_shape=None, lazy=None)[source]#
- Parameters:
data_array – in shape (num_channels, H[, W, …]).
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"self.mode". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"self.padding_mode". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – Geometrically, we consider the pixels of the input as squares rather than points. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html Defaults to
None, effectively using the value of self.align_corners.dtype – data type for resampling computation. Defaults to
self.dtype. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32.scale_extent – whether the scale is computed based on the spacing or the full extent of voxels, The option is ignored if output spatial size is specified when calling this transform. See also:
monai.data.utils.compute_shape_offset(). When this is True, align_corners should be True because compute_shape_offset already provides the corner alignment shift/scaling.output_spatial_shape – specify the shape of the output data_array. This is typically useful for the inverse of Spacingd where sometimes we could not compute the exact shape due to the quantization error with the affine.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Raises:
ValueError – When
data_arrayhas no spatial dimensions.ValueError – When
pixdimis nonpositive.
- Returns:
data tensor or MetaTensor (resampled into self.pixdim).
- __init__(pixdim, diagonal=False, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, scale_extent=False, recompute_affine=False, min_pixdim=None, max_pixdim=None, lazy=False)[source]#
- Parameters:
pixdim – output voxel spacing. if providing a single number, will use it for the first dimension. items of the pixdim sequence map to the spatial dimensions of input image, if length of pixdim sequence is longer than image spatial dimensions, will ignore the longer part, if shorter, will pad with the last value. For example, for 3D image if pixdim is [1.0, 2.0] it will be padded to [1.0, 2.0, 2.0] if the components of the pixdim are non-positive values, the transform will use the corresponding components of the original pixdim, which is computed from the affine matrix of input image.
diagonal –
whether to resample the input to have a diagonal affine matrix. If True, the input data is resampled to the following affine:
np.diag((pixdim_0, pixdim_1, ..., pixdim_n, 1))
This effectively resets the volume to the world coordinate system (RAS+ in nibabel). The original orientation, rotation, shearing are not preserved.
If False, this transform preserves the axes orientation, orthogonal rotation and translation components from the original affine. This option will not flip/swap axes of the original data.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – Geometrically, we consider the pixels of the input as squares rather than points. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – data type for resampling computation. Defaults to
float64for best precision. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32.scale_extent – whether the scale is computed based on the spacing or the full extent of voxels, default False. The option is ignored if output spatial size is specified when calling this transform. See also:
monai.data.utils.compute_shape_offset(). When this is True, align_corners should be True because compute_shape_offset already provides the corner alignment shift/scaling.recompute_affine – whether to recompute affine based on the output shape. The affine computed analytically does not reflect the potential quantization errors in terms of the output shape. Set this flag to True to recompute the output affine based on the actual pixdim. Default to
False.min_pixdim – minimal input spacing to be resampled. If provided, input image with a larger spacing than this value will be kept in its original spacing (not be resampled to pixdim). Set it to None to use the value of pixdim. Default to None.
max_pixdim – maximal input spacing to be resampled. If provided, input image with a smaller spacing than this value will be kept in its original spacing (not be resampled to pixdim). Set it to None to use the value of pixdim. Default to None.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
Orientation#
- class monai.transforms.Orientation(axcodes=None, as_closest_canonical=False, labels=(('L', 'R'), ('P', 'A'), ('I', 'S')), lazy=False)[source]#
Change the input image’s orientation into the specified based on axcodes.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data_array, lazy=None)[source]#
If input type is MetaTensor, original affine is extracted with data_array.affine. If input type is torch.Tensor, original affine is assumed to be identity.
- Parameters:
data_array – in shape (num_channels, H[, W, …]).
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Raises:
ValueError – When
data_arrayhas no spatial dimensions.ValueError – When
axcodesspatiality differs fromdata_array.
- Returns:
- data_array [reoriented in self.axcodes]. Output type will be MetaTensor
unless get_track_meta() == False, in which case it will be torch.Tensor.
- __init__(axcodes=None, as_closest_canonical=False, labels=(('L', 'R'), ('P', 'A'), ('I', 'S')), lazy=False)[source]#
- Parameters:
axcodes – N elements sequence for spatial ND input’s orientation. e.g. axcodes=’RAS’ represents 3D orientation: (Left, Right), (Posterior, Anterior), (Inferior, Superior). default orientation labels options are: ‘L’ and ‘R’ for the first dimension, ‘P’ and ‘A’ for the second, ‘I’ and ‘S’ for the third.
as_closest_canonical – if True, load the image as closest to canonical axis format.
labels – optional, None or sequence of (2,) sequences (2,) sequences are labels for (beginning, end) of output axis. Defaults to
(('L', 'R'), ('P', 'A'), ('I', 'S')).lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- Raises:
ValueError – When
axcodes=Noneandas_closest_canonical=True. Incompatible values.
See Also: nibabel.orientations.ornt2axcodes.
RandRotate#
- class monai.transforms.RandRotate(range_x=0.0, range_y=0.0, range_z=0.0, prob=0.1, keep_size=True, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float32'>, lazy=False)[source]#
Randomly rotate the input arrays.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
range_x – Range of rotation angle in radians in the plane defined by the first and second axes. If single number, angle is uniformly sampled from (-range_x, range_x).
range_y – Range of rotation angle in radians in the plane defined by the first and third axes. If single number, angle is uniformly sampled from (-range_y, range_y). only work for 3D data.
range_z – Range of rotation angle in radians in the plane defined by the second and third axes. If single number, angle is uniformly sampled from (-range_z, range_z). only work for 3D data.
prob – Probability of rotation.
keep_size – If it is False, the output shape is adapted so that the input array is contained completely in the output. If it is True, the output shape is the same as the input. Default is True.
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32.lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, randomize=True, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape 2D: (nchannels, H, W), or 3D: (nchannels, H, W, D).
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – Defaults to
self.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmldtype – data type for resampling computation. Defaults to
self.dtype. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32.randomize – whether to execute randomize() function first, default to True.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
RandFlip#
- class monai.transforms.RandFlip(prob=0.1, spatial_axis=None, lazy=False)[source]#
Randomly flips the image along axes. Preserves shape. See numpy.flip for additional details. https://docs.scipy.org/doc/numpy/reference/generated/numpy.flip.html
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
prob – Probability of flipping.
spatial_axis – Spatial axes along which to flip over. Default is None.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(img, randomize=True, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: (num_channels, H[, W, …, ]),
randomize – whether to execute randomize() function first, default to True.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
RandAxisFlip#
- class monai.transforms.RandAxisFlip(prob=0.1, lazy=False)[source]#
Randomly select a spatial axis and flip along it. See numpy.flip for additional details. https://docs.scipy.org/doc/numpy/reference/generated/numpy.flip.html
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
prob (
float) – Probability of flipping.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(img, randomize=True, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: (num_channels, H[, W, …, ])
randomize – whether to execute randomize() function first, default to True.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(data)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
RandZoom#
- class monai.transforms.RandZoom(prob=0.1, min_zoom=0.9, max_zoom=1.1, mode=area, padding_mode=edge, align_corners=None, dtype=torch.float32, keep_size=True, lazy=False, **kwargs)[source]#
Randomly zooms input arrays with given probability within given zoom range.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
prob – Probability of zooming.
min_zoom – Min zoom factor. Can be float or sequence same size as image. If a float, select a random factor from [min_zoom, max_zoom] then apply to all spatial dims to keep the original spatial shape ratio. If a sequence, min_zoom should contain one value for each spatial axis. If 2 values provided for 3D data, use the first value for both H & W dims to keep the same zoom ratio.
max_zoom – Max zoom factor. Can be float or sequence same size as image. If a float, select a random factor from [min_zoom, max_zoom] then apply to all spatial dims to keep the original spatial shape ratio. If a sequence, max_zoom should contain one value for each spatial axis. If 2 values provided for 3D data, use the first value for both H & W dims to keep the same zoom ratio.
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults to"area". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". The mode to pad data after zooming. See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: None. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html
dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data.keep_size – Should keep original size (pad if needed), default is True.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, randomize=True, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape 2D: (nchannels, H, W), or 3D: (nchannels, H, W, D).
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"}, the interpolation mode. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". The mode to pad data after zooming. See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Defaults to
self.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmldtype – data type for resampling computation. Defaults to
self.dtype. If None, use the data type of input data.randomize – whether to execute randomize() function first, default to True.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- randomize(img)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
Affine#
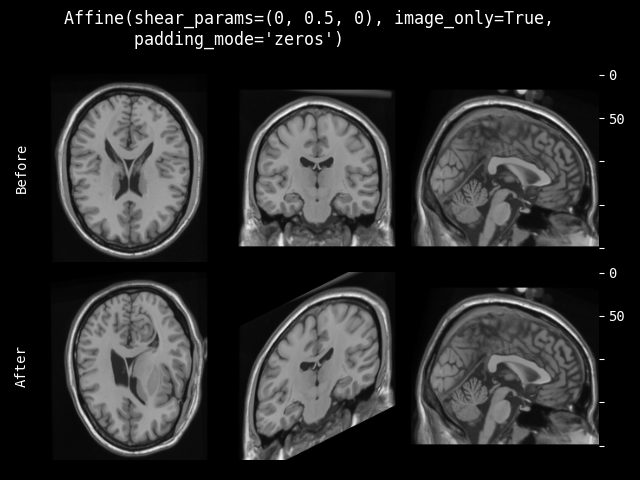
- class monai.transforms.Affine(rotate_params=None, shear_params=None, translate_params=None, scale_params=None, affine=None, spatial_size=None, mode=bilinear, padding_mode=reflection, normalized=False, device=None, dtype=<class 'numpy.float32'>, align_corners=False, image_only=False, lazy=False)[source]#
Transform
imggiven the affine parameters. A tutorial is available: Project-MONAI/tutorials.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, spatial_size=None, mode=None, padding_mode=None, lazy=None)[source]#
- Parameters:
img – shape must be (num_channels, H, W[, D]),
spatial_size – output image spatial size. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if img has two spatial dimensions, spatial_size should have 2 elements [h, w]. if img has three spatial dimensions, spatial_size should have 3 elements [h, w, d].
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmllazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- __init__(rotate_params=None, shear_params=None, translate_params=None, scale_params=None, affine=None, spatial_size=None, mode=bilinear, padding_mode=reflection, normalized=False, device=None, dtype=<class 'numpy.float32'>, align_corners=False, image_only=False, lazy=False)[source]#
The affine transformations are applied in rotate, shear, translate, scale order.
- Parameters:
rotate_params – a rotation angle in radians, a scalar for 2D image, a tuple of 3 floats for 3D. Defaults to no rotation.
shear_params –
shearing factors for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ] a tuple of 2 floats for 2D, a tuple of 6 floats for 3D. Defaults to no shearing.
translate_params – a tuple of 2 floats for 2D, a tuple of 3 floats for 3D. Translation is in pixel/voxel relative to the center of the input image. Defaults to no translation.
scale_params – scale factor for every spatial dims. a tuple of 2 floats for 2D, a tuple of 3 floats for 3D. Defaults to 1.0.
affine – If applied, ignore the params (rotate_params, etc.) and use the supplied matrix. Should be square with each side = num of image spatial dimensions + 1.
spatial_size – output image spatial size. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"reflection". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlnormalized – indicating whether the provided affine is defined to include a normalization transform converting the coordinates from [-(size-1)/2, (size-1)/2] (defined in
create_grid) to [0, size - 1] or [-1, 1] in order to be compatible with the underlying resampling API. If normalized=False, additional coordinate normalization will be applied before resampling. See also:monai.networks.utils.normalize_transform().device – device on which the tensor will be allocated.
dtype – data type for resampling computation. Defaults to
float32. IfNone, use the data type of input data. To be compatible with other modules, the output data type is always float32.align_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
image_only – if True return only the image volume, otherwise return (image, affine).
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
Resample#
- class monai.transforms.Resample(mode=bilinear, padding_mode=border, norm_coords=True, device=None, align_corners=False, dtype=<class 'numpy.float64'>)[source]#
- __call__(img, grid=None, mode=None, padding_mode=None, dtype=None, align_corners=None)[source]#
- Parameters:
img – shape must be (num_channels, H, W[, D]).
grid – shape must be (3, H, W) for 2D or (4, H, W, D) for 3D. if
norm_coordsis True, the grid values must be in [-(size-1)/2, (size-1)/2]. ifUSE_COMPILED=Trueandnorm_coords=False, grid values must be in [0, size-1]. ifUSE_COMPILED=Falseandnorm_coords=False, grid values must be in [-1, 1].mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When USE_COMPILED is True, this argument uses"nearest","bilinear","bicubic"to indicate 0, 1, 3 order interpolations. See also: https://docs.monai.io/en/stable/networks.html#grid-pull (experimental). When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When USE_COMPILED is True, this argument uses an integer to represent the padding mode. See also: https://docs.monai.io/en/stable/networks.html#grid-pull (experimental). When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldtype – data type for resampling computation. Defaults to
self.dtype. To be compatible with other modules, the output data type is always float32.align_corners – Defaults to
self.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
See also
monai.config.USE_COMPILED
- __init__(mode=bilinear, padding_mode=border, norm_coords=True, device=None, align_corners=False, dtype=<class 'numpy.float64'>)[source]#
computes output image using values from img, locations from grid using pytorch. supports spatially 2D or 3D (num_channels, H, W[, D]).
- Parameters:
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When USE_COMPILED is True, this argument uses"nearest","bilinear","bicubic"to indicate 0, 1, 3 order interpolations. See also: https://docs.monai.io/en/stable/networks.html#grid-pull (experimental). When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When USE_COMPILED is True, this argument uses an integer to represent the padding mode. See also: https://docs.monai.io/en/stable/networks.html#grid-pull (experimental). When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlnorm_coords – whether to normalize the coordinates from [-(size-1)/2, (size-1)/2] to [0, size - 1] (for
monai/csrcimplementation) or [-1, 1] (for torchgrid_sampleimplementation) to be compatible with the underlying resampling API.device – device on which the tensor will be allocated.
align_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – data type for resampling computation. Defaults to
float64for best precision. IfNone, use the data type of input data. To be compatible with other modules, the output data type is always float32.
RandAffine#
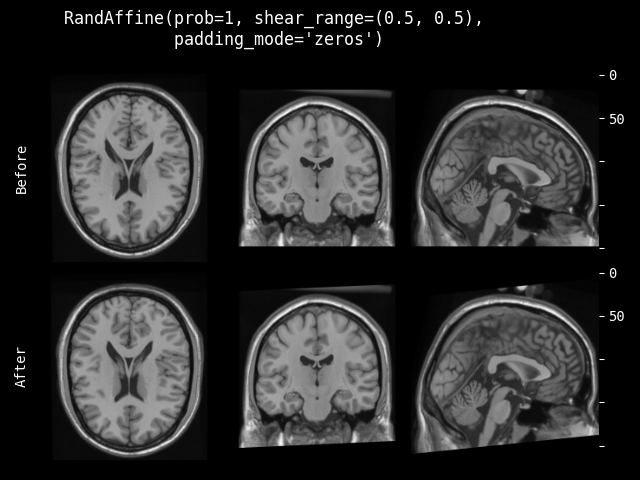
- class monai.transforms.RandAffine(prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, cache_grid=False, device=None, lazy=False)[source]#
Random affine transform. A tutorial is available: Project-MONAI/tutorials.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, spatial_size=None, mode=None, padding_mode=None, randomize=True, grid=None, lazy=None)[source]#
- Parameters:
img – shape must be (num_channels, H, W[, D]),
spatial_size – output image spatial size. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if img has two spatial dimensions, spatial_size should have 2 elements [h, w]. if img has three spatial dimensions, spatial_size should have 3 elements [h, w, d].
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – whether to execute randomize() function first, default to True.
grid – precomputed grid to be used (mainly to accelerate RandAffined).
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- __init__(prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, cache_grid=False, device=None, lazy=False)[source]#
- Parameters:
prob – probability of returning a randomized affine grid. defaults to 0.1, with 10% chance returns a randomized grid.
rotate_range – angle range in radians. If element i is a pair of (min, max) values, then uniform[-rotate_range[i][0], rotate_range[i][1]) will be used to generate the rotation parameter for the i`th spatial dimension. If not, `uniform[-rotate_range[i], rotate_range[i]) will be used. This can be altered on a per-dimension basis. E.g., ((0,3), 1, …): for dim0, rotation will be in range [0, 3], and for dim1 [-1, 1] will be used. Setting a single value will use [-x, x] for dim0 and nothing for the remaining dimensions.
shear_range –
shear range with format matching rotate_range, it defines the range to randomly select shearing factors(a tuple of 2 floats for 2D, a tuple of 6 floats for 3D) for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – translate range with format matching rotate_range, it defines the range to randomly select pixel/voxel to translate for every spatial dims.
scale_range – scaling range with format matching rotate_range. it defines the range to randomly select the scale factor to translate for every spatial dims. A value of 1.0 is added to the result. This allows 0 to correspond to no change (i.e., a scaling of 1.0).
spatial_size – output image spatial size. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults tobilinear. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toreflection. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlcache_grid – whether to cache the identity sampling grid. If the spatial size is not dynamically defined by input image, enabling this option could accelerate the transform.
device – device on which the tensor will be allocated.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
See also
RandAffineGridfor the random affine parameters configurations.Affinefor the affine transformation parameters configurations.
- get_identity_grid(spatial_size, lazy)[source]#
Return a cached or new identity grid depends on the availability.
- Parameters:
spatial_size (
Sequence[int]) – non-dynamic spatial size
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandDeformGrid#
- class monai.transforms.RandDeformGrid(spacing, magnitude_range, device=None)[source]#
Generate random deformation grid.
- __call__(spatial_size)[source]#
- Parameters:
spatial_size (
Sequence[int]) – spatial size of the grid.- Return type:
Tensor
- __init__(spacing, magnitude_range, device=None)[source]#
- Parameters:
spacing – spacing of the grid in 2D or 3D. e.g., spacing=(1, 1) indicates pixel-wise deformation in 2D, spacing=(1, 1, 1) indicates voxel-wise deformation in 3D, spacing=(2, 2) indicates deformation field defined on every other pixel in 2D.
magnitude_range – the random offsets will be generated from uniform[magnitude[0], magnitude[1]).
device – device to store the output grid data.
- randomize(grid_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
AffineGrid#
- class monai.transforms.AffineGrid(rotate_params=None, shear_params=None, translate_params=None, scale_params=None, device=None, dtype=<class 'numpy.float32'>, align_corners=False, affine=None, lazy=False)[source]#
Affine transforms on the coordinates.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
rotate_params – a rotation angle in radians, a scalar for 2D image, a tuple of 3 floats for 3D. Defaults to no rotation.
shear_params –
shearing factors for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ] a tuple of 2 floats for 2D, a tuple of 6 floats for 3D. Defaults to no shearing.
translate_params – a tuple of 2 floats for 2D, a tuple of 3 floats for 3D. Translation is in pixel/voxel relative to the center of the input image. Defaults to no translation.
scale_params – scale factor for every spatial dims. a tuple of 2 floats for 2D, a tuple of 3 floats for 3D. Defaults to 1.0.
dtype – data type for the grid computation. Defaults to
float32. IfNone, use the data type of input data (if grid is provided).device – device on which the tensor will be allocated, if a new grid is generated.
align_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
affine – If applied, ignore the params (rotate_params, etc.) and use the supplied matrix. Should be square with each side = num of image spatial dimensions + 1.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(spatial_size=None, grid=None, lazy=None)[source]#
The grid can be initialized with a spatial_size parameter, or provided directly as grid. Therefore, either spatial_size or grid must be provided. When initialising from spatial_size, the backend “torch” will be used.
- Parameters:
spatial_size – output grid size.
grid – grid to be transformed. Shape must be (3, H, W) for 2D or (4, H, W, D) for 3D.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Raises:
ValueError – When
grid=Noneandspatial_size=None. Incompatible values.
RandAffineGrid#
- class monai.transforms.RandAffineGrid(rotate_range=None, shear_range=None, translate_range=None, scale_range=None, device=None, dtype=<class 'numpy.float32'>, lazy=False)[source]#
Generate randomised affine grid.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(spatial_size=None, grid=None, randomize=True, lazy=None)[source]#
- Parameters:
spatial_size – output grid size.
grid – grid to be transformed. Shape must be (3, H, W) for 2D or (4, H, W, D) for 3D.
randomize – boolean as to whether the grid parameters governing the grid should be randomized.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a 2D (3xHxW) or 3D (4xHxWxD) grid.
- __init__(rotate_range=None, shear_range=None, translate_range=None, scale_range=None, device=None, dtype=<class 'numpy.float32'>, lazy=False)[source]#
- Parameters:
rotate_range – angle range in radians. If element i is a pair of (min, max) values, then uniform[-rotate_range[i][0], rotate_range[i][1]) will be used to generate the rotation parameter for the i`th spatial dimension. If not, `uniform[-rotate_range[i], rotate_range[i]) will be used. This can be altered on a per-dimension basis. E.g., ((0,3), 1, …): for dim0, rotation will be in range [0, 3], and for dim1 [-1, 1] will be used. Setting a single value will use [-x, x] for dim0 and nothing for the remaining dimensions.
shear_range –
shear range with format matching rotate_range, it defines the range to randomly select shearing factors(a tuple of 2 floats for 2D, a tuple of 6 floats for 3D) for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – translate range with format matching rotate_range, it defines the range to randomly select voxels to translate for every spatial dims.
scale_range – scaling range with format matching rotate_range. it defines the range to randomly select the scale factor to translate for every spatial dims. A value of 1.0 is added to the result. This allows 0 to correspond to no change (i.e., a scaling of 1.0).
device – device to store the output grid data.
dtype – data type for the grid computation. Defaults to
np.float32. IfNone, use the data type of input data (if grid is provided).lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
GridDistortion#
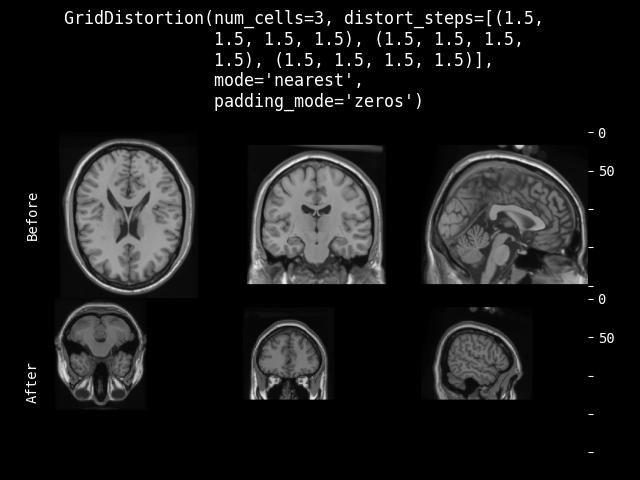
- class monai.transforms.GridDistortion(num_cells, distort_steps, mode=bilinear, padding_mode=border, device=None)[source]#
- __call__(img, distort_steps=None, mode=None, padding_mode=None)[source]#
- Parameters:
img – shape must be (num_channels, H, W[, D]).
distort_steps – This argument is a list of tuples, where each tuple contains the distort steps of the corresponding dimensions (in the order of H, W[, D]). The length of each tuple equals to num_cells + 1. Each value in the tuple represents the distort step of the related cell.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html
- __init__(num_cells, distort_steps, mode=bilinear, padding_mode=border, device=None)[source]#
Grid distortion transform. Refer to: albumentations-team/albumentations
- Parameters:
num_cells – number of grid cells on each dimension.
distort_steps – This argument is a list of tuples, where each tuple contains the distort steps of the corresponding dimensions (in the order of H, W[, D]). The length of each tuple equals to num_cells + 1. Each value in the tuple represents the distort step of the related cell.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – device on which the tensor will be allocated.
RandGridDistortion#
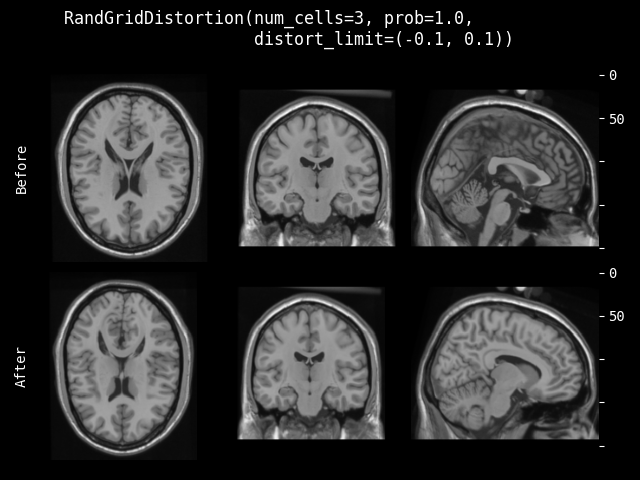
- class monai.transforms.RandGridDistortion(num_cells=5, prob=0.1, distort_limit=(-0.03, 0.03), mode=bilinear, padding_mode=border, device=None)[source]#
- __call__(img, mode=None, padding_mode=None, randomize=True)[source]#
- Parameters:
img – shape must be (num_channels, H, W[, D]).
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – whether to shuffle the random factors using randomize(), default to True.
- __init__(num_cells=5, prob=0.1, distort_limit=(-0.03, 0.03), mode=bilinear, padding_mode=border, device=None)[source]#
Random grid distortion transform. Refer to: albumentations-team/albumentations
- Parameters:
num_cells – number of grid cells on each dimension.
prob – probability of returning a randomized grid distortion transform. Defaults to 0.1.
distort_limit – range to randomly distort. If single number, distort_limit is picked from (-distort_limit, distort_limit). Defaults to (-0.03, 0.03).
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – device on which the tensor will be allocated.
- randomize(spatial_shape)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
Rand2DElastic#
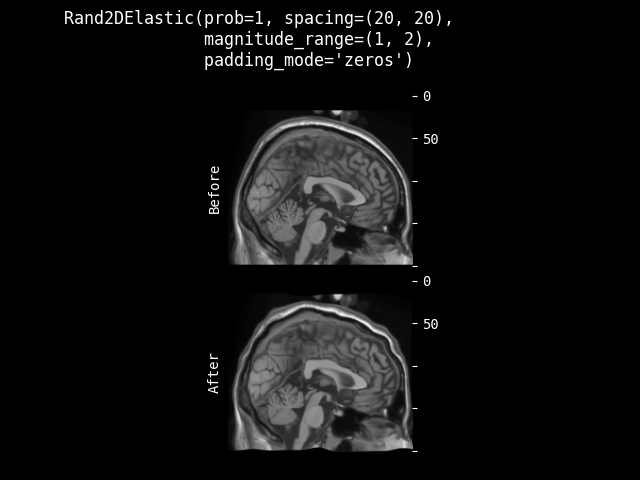
- class monai.transforms.Rand2DElastic(spacing, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
Random elastic deformation and affine in 2D. A tutorial is available: Project-MONAI/tutorials.
- __call__(img, spatial_size=None, mode=None, padding_mode=None, randomize=True)[source]#
- Parameters:
img – shape must be (num_channels, H, W),
spatial_size – specifying output image spatial size [h, w]. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – whether to execute randomize() function first, default to True.
- __init__(spacing, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
- Parameters:
spacing – distance in between the control points.
magnitude_range – the random offsets will be generated from
uniform[magnitude[0], magnitude[1]).prob – probability of returning a randomized elastic transform. defaults to 0.1, with 10% chance returns a randomized elastic transform, otherwise returns a
spatial_sizecentered area extracted from the input image.rotate_range – angle range in radians. If element i is a pair of (min, max) values, then uniform[-rotate_range[i][0], rotate_range[i][1]) will be used to generate the rotation parameter for the i`th spatial dimension. If not, `uniform[-rotate_range[i], rotate_range[i]) will be used. This can be altered on a per-dimension basis. E.g., ((0,3), 1, …): for dim0, rotation will be in range [0, 3], and for dim1 [-1, 1] will be used. Setting a single value will use [-x, x] for dim0 and nothing for the remaining dimensions.
shear_range –
shear range with format matching rotate_range, it defines the range to randomly select shearing factors(a tuple of 2 floats for 2D) for affine matrix, take a 2D affine as example:
[ [1.0, params[0], 0.0], [params[1], 1.0, 0.0], [0.0, 0.0, 1.0], ]
translate_range – translate range with format matching rotate_range, it defines the range to randomly select pixel to translate for every spatial dims.
scale_range – scaling range with format matching rotate_range. it defines the range to randomly select the scale factor to translate for every spatial dims. A value of 1.0 is added to the result. This allows 0 to correspond to no change (i.e., a scaling of 1.0).
spatial_size – specifying output image spatial size [h, w]. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"reflection". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – device on which the tensor will be allocated.
See also
RandAffineGridfor the random affine parameters configurations.Affinefor the affine transformation parameters configurations.
- randomize(spatial_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
Rand3DElastic#
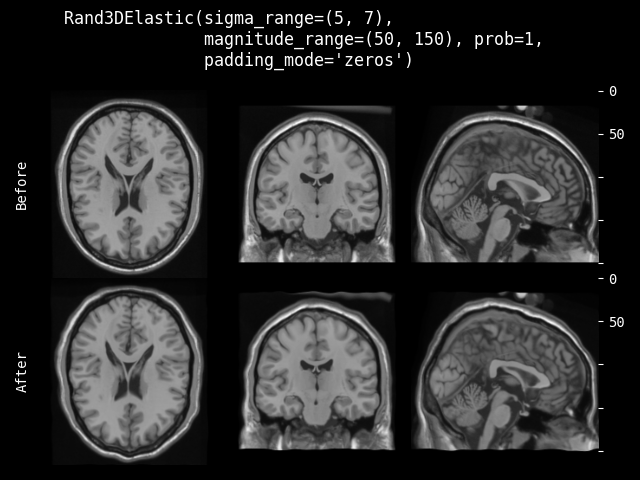
- class monai.transforms.Rand3DElastic(sigma_range, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
Random elastic deformation and affine in 3D. A tutorial is available: Project-MONAI/tutorials.
- __call__(img, spatial_size=None, mode=None, padding_mode=None, randomize=True)[source]#
- Parameters:
img – shape must be (num_channels, H, W, D),
spatial_size – specifying spatial 3D output image spatial size [h, w, d]. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – whether to execute randomize() function first, default to True.
- __init__(sigma_range, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
- Parameters:
sigma_range – a Gaussian kernel with standard deviation sampled from
uniform[sigma_range[0], sigma_range[1])will be used to smooth the random offset grid.magnitude_range – the random offsets on the grid will be generated from
uniform[magnitude[0], magnitude[1]).prob – probability of returning a randomized elastic transform. defaults to 0.1, with 10% chance returns a randomized elastic transform, otherwise returns a
spatial_sizecentered area extracted from the input image.rotate_range – angle range in radians. If element i is a pair of (min, max) values, then uniform[-rotate_range[i][0], rotate_range[i][1]) will be used to generate the rotation parameter for the i`th spatial dimension. If not, `uniform[-rotate_range[i], rotate_range[i]) will be used. This can be altered on a per-dimension basis. E.g., ((0,3), 1, …): for dim0, rotation will be in range [0, 3], and for dim1 [-1, 1] will be used. Setting a single value will use [-x, x] for dim0 and nothing for the remaining dimensions.
shear_range –
shear range with format matching rotate_range, it defines the range to randomly select shearing factors(a tuple of 6 floats for 3D) for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – translate range with format matching rotate_range, it defines the range to randomly select voxel to translate for every spatial dims.
scale_range – scaling range with format matching rotate_range. it defines the range to randomly select the scale factor to translate for every spatial dims. A value of 1.0 is added to the result. This allows 0 to correspond to no change (i.e., a scaling of 1.0).
spatial_size – specifying output image spatial size [h, w, d]. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, 32, -1) will be adapted to (32, 32, 64) if the third spatial dimension size of img is 64.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"reflection". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – device on which the tensor will be allocated.
See also
RandAffineGridfor the random affine parameters configurations.Affinefor the affine transformation parameters configurations.
- randomize(grid_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Return type:
None
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
Rotate90#
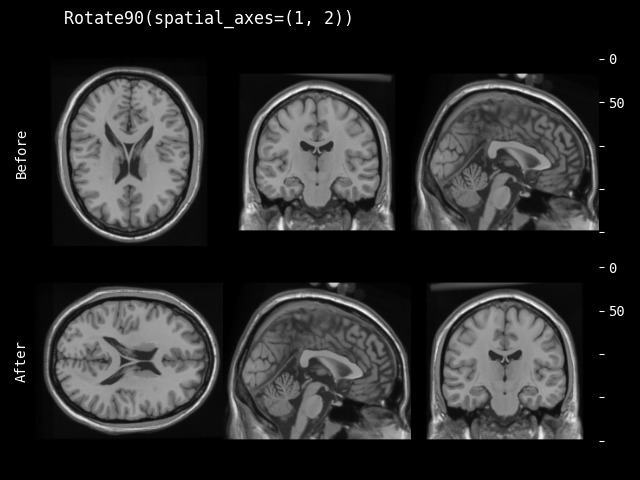
- class monai.transforms.Rotate90(k=1, spatial_axes=(0, 1), lazy=False)[source]#
Rotate an array by 90 degrees in the plane specified by axes. See torch.rot90 for additional details: https://pytorch.org/docs/stable/generated/torch.rot90.html#torch-rot90.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: (num_channels, H[, W, …, ]),
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- __init__(k=1, spatial_axes=(0, 1), lazy=False)[source]#
- Parameters:
k (
int) – number of times to rotate by 90 degrees.spatial_axes (
tuple[int,int]) – 2 int numbers, defines the plane to rotate with 2 spatial axes. Default: (0, 1), this is the first two axis in spatial dimensions. If axis is negative it counts from the last to the first axis.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False
RandRotate90#
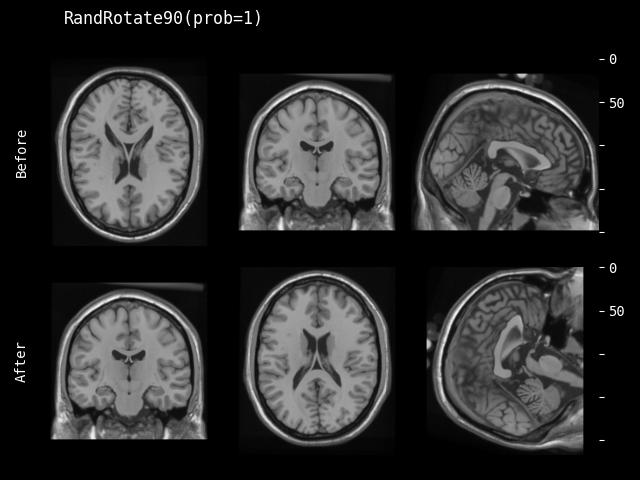
- class monai.transforms.RandRotate90(prob=0.1, max_k=3, spatial_axes=(0, 1), lazy=False)[source]#
With probability prob, input arrays are rotated by 90 degrees in the plane specified by spatial_axes.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(img, randomize=True, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: (num_channels, H[, W, …, ]),
randomize – whether to execute randomize() function first, default to True.
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- __init__(prob=0.1, max_k=3, spatial_axes=(0, 1), lazy=False)[source]#
- Parameters:
prob (
float) – probability of rotating. (Default 0.1, with 10% probability it returns a rotated array)max_k (
int) – number of rotations will be sampled from np.random.randint(max_k) + 1, (Default 3).spatial_axes (
tuple[int,int]) – 2 int numbers, defines the plane to rotate with 2 spatial axes. Default: (0, 1), this is the first two axis in spatial dimensions.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Tensor
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
Flip#
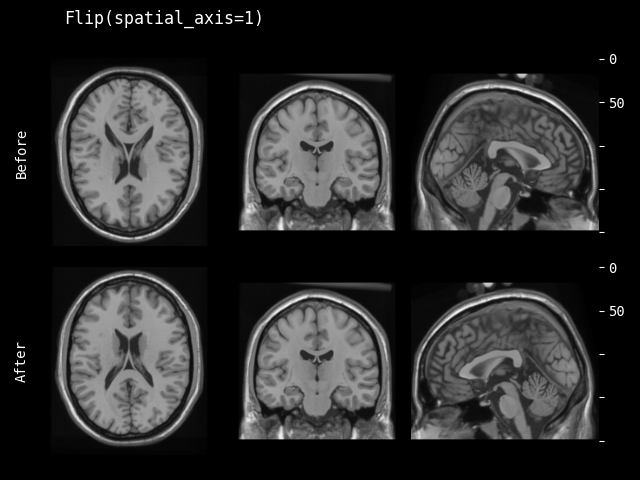
- class monai.transforms.Flip(spatial_axis=None, lazy=False)[source]#
Reverses the order of elements along the given spatial axis. Preserves shape. See torch.flip documentation for additional details: https://pytorch.org/docs/stable/generated/torch.flip.html
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_axis – spatial axes along which to flip over. Default is None. The default axis=None will flip over all of the axes of the input array. If axis is negative it counts from the last to the first axis. If axis is a tuple of ints, flipping is performed on all of the axes specified in the tuple.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(img, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: (num_channels, H[, W, …, ])
lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
Resize#
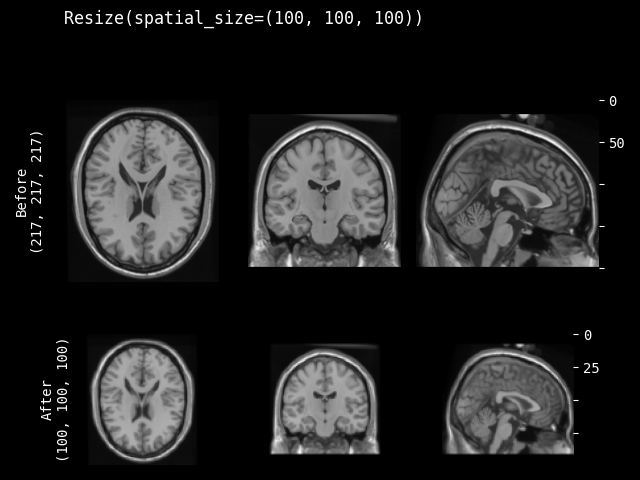
- class monai.transforms.Resize(spatial_size, size_mode='all', mode=area, align_corners=None, anti_aliasing=False, anti_aliasing_sigma=None, dtype=torch.float32, lazy=False)[source]#
Resize the input image to given spatial size (with scaling, not cropping/padding). Implemented using
torch.nn.functional.interpolate.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
spatial_size – expected shape of spatial dimensions after resize operation. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
size_mode – should be “all” or “longest”, if “all”, will use spatial_size for all the spatial dims, if “longest”, rescale the image so that only the longest side is equal to specified spatial_size, which must be an int number in this case, keeping the aspect ratio of the initial image, refer to: https://albumentations.ai/docs/api_reference/augmentations/geometric/resize/ #albumentations.augmentations.geometric.resize.LongestMaxSize.
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults to"area". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: None. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html
anti_aliasing – bool Whether to apply a Gaussian filter to smooth the image prior to downsampling. It is crucial to filter when downsampling the image to avoid aliasing artifacts. See also
skimage.transform.resizeanti_aliasing_sigma – {float, tuple of floats}, optional Standard deviation for Gaussian filtering used when anti-aliasing. By default, this value is chosen as (s - 1) / 2 where s is the downsampling factor, where s > 1. For the up-size case, s < 1, no anti-aliasing is performed prior to rescaling.
dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data.lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(img, mode=None, align_corners=None, anti_aliasing=None, anti_aliasing_sigma=None, dtype=None, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: (num_channels, H[, W, …, ]).
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Defaults to
self.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlanti_aliasing – bool, optional Whether to apply a Gaussian filter to smooth the image prior to downsampling. It is crucial to filter when downsampling the image to avoid aliasing artifacts. See also
skimage.transform.resizeanti_aliasing_sigma – {float, tuple of floats}, optional Standard deviation for Gaussian filtering used when anti-aliasing. By default, this value is chosen as (s - 1) / 2 where s is the downsampling factor, where s > 1. For the up-size case, s < 1, no anti-aliasing is performed prior to rescaling.
dtype – data type for resampling computation. Defaults to
self.dtype. If None, use the data type of input data.lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Raises:
ValueError – When
self.spatial_sizelength is less thanimgspatial dimensions.
Rotate#
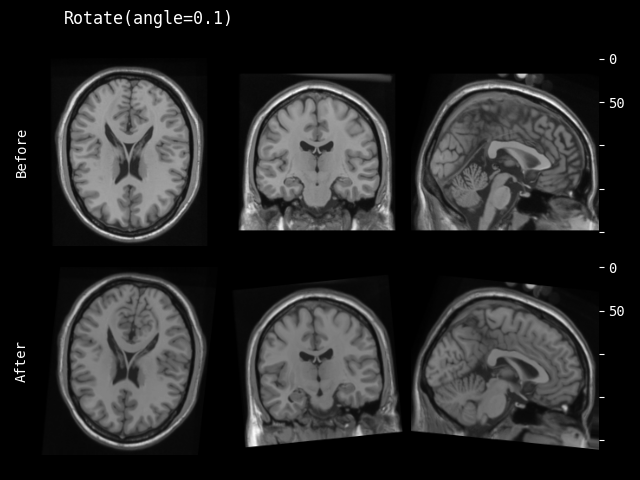
- class monai.transforms.Rotate(angle, keep_size=True, mode=bilinear, padding_mode=border, align_corners=False, dtype=torch.float32, lazy=False)[source]#
Rotates an input image by given angle using
monai.networks.layers.AffineTransform.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
angle – Rotation angle(s) in radians. should a float for 2D, three floats for 3D.
keep_size – If it is True, the output shape is kept the same as the input. If it is False, the output shape is adapted so that the input array is contained completely in the output. Default is True.
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32.lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: [chns, H, W] or [chns, H, W, D].
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults toself.padding_mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html align_corners: Defaults toself.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – Defaults to
self.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.htmldtype – data type for resampling computation. Defaults to
self.dtype. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32.lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Raises:
ValueError – When
imgspatially is not one of [2D, 3D].
Zoom#
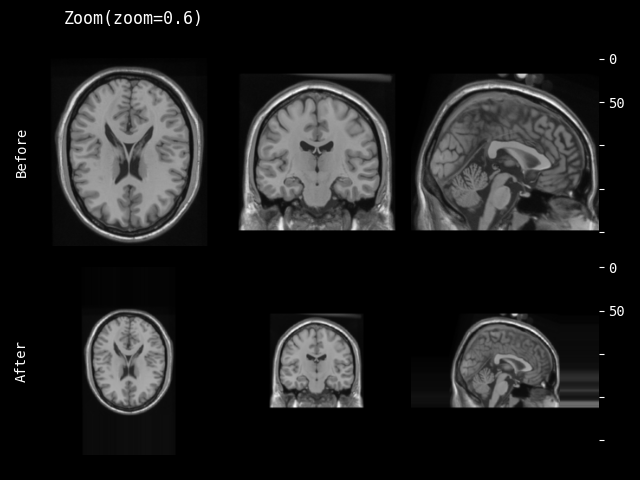
- class monai.transforms.Zoom(zoom, mode=area, padding_mode=edge, align_corners=None, dtype=torch.float32, keep_size=True, lazy=False, **kwargs)[source]#
Zooms an ND image using
torch.nn.functional.interpolate. For details, please see https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html.Different from
monai.transforms.resize, this transform takes scaling factors as input, and provides an option of preserving the input spatial size.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
zoom – The zoom factor along the spatial axes. If a float, zoom is the same for each spatial axis. If a sequence, zoom should contain one value for each spatial axis.
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults to"area". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"edge". The mode to pad data after zooming. See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: None. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html
dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data.keep_size – Should keep original size (padding/slicing if needed), default is True.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- Parameters:
img – channel first array, must have shape: (num_channels, H[, W, …, ]).
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults toself.mode. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"edge". The mode to pad data after zooming. See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Defaults to
self.align_corners. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.htmldtype – data type for resampling computation. Defaults to
self.dtype. If None, use the data type of input data.lazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
GridPatch#
- class monai.transforms.GridPatch(patch_size, offset=None, num_patches=None, overlap=0.0, sort_fn=None, threshold=None, pad_mode=None, **pad_kwargs)[source]#
Extract all the patches sweeping the entire image in a row-major sliding-window manner with possible overlaps. It can sort the patches and return all or a subset of them.
- Parameters:
patch_size – size of patches to generate slices for, 0 or None selects whole dimension
offset – offset of starting position in the array, default is 0 for each dimension.
num_patches – number of patches (or maximum number of patches) to return. If the requested number of patches is greater than the number of available patches, padding will be applied to provide exactly num_patches patches unless threshold is set. When threshold is set, this value is treated as the maximum number of patches. Defaults to None, which does not limit number of the patches.
overlap – the amount of overlap of neighboring patches in each dimension (a value between 0.0 and 1.0). If only one float number is given, it will be applied to all dimensions. Defaults to 0.0.
sort_fn – when num_patches is provided, it determines if keep patches with highest values (“max”), lowest values (“min”), or in their default order (None). Default to None.
threshold – a value to keep only the patches whose sum of intensities are less than the threshold. Defaults to no filtering.
pad_mode – the mode for padding the input image by patch_size to include patches that cross boundaries. Available modes: (Numpy) {
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to None, which means no padding will be applied. See also: https://numpy.org/doc/stable/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html requires pytorch >= 1.10 for best compatibility.pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- Returns:
- the extracted patches as a single tensor (with patch dimension as the first dimension),
with following metadata:
PatchKeys.LOCATION: the starting location of the patch in the image,
PatchKeys.COUNT: total number of patches in the image,
”spatial_shape”: spatial size of the extracted patch, and
”offset”: the amount of offset for the patches in the image (starting position of the first patch)
- Return type:
- __call__(array)[source]#
Extract the patches (sweeping the entire image in a row-major sliding-window manner with possible overlaps).
- Parameters:
array (
Union[ndarray,Tensor]) – a input image as numpy.ndarray or torch.Tensor- Returns:
- the extracted patches as a single tensor (with patch dimension as the first dimension),
with defined PatchKeys.LOCATION and PatchKeys.COUNT metadata.
- Return type:
- filter_count(image_np, locations)[source]#
Sort the patches based on the sum of their intensity, and just keep self.num_patches of them.
- Parameters:
image_np (
Union[ndarray,Tensor]) – a numpy.ndarray or torch.Tensor representing a stack of patches.locations (
ndarray) – a numpy.ndarray representing the stack of location of each patch.
- Return type:
tuple[Union[ndarray,Tensor],ndarray]
- filter_threshold(image_np, locations)[source]#
Filter the patches and their locations according to a threshold.
- Parameters:
image_np (
Union[ndarray,Tensor]) – a numpy.ndarray or torch.Tensor representing a stack of patches.locations (
ndarray) – a numpy.ndarray representing the stack of location of each patch.
- Returns:
tuple of filtered patches and locations.
- Return type:
tuple[NdarrayOrTensor, numpy.ndarray]
RandGridPatch#
- class monai.transforms.RandGridPatch(patch_size, min_offset=None, max_offset=None, num_patches=None, overlap=0.0, sort_fn=None, threshold=None, pad_mode=None, **pad_kwargs)[source]#
Extract all the patches sweeping the entire image in a row-major sliding-window manner with possible overlaps, and with random offset for the minimal corner of the image, (0,0) for 2D and (0,0,0) for 3D. It can sort the patches and return all or a subset of them.
- Parameters:
patch_size – size of patches to generate slices for, 0 or None selects whole dimension
min_offset – the minimum range of offset to be selected randomly. Defaults to 0.
max_offset – the maximum range of offset to be selected randomly. Defaults to image size modulo patch size.
num_patches – number of patches (or maximum number of patches) to return. If the requested number of patches is greater than the number of available patches, padding will be applied to provide exactly num_patches patches unless threshold is set. When threshold is set, this value is treated as the maximum number of patches. Defaults to None, which does not limit number of the patches.
overlap – the amount of overlap of neighboring patches in each dimension (a value between 0.0 and 1.0). If only one float number is given, it will be applied to all dimensions. Defaults to 0.0.
sort_fn – when num_patches is provided, it determines if keep patches with highest values (“max”), lowest values (“min”), in random (“random”), or in their default order (None). Default to None.
threshold – a value to keep only the patches whose sum of intensities are less than the threshold. Defaults to no filtering.
pad_mode – the mode for padding the input image by patch_size to include patches that cross boundaries. Available modes: (Numpy) {
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to None, which means no padding will be applied. See also: https://numpy.org/doc/stable/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html requires pytorch >= 1.10 for best compatibility.pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- Returns:
- the extracted patches as a single tensor (with patch dimension as the first dimension),
with following metadata:
PatchKeys.LOCATION: the starting location of the patch in the image,
PatchKeys.COUNT: total number of patches in the image,
”spatial_shape”: spatial size of the extracted patch, and
”offset”: the amount of offset for the patches in the image (starting position of the first patch)
- Return type:
- __call__(array, randomize=True)[source]#
Extract the patches (sweeping the entire image in a row-major sliding-window manner with possible overlaps).
- Parameters:
array (
Union[ndarray,Tensor]) – a input image as numpy.ndarray or torch.Tensor- Returns:
- the extracted patches as a single tensor (with patch dimension as the first dimension),
with defined PatchKeys.LOCATION and PatchKeys.COUNT metadata.
- Return type:
- filter_count(image_np, locations)[source]#
Sort the patches based on the sum of their intensity, and just keep self.num_patches of them.
- Parameters:
image_np (
Union[ndarray,Tensor]) – a numpy.ndarray or torch.Tensor representing a stack of patches.locations (
ndarray) – a numpy.ndarray representing the stack of location of each patch.
- Return type:
tuple[Union[ndarray,Tensor],ndarray]
- randomize(array)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
GridSplit#
- class monai.transforms.GridSplit(grid=(2, 2), size=None)[source]#
Split the image into patches based on the provided grid in 2D.
- Parameters:
grid – a tuple define the shape of the grid upon which the image is split. Defaults to (2, 2)
size – a tuple or an integer that defines the output patch sizes. If it’s an integer, the value will be repeated for each dimension. The default is None, where the patch size will be inferred from the grid shape.
Example
Given an image (torch.Tensor or numpy.ndarray) with size of (3, 10, 10) and a grid of (2, 2), it will return a Tensor or array with the size of (4, 3, 5, 5). Here, if the size is provided, the returned shape will be (4, 3, size, size)
Note: This transform currently support only image with two spatial dimensions.
- __call__(image, size=None)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
RandSimulateLowResolution#
- class monai.transforms.RandSimulateLowResolution(prob=0.1, downsample_mode=nearest, upsample_mode=trilinear, zoom_range=(0.5, 1.0), align_corners=False, device=None)[source]#
Random simulation of low resolution corresponding to nnU-Net’s SimulateLowResolutionTransform (MIC-DKFZ/batchgenerators) First, the array/tensor is resampled at lower resolution as determined by the zoom_factor which is uniformly sampled from the zoom_range. Then, the array/tensor is resampled at the original resolution.
- __call__(img, randomize=True)[source]#
- Parameters:
img (
Tensor) – shape must be (num_channels, H, W[, D]),randomize (
bool) – whether to execute randomize() function first, defaults to True.
- Return type:
Tensor
- __init__(prob=0.1, downsample_mode=nearest, upsample_mode=trilinear, zoom_range=(0.5, 1.0), align_corners=False, device=None)[source]#
- Parameters:
prob – probability of performing this augmentation
downsample_mode – interpolation mode for downsampling operation
upsample_mode – interpolation mode for upsampling operation
zoom_range – range from which the random zoom factor for the downsampling and upsampling operation is
tensor. (sampled. It determines the shape of the downsampled)
align_corners – This only has an effect when downsample_mode or upsample_mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: False See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html
device – device on which the tensor will be allocated.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
Smooth Field#
RandSmoothFieldAdjustContrast#
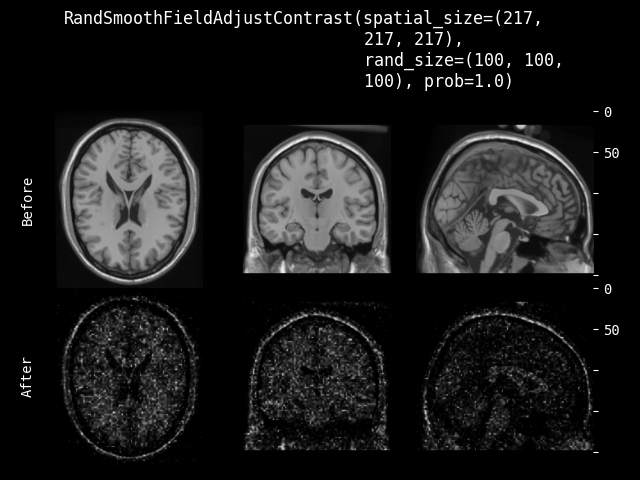
- class monai.transforms.RandSmoothFieldAdjustContrast(spatial_size, rand_size, pad=0, mode=area, align_corners=None, prob=0.1, gamma=(0.5, 4.5), device=None)[source]#
Randomly adjust the contrast of input images by calculating a randomized smooth field for each invocation.
This uses SmoothField internally to define the adjustment over the image. If pad is greater than 0 the edges of the input volume of that width will be mostly unchanged. Contrast is changed by raising input values by the power of the smooth field so the range of values given by gamma should be chosen with this in mind. For example, a minimum value of 0 in gamma will produce white areas so this should be avoided. After the contrast is adjusted the values of the result are rescaled to the range of the original input.
- Parameters:
spatial_size – size of input array’s spatial dimensions
rand_size – size of the randomized field to start from
pad – number of pixels/voxels along the edges of the field to pad with 1
mode – interpolation mode to use when upsampling
align_corners – if True align the corners when upsampling field
prob – probability transform is applied
gamma – (min, max) range for exponential field
device – Pytorch device to define field on
- __call__(img, randomize=True)[source]#
Apply the transform to img, if randomize randomizing the smooth field otherwise reusing the previous.
- Return type:
Union[ndarray,Tensor]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandSmoothFieldAdjustIntensity#
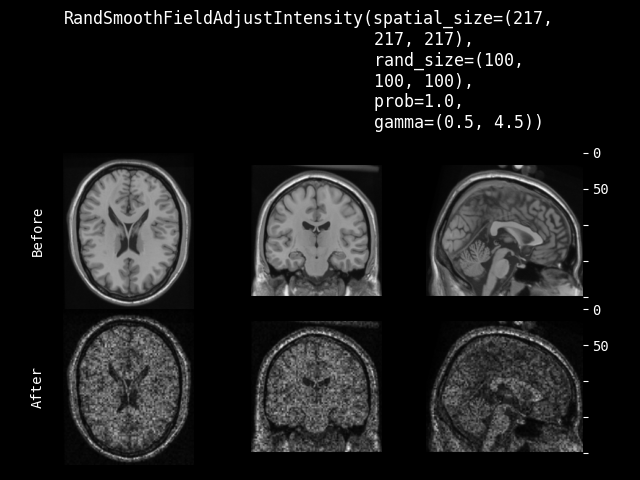
- class monai.transforms.RandSmoothFieldAdjustIntensity(spatial_size, rand_size, pad=0, mode=area, align_corners=None, prob=0.1, gamma=(0.1, 1.0), device=None)[source]#
Randomly adjust the intensity of input images by calculating a randomized smooth field for each invocation.
This uses SmoothField internally to define the adjustment over the image. If pad is greater than 0 the edges of the input volume of that width will be mostly unchanged. Intensity is changed by multiplying the inputs by the smooth field, so the values of gamma should be chosen with this in mind. The default values of (0.1, 1.0) are sensible in that values will not be zeroed out by the field nor multiplied greater than the original value range.
- Parameters:
spatial_size – size of input array
rand_size – size of the randomized field to start from
pad – number of pixels/voxels along the edges of the field to pad with 1
mode – interpolation mode to use when upsampling
align_corners – if True align the corners when upsampling field
prob – probability transform is applied
gamma – (min, max) range of intensity multipliers
device – Pytorch device to define field on
- __call__(img, randomize=True)[source]#
Apply the transform to img, if randomize randomizing the smooth field otherwise reusing the previous.
- Return type:
Union[ndarray,Tensor]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandSmoothDeform#

- class monai.transforms.RandSmoothDeform(spatial_size, rand_size, pad=0, field_mode=area, align_corners=None, prob=0.1, def_range=1.0, grid_dtype=torch.float32, grid_mode=nearest, grid_padding_mode=border, grid_align_corners=False, device=None)[source]#
Deform an image using a random smooth field and Pytorch’s grid_sample.
The amount of deformation is given by def_range in fractions of the size of the image. The size of each dimension of the input image is always defined as 2 regardless of actual image voxel dimensions, that is the coordinates in every dimension range from -1 to 1. A value of 0.1 means pixels/voxels can be moved by up to 5% of the image’s size.
- Parameters:
spatial_size – input array size to which deformation grid is interpolated
rand_size – size of the randomized field to start from
pad – number of pixels/voxels along the edges of the field to pad with 0
field_mode – interpolation mode to use when upsampling the deformation field
align_corners – if True align the corners when upsampling field
prob – probability transform is applied
def_range – value of the deformation range in image size fractions, single min/max value or min/max pair
grid_dtype – type for the deformation grid calculated from the field
grid_mode – interpolation mode used for sampling input using deformation grid
grid_padding_mode – padding mode used for sampling input using deformation grid
grid_align_corners – if True align the corners when sampling the deformation grid
device – Pytorch device to define field on
- __call__(img, randomize=True, device=None)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
MRI Transforms#
Kspace under-sampling#
- class monai.apps.reconstruction.transforms.array.KspaceMask(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
A basic class for under-sampling mask setup. It provides common features for under-sampling mask generators. For example, RandomMaskFunc and EquispacedMaskFunc (two mask transform objects defined right after this module) both inherit MaskFunc to properly setup properties like the acceleration factor.
- abstract __call__(kspace)[source]#
This is an extra instance to allow for defining new mask generators. For creating other mask transforms, define a new class and simply override __call__. See an example of this in
monai.apps.reconstruction.transforms.array.RandomKspacemask.- Parameters:
kspace (
Union[ndarray,Tensor]) – The input k-space data. The shape is (…,num_coils,H,W,2) for complex 2D inputs and (…,num_coils,H,W,D) for real 3D data.- Return type:
Sequence[Tensor]
- __init__(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
- Parameters:
center_fractions (
Sequence[float]) – Fraction of low-frequency columns to be retained. If multiple values are provided, then one of these numbers is chosen uniformly each time.accelerations (
Sequence[float]) – Amount of under-sampling. This should have the same length as center_fractions. If multiple values are provided, then one of these is chosen uniformly each time.spatial_dims (
int) – Number of spatial dims (e.g., it’s 2 for a 2D data; it’s also 2 for pseudo-3D datasets like the fastMRI dataset). The last spatial dim is selected for sampling. For the fastMRI dataset, k-space has the form (…,num_slices,num_coils,H,W) and sampling is done along W. For a general 3D data with the shape (…,num_coils,H,W,D), sampling is done along D.is_complex (
bool) – if True, then the last dimension will be reserved for real/imaginary parts.
- randomize_choose_acceleration()[source]#
If multiple values are provided for center_fractions and accelerations, this function selects one value uniformly for each training/test sample.
- Return type:
Sequence[float]- Returns:
- A tuple containing
(1) center_fraction: chosen fraction of center kspace lines to exclude from under-sampling (2) acceleration: chosen acceleration factor
- class monai.apps.reconstruction.transforms.array.RandomKspaceMask(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
This k-space mask transform under-samples the k-space according to a random sampling pattern. Precisely, it uniformly selects a subset of columns from the input k-space data. If the k-space data has N columns, the mask picks out:
1. N_low_freqs = (N * center_fraction) columns in the center corresponding to low-frequencies
2. The other columns are selected uniformly at random with a probability equal to: prob = (N / acceleration - N_low_freqs) / (N - N_low_freqs). This ensures that the expected number of columns selected is equal to (N / acceleration)
It is possible to use multiple center_fractions and accelerations, in which case one possible (center_fraction, acceleration) is chosen uniformly at random each time the transform is called.
Example
If accelerations = [4, 8] and center_fractions = [0.08, 0.04], then there is a 50% probability that 4-fold acceleration with 8% center fraction is selected and a 50% probability that 8-fold acceleration with 4% center fraction is selected.
- Modified and adopted from:
- __call__(kspace)[source]#
- Parameters:
kspace (
Union[ndarray,Tensor]) – The input k-space data. The shape is (…,num_coils,H,W,2) for complex 2D inputs and (…,num_coils,H,W,D) for real 3D data. The last spatial dim is selected for sampling. For the fastMRI dataset, k-space has the form (…,num_slices,num_coils,H,W) and sampling is done along W. For a general 3D data with the shape (…,num_coils,H,W,D), sampling is done along D.- Return type:
Sequence[Tensor]- Returns:
- A tuple containing
the under-sampled kspace
absolute value of the inverse fourier of the under-sampled kspace
- class monai.apps.reconstruction.transforms.array.EquispacedKspaceMask(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
This k-space mask transform under-samples the k-space according to an equi-distant sampling pattern. Precisely, it selects an equi-distant subset of columns from the input k-space data. If the k-space data has N columns, the mask picks out:
1. N_low_freqs = (N * center_fraction) columns in the center corresponding to low-frequencies
2. The other columns are selected with equal spacing at a proportion that reaches the desired acceleration rate taking into consideration the number of low frequencies. This ensures that the expected number of columns selected is equal to (N / acceleration)
It is possible to use multiple center_fractions and accelerations, in which case one possible (center_fraction, acceleration) is chosen uniformly at random each time the EquispacedMaskFunc object is called.
Example
If accelerations = [4, 8] and center_fractions = [0.08, 0.04], then there is a 50% probability that 4-fold acceleration with 8% center fraction is selected and a 50% probability that 8-fold acceleration with 4% center fraction is selected.
- Modified and adopted from:
- __call__(kspace)[source]#
- Parameters:
kspace (
Union[ndarray,Tensor]) – The input k-space data. The shape is (…,num_coils,H,W,2) for complex 2D inputs and (…,num_coils,H,W,D) for real 3D data. The last spatial dim is selected for sampling. For the fastMRI multi-coil dataset, k-space has the form (…,num_slices,num_coils,H,W) and sampling is done along W. For a general 3D data with the shape (…,num_coils,H,W,D), sampling is done along D.- Return type:
Sequence[Tensor]- Returns:
- A tuple containing
the under-sampled kspace
absolute value of the inverse fourier of the under-sampled kspace
Lazy#
ApplyPending#
- class monai.transforms.ApplyPending[source]#
ApplyPending can be inserted into a pipeline that is being executed lazily in order to ensure resampling happens before the next transform. It doesn’t do anything itself, but its presence causes the pipeline to be executed as ApplyPending doesn’t implement
`LazyTrait.See
Composefor a detailed explanation of the lazy resampling feature.
Utility#
Identity#
AsChannelLast#
- class monai.transforms.AsChannelLast(channel_dim=0)[source]#
Change the channel dimension of the image to the last dimension.
Some of other 3rd party transforms assume the input image is in the channel-last format with shape (spatial_dim_1[, spatial_dim_2, …], num_channels).
This transform could be used to convert, for example, a channel-first image array in shape (num_channels, spatial_dim_1[, spatial_dim_2, …]) into the channel-last format, so that MONAI transforms can construct a chain with other 3rd party transforms together.
- Parameters:
channel_dim (
int) – which dimension of input image is the channel, default is the first dimension.
EnsureChannelFirst#
- class monai.transforms.EnsureChannelFirst(strict_check=True, channel_dim=None)[source]#
Adjust or add the channel dimension of input data to ensure channel_first shape.
This extracts the original_channel_dim info from provided meta_data dictionary or MetaTensor input. This value should state which dimension is the channel dimension so that it can be moved forward, or contain “no_channel” to state no dimension is the channel and so a 1-size first dimension is to be added.
- Parameters:
strict_check – whether to raise an error when the meta information is insufficient.
channel_dim – This argument can be used to specify the original channel dimension (integer) of the input array. It overrides the original_channel_dim from provided MetaTensor input. If the input array doesn’t have a channel dim, this value should be
'no_channel'. If this is set to None, this class relies on img or meta_dict to provide the channel dimension.
RepeatChannel#
- class monai.transforms.RepeatChannel(repeats)[source]#
Repeat channel data to construct expected input shape for models. The repeats count includes the origin data, for example:
RepeatChannel(repeats=2)([[1, 2], [3, 4]])generates:[[1, 2], [1, 2], [3, 4], [3, 4]]- Parameters:
repeats (
int) – the number of repetitions for each element.
SplitDim#
- class monai.transforms.SplitDim(dim=-1, keepdim=True, update_meta=True)[source]#
Given an image of size X along a certain dimension, return a list of length X containing images. Useful for converting 3D images into a stack of 2D images, splitting multichannel inputs into single channels, for example.
Note: torch.split/np.split is used, so the outputs are views of the input (shallow copy).
- Parameters:
dim (
int) – dimension on which to splitkeepdim (
bool) – if True, output will have singleton in the split dimension. If False, this dimension will be squeezed.update_meta – whether to update the MetaObj in each split result.
CastToType#
- class monai.transforms.CastToType(dtype=<class 'numpy.float32'>)[source]#
Cast the Numpy data to specified numpy data type, or cast the PyTorch Tensor to specified PyTorch data type.
Example
>>> import numpy as np >>> import torch >>> transform = CastToType(dtype=np.float32)
>>> # Example with a numpy array >>> img_np = np.array([0, 127, 255], dtype=np.uint8) >>> img_np_casted = transform(img_np) >>> img_np_casted array([ 0. , 127. , 255. ], dtype=float32)
>>> # Example with a PyTorch tensor >>> img_tensor = torch.tensor([0, 127, 255], dtype=torch.uint8) >>> img_tensor_casted = transform(img_tensor) >>> img_tensor_casted tensor([ 0., 127., 255.]) # dtype is float32
ToTensor#
- class monai.transforms.ToTensor(dtype=None, device=None, wrap_sequence=True, track_meta=None)[source]#
Converts the input image to a tensor without applying any other transformations. Input data can be PyTorch Tensor, numpy array, list, dictionary, int, float, bool, str, etc. Will convert Tensor, Numpy array, float, int, bool to Tensor, strings and objects keep the original. For dictionary, list or tuple, convert every item to a Tensor if applicable and wrap_sequence=False.
- Parameters:
dtype – target data type to when converting to Tensor.
device – target device to put the converted Tensor data.
wrap_sequence – if False, then lists will recursively call this function, default to True. E.g., if False, [1, 2] -> [tensor(1), tensor(2)], if True, then [1, 2] -> tensor([1, 2]).
track_meta – whether to convert to MetaTensor or regular tensor, default to None, use the return value of
get_track_meta.
ToNumpy#
- class monai.transforms.ToNumpy(dtype=None, wrap_sequence=True)[source]#
Converts the input data to numpy array, can support list or tuple of numbers and PyTorch Tensor.
- Parameters:
dtype (
Union[dtype,type,str,None]) – target data type when converting to numpy array.wrap_sequence (
bool) – if False, then lists will recursively call this function, default to True. E.g., if False, [1, 2] -> [array(1), array(2)], if True, then [1, 2] -> array([1, 2]).
ToCupy#
- class monai.transforms.ToCupy(dtype=None, wrap_sequence=True)[source]#
Converts the input data to CuPy array, can support list or tuple of numbers, NumPy and PyTorch Tensor.
- Parameters:
dtype – data type specifier. It is inferred from the input by default. if not None, must be an argument of numpy.dtype, for more details: https://docs.cupy.dev/en/stable/reference/generated/cupy.array.html.
wrap_sequence – if False, then lists will recursively call this function, default to True. E.g., if False, [1, 2] -> [array(1), array(2)], if True, then [1, 2] -> array([1, 2]).
Transpose#
SqueezeDim#
DataStats#
- class monai.transforms.DataStats(prefix='Data', data_type=True, data_shape=True, value_range=True, data_value=False, additional_info=None, name='DataStats')[source]#
Utility transform to show the statistics of data for debug or analysis. It can be inserted into any place of a transform chain and check results of previous transforms. It support both numpy.ndarray and torch.tensor as input data, so it can be used in pre-processing and post-processing.
It gets logger from logging.getLogger(name), we can setup a logger outside first with the same name. If the log level of logging.RootLogger is higher than INFO, will add a separate StreamHandler log handler with INFO level and record to stdout.
- __call__(img, prefix=None, data_type=None, data_shape=None, value_range=None, data_value=None, additional_info=None)[source]#
Apply the transform to img, optionally take arguments similar to the class constructor.
- __init__(prefix='Data', data_type=True, data_shape=True, value_range=True, data_value=False, additional_info=None, name='DataStats')[source]#
- Parameters:
prefix – will be printed in format: “{prefix} statistics”.
data_type – whether to show the type of input data.
data_shape – whether to show the shape of input data.
value_range – whether to show the value range of input data.
data_value – whether to show the raw value of input data. a typical example is to print some properties of Nifti image: affine, pixdim, etc.
additional_info – user can define callable function to extract additional info from input data.
name – identifier of logging.logger to use, defaulting to “DataStats”.
- Raises:
TypeError – When
additional_infois not anOptional[Callable].
SimulateDelay#
- class monai.transforms.SimulateDelay(delay_time=0.0)[source]#
This is a pass through transform to be used for testing purposes. It allows adding fake behaviors that are useful for testing purposes to simulate how large datasets behave without needing to test on large data sets.
For example, simulating slow NFS data transfers, or slow network transfers in testing by adding explicit timing delays. Testing of small test data can lead to incomplete understanding of real world issues, and may lead to sub-optimal design choices.
Lambda#
- class monai.transforms.Lambda(func=None, inv_func=<function no_collation>, track_meta=True)[source]#
Apply a user-defined lambda as a transform.
For example:
image = np.ones((10, 2, 2)) lambd = Lambda(func=lambda x: x[:4, :, :]) print(lambd(image).shape) (4, 2, 2)
- Parameters:
func – Lambda/function to be applied.
inv_func – Lambda/function of inverse operation, default to lambda x: x.
track_meta – If False, then standard data objects will be returned (e.g., torch.Tensor` and np.ndarray) as opposed to MONAI’s enhanced objects. By default, this is True.
- Raises:
TypeError – When
funcis not anOptional[Callable].
RandLambda#
- class monai.transforms.RandLambda(func=None, prob=1.0, inv_func=<function no_collation>, track_meta=True)[source]#
Randomizable version
monai.transforms.Lambda, the input func may contain random logic, or randomly execute the function based on prob.- Parameters:
func – Lambda/function to be applied.
prob – probability of executing the random function, default to 1.0, with 100% probability to execute.
inv_func – Lambda/function of inverse operation, default to lambda x: x.
track_meta – If False, then standard data objects will be returned (e.g., torch.Tensor` and np.ndarray) as opposed to MONAI’s enhanced objects. By default, this is True.
For more details, please check
monai.transforms.Lambda.
RemoveRepeatedChannel#
- class monai.transforms.RemoveRepeatedChannel(repeats)[source]#
RemoveRepeatedChannel data to undo RepeatChannel The repeats count specifies the deletion of the origin data, for example:
RemoveRepeatedChannel(repeats=2)([[1, 2], [1, 2], [3, 4], [3, 4]])generates:[[1, 2], [3, 4]]- Parameters:
repeats (
int) – the number of repetitions to be deleted for each element.
LabelToMask#
- class monai.transforms.LabelToMask(select_labels, merge_channels=False)[source]#
Convert labels to mask for other tasks. A typical usage is to convert segmentation labels to mask data to pre-process images and then feed the images into classification network. It can support single channel labels or One-Hot labels with specified select_labels. For example, users can select label value = [2, 3] to construct mask data, or select the second and the third channels of labels to construct mask data. The output mask data can be a multiple channels binary data or a single channel binary data that merges all the channels.
- Parameters:
select_labels – labels to generate mask from. for 1 channel label, the select_labels is the expected label values, like: [1, 2, 3]. for One-Hot format label, the select_labels is the expected channel indices.
merge_channels – whether to use np.any() to merge the result on channel dim. if yes, will return a single channel mask with binary data.
- __call__(img, select_labels=None, merge_channels=False)[source]#
- Parameters:
select_labels – labels to generate mask from. for 1 channel label, the select_labels is the expected label values, like: [1, 2, 3]. for One-Hot format label, the select_labels is the expected channel indices.
merge_channels – whether to use np.any() to merge the result on channel dim. if yes, will return a single channel mask with binary data.
FgBgToIndices#
- class monai.transforms.FgBgToIndices(image_threshold=0.0, output_shape=None)[source]#
Compute foreground and background of the input label data, return the indices. If no output_shape specified, output data will be 1 dim indices after flattening. This transform can help pre-compute foreground and background regions for other transforms. A typical usage is to randomly select foreground and background to crop. The main logic is based on
monai.transforms.utils.map_binary_to_indices.- Parameters:
image_threshold – if enabled image at runtime, use
image > image_thresholdto determine the valid image content area and select background only in this area.output_shape – expected shape of output indices. if not None, unravel indices to specified shape.
- __call__(label, image=None, output_shape=None)[source]#
- Parameters:
label – input data to compute foreground and background indices.
image – if image is not None, use
label = 0 & image > image_thresholdto define background. so the output items will not map to all the voxels in the label.output_shape – expected shape of output indices. if None, use self.output_shape instead.
ClassesToIndices#
- class monai.transforms.ClassesToIndices(num_classes=None, image_threshold=0.0, output_shape=None, max_samples_per_class=None)[source]#
- __call__(label, image=None, output_shape=None)[source]#
- Parameters:
label – input data to compute the indices of every class.
image – if image is not None, use
image > image_thresholdto define valid region, and only select the indices within the valid region.output_shape – expected shape of output indices. if None, use self.output_shape instead.
- __init__(num_classes=None, image_threshold=0.0, output_shape=None, max_samples_per_class=None)[source]#
Compute indices of every class of the input label data, return a list of indices. If no output_shape specified, output data will be 1 dim indices after flattening. This transform can help pre-compute indices of the class regions for other transforms. A typical usage is to randomly select indices of classes to crop. The main logic is based on
monai.transforms.utils.map_classes_to_indices.- Parameters:
num_classes – number of classes for argmax label, not necessary for One-Hot label.
image_threshold – if enabled image at runtime, use
image > image_thresholdto determine the valid image content area and select only the indices of classes in this area.output_shape – expected shape of output indices. if not None, unravel indices to specified shape.
max_samples_per_class – maximum length of indices to sample in each class to reduce memory consumption. Default is None, no subsampling.
ConvertToMultiChannelBasedOnBratsClasses#
- class monai.transforms.ConvertToMultiChannelBasedOnBratsClasses[source]#
Convert labels to multi channels based on brats18 classes: label 1 is the necrotic and non-enhancing tumor core label 2 is the peritumoral edema label 4 is the GD-enhancing tumor The possible classes are TC (Tumor core), WT (Whole tumor) and ET (Enhancing tumor).
- __call__(img)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Union[ndarray,Tensor]
AddExtremePointsChannel#
- class monai.transforms.AddExtremePointsChannel(background=0, pert=0.0)[source]#
Add extreme points of label to the image as a new channel. This transform generates extreme point from label and applies a gaussian filter. The pixel values in points image are rescaled to range [rescale_min, rescale_max] and added as a new channel to input image. The algorithm is described in Roth et al., Going to Extremes: Weakly Supervised Medical Image Segmentation https://arxiv.org/abs/2009.11988.
This transform only supports single channel labels (1, spatial_dim1, [spatial_dim2, …]). The background
indexis ignored when calculating extreme points.- Parameters:
background (
int) – Class index of background label, defaults to 0.pert (
float) – Random perturbation amount to add to the points, defaults to 0.0.
- Raises:
ValueError – When no label image provided.
ValueError – When label image is not single channel.
- __call__(img, label=None, sigma=3.0, rescale_min=-1.0, rescale_max=1.0)[source]#
- Parameters:
img – the image that we want to add new channel to.
label – label image to get extreme points from. Shape must be (1, spatial_dim1, [, spatial_dim2, …]). Doesn’t support one-hot labels.
sigma – if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
rescale_min – minimum value of output data.
rescale_max – maximum value of output data.
- randomize(label)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
TorchVision#
- class monai.transforms.TorchVision(name, *args, **kwargs)[source]#
This is a wrapper transform for PyTorch TorchVision transform based on the specified transform name and args. As most of the TorchVision transforms only work for PIL image and PyTorch Tensor, this transform expects input data to be PyTorch Tensor, users can easily call ToTensor transform to convert a Numpy array to Tensor.
MapLabelValue#
- class monai.transforms.MapLabelValue(orig_labels, target_labels, dtype=<class 'numpy.float32'>)[source]#
Utility to map label values to another set of values. For example, map [3, 2, 1] to [0, 1, 2], [1, 2, 3] -> [0.5, 1.5, 2.5], [“label3”, “label2”, “label1”] -> [0, 1, 2], [3.5, 2.5, 1.5] -> [“label0”, “label1”, “label2”], etc. The label data must be numpy array or array-like data and the output data will be numpy array.
- __init__(orig_labels, target_labels, dtype=<class 'numpy.float32'>)[source]#
- Parameters:
orig_labels (
Sequence) – original labels that map to others.target_labels (
Sequence) – expected label values, 1: 1 map to the orig_labels.dtype (
Union[dtype,type,str,None]) – convert the output data to dtype, default to float32. if dtype is from PyTorch, the transform will use the pytorch backend, else with numpy backend.
EnsureType#
- class monai.transforms.EnsureType(data_type='tensor', dtype=None, device=None, wrap_sequence=True, track_meta=None)[source]#
Ensure the input data to be a PyTorch Tensor or numpy array, support: numpy array, PyTorch Tensor, float, int, bool, string and object keep the original. If passing a dictionary, list or tuple, still return dictionary, list or tuple will recursively convert every item to the expected data type if wrap_sequence=False.
- Parameters:
data_type – target data type to convert, should be “tensor” or “numpy”.
dtype – target data content type to convert, for example: np.float32, torch.float, etc.
device – for Tensor data type, specify the target device.
wrap_sequence – if False, then lists will recursively call this function, default to True.
track_meta – if True convert to
MetaTensor, otherwise to PytorchTensor, ifNonebehave according to return value of py:func:monai.data.meta_obj.get_track_meta.
- Example with wrap_sequence=True:
>>> import numpy as np >>> import torch >>> transform = EnsureType(data_type="tensor", wrap_sequence=True) >>> # Converting a list to a tensor >>> data_list = [1, 2., 3] >>> tensor_data = transform(data_list) >>> tensor_data tensor([1., 2., 3.]) # All elements have dtype float32
- Example with wrap_sequence=False:
>>> transform = EnsureType(data_type="tensor", wrap_sequence=False) >>> # Converting each element in a list to individual tensors >>> data_list = [1, 2, 3] >>> tensors_list = transform(data_list) >>> tensors_list [tensor(1), tensor(2.), tensor(3)] # Only second element is float32 rest are int64
- __call__(data, dtype=None)[source]#
- Parameters:
data – input data can be PyTorch Tensor, numpy array, list, dictionary, int, float, bool, str, etc. will ensure Tensor, Numpy array, float, int, bool as Tensors or numpy arrays, strings and objects keep the original. for dictionary, list or tuple, ensure every item as expected type if applicable and wrap_sequence=False.
dtype – target data content type to convert, for example: np.float32, torch.float, etc.
IntensityStats#
- class monai.transforms.IntensityStats(ops, key_prefix, channel_wise=False)[source]#
Compute statistics for the intensity values of input image and store into the metadata dictionary. For example: if ops=[lambda x: np.mean(x), “max”] and key_prefix=”orig”, may generate below stats: {“orig_custom_0”: 1.5, “orig_max”: 3.0}.
- Parameters:
ops – expected operations to compute statistics for the intensity. if a string, will map to the predefined operations, supported: [“mean”, “median”, “max”, “min”, “std”] mapping to np.nanmean, np.nanmedian, np.nanmax, np.nanmin, np.nanstd. if a callable function, will execute the function on input image.
key_prefix – the prefix to combine with ops name to generate the key to store the results in the metadata dictionary. if some ops are callable functions, will use “{key_prefix}_custom_{index}” as the key, where index counts from 0.
channel_wise – whether to compute statistics for every channel of input image separately. if True, return a list of values for every operation, default to False.
- __call__(img, meta_data=None, mask=None)[source]#
Compute statistics for the intensity of input image.
- Parameters:
img – input image to compute intensity stats.
meta_data – metadata dictionary to store the statistics data, if None, will create an empty dictionary.
mask – if not None, mask the image to extract only the interested area to compute statistics. mask must have the same shape as input img.
ToDevice#
- class monai.transforms.ToDevice(device, **kwargs)[source]#
Move PyTorch Tensor to the specified device. It can help cache data into GPU and execute following logic on GPU directly.
Note
If moving data to GPU device in the multi-processing workers of DataLoader, may got below CUDA error: “RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the ‘spawn’ start method.” So usually suggest to set num_workers=0 in the DataLoader or ThreadDataLoader.
- __call__(img)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- __init__(device, **kwargs)[source]#
- Parameters:
device – target device to move the Tensor, for example: “cuda:1”.
kwargs – other args for the PyTorch Tensor.to() API, for more details: https://pytorch.org/docs/stable/generated/torch.Tensor.to.html.
CuCIM#
- class monai.transforms.CuCIM(name, *args, **kwargs)[source]#
Wrap a non-randomized cuCIM transform, defined based on the transform name and args. For randomized transforms use
monai.transforms.RandCuCIM.- Parameters:
name (
str) – the transform name in CuCIM packageargs – parameters for the CuCIM transform
kwargs – parameters for the CuCIM transform
Note
CuCIM transform only work with CuPy arrays, so this transform expects input data to be cupy.ndarray. Users can call ToCuPy transform to convert a numpy array or torch tensor to cupy array.
RandCuCIM#
- class monai.transforms.RandCuCIM(name, *args, **kwargs)[source]#
Wrap a randomized cuCIM transform, defined based on the transform name and args For deterministic non-randomized transforms use
monai.transforms.CuCIM.- Parameters:
name (
str) – the transform name in CuCIM package.args – parameters for the CuCIM transform.
kwargs – parameters for the CuCIM transform.
Note
CuCIM transform only work with CuPy arrays, so this transform expects input data to be cupy.ndarray. Users can call ToCuPy transform to convert a numpy array or torch tensor to cupy array.
If the random factor of the underlying cuCIM transform is not derived from self.R, the results may not be deterministic. See Also:
monai.transforms.Randomizable.
AddCoordinateChannels#
- class monai.transforms.AddCoordinateChannels(spatial_dims)[source]#
Appends additional channels encoding coordinates of the input. Useful when e.g. training using patch-based sampling, to allow feeding of the patch’s location into the network.
This can be seen as a input-only version of CoordConv:
Liu, R. et al. An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution, NeurIPS 2018.
- Parameters:
spatial_dims (
Sequence[int]) – the spatial dimensions that are to have their coordinates encoded in a channel and appended to the input image. E.g., (0, 1, 2) represents H, W, D dims and append three channels to the input image, encoding the coordinates of the input’s three spatial dimensions.
ImageFilter#
- class monai.transforms.ImageFilter(filter, filter_size=None, **kwargs)[source]#
Applies a convolution filter to the input image.
- Parameters:
filter – A string specifying the filter, a custom filter as
torch.Tenorornp.ndarrayor ann.Module. Available options for string are:mean,laplace,elliptical,sobel,sharpen,median,gaussSee below for short explanations on every filter.filter_size – A single integer value specifying the size of the quadratic or cubic filter. Computational complexity scales to the power of 2 (2D filter) or 3 (3D filter), which should be considered when choosing filter size.
kwargs – Additional arguments passed to filter function, required by
sobelandgauss. See below for details.
- Raises:
ValueError – When
filter_sizeis not an uneven integerValueError – When
filteris an array andndimis not in [1,2,3]ValueError – When
filteris an array and any dimension has an even shapeNotImplementedError – When
filteris a string and not inself.supported_filtersKeyError – When necessary
kwargsare not passed to a filter that requires additional arguments.
Mean Filtering:
filter='mean'Mean filtering can smooth edges and remove aliasing artifacts in an segmentation image. See also py:func:monai.networks.layers.simplelayers.MeanFilter Example 2D filter (5 x 5):
[[1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1]]
If smoothing labels with this filter, ensure they are in one-hot format.
Outline Detection:
filter='laplace'Laplacian filtering for outline detection in images. Can be used to transform labels to contours. See also py:func:monai.networks.layers.simplelayers.LaplaceFilter
Example 2D filter (5x5):
[[-1., -1., -1., -1., -1.], [-1., -1., -1., -1., -1.], [-1., -1., 24., -1., -1.], [-1., -1., -1., -1., -1.], [-1., -1., -1., -1., -1.]]
Dilation:
filter='elliptical'An elliptical filter can be used to dilate labels or label-contours. Example 2D filter (5x5):
[[0., 0., 1., 0., 0.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [0., 0., 1., 0., 0.]]
Edge Detection:
filter='sobel'This filter allows for additional arguments passed as
kwargsduring initialization. See also py:func:monai.transforms.post.SobelGradientskwargs
spatial_axes: the axes that define the direction of the gradient to be calculated. It calculates the gradient along each of the provide axis. By default it calculate the gradient for all spatial axes.normalize_kernels: if normalize the Sobel kernel to provide proper gradients. Defaults to True.normalize_gradients: if normalize the output gradient to 0 and 1. Defaults to False.padding_mode: the padding mode of the image when convolving with Sobel kernels. Defaults to"reflect". Acceptable values are'zeros','reflect','replicate'or'circular'. Seetorch.nn.Conv1d()for more information.dtype: kernel data type (torch.dtype). Defaults totorch.float32.
Sharpening:
filter='sharpen'Sharpen an image with a 2D or 3D filter. Example 2D filter (5x5):
[[ 0., 0., -1., 0., 0.], [-1., -1., -1., -1., -1.], [-1., -1., 17., -1., -1.], [-1., -1., -1., -1., -1.], [ 0., 0., -1., 0., 0.]]
Gaussian Smooth:
filter='gauss'Blur/smooth an image with 2D or 3D gaussian filter. This filter requires additional arguments passed as
kwargsduring initialization. See also py:func:monai.networks.layers.simplelayers.GaussianFilterkwargs
sigma: std. could be a single value, or spatial_dims number of values.truncated: spreads how many stds.approx: discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”.
Median Filter:
filter='median'Blur an image with 2D or 3D median filter to remove noise. Useful in image preprocessing to improve results of later processing. See also py:func:monai.networks.layers.simplelayers.MedianFilter
Savitzky Golay Filter:
filter = 'savitzky_golay'Convolve a Tensor along a particular axis with a Savitzky-Golay kernel. This filter requires additional arguments passed as
kwargsduring initialization. See also py:func:monai.networks.layers.simplelayers.SavitzkyGolayFilterkwargs
order: Order of the polynomial to fit to each window, must be less thanwindow_length.axis: (optional): Axis along which to apply the filter kernel. Default 2 (first spatial dimension).mode: (string, optional): padding mode passed to convolution class.'zeros','reflect','replicate'or'circular'. Default:'zeros'. See torch.nn.Conv1d() for more information.
- __call__(img, meta_dict=None, applied_operations=None)[source]#
- Parameters:
img – torch tensor data to apply filter to with shape: [channels, height, width[, depth]]
meta_dict – An optional dictionary with metadata
applied_operations – An optional list of operations that have been applied to the data
- Returns:
A MetaTensor with the same shape as img and identical metadata
RandImageFilter#
- class monai.transforms.RandImageFilter(filter, filter_size=None, prob=0.1, **kwargs)[source]#
Randomly apply a convolutional filter to the input data.
- Parameters:
filter – A string specifying the filter or a custom filter as torch.Tenor or np.ndarray. Available options are: mean, laplace, elliptical, gaussian` See below for short explanations on every filter.
filter_size – A single integer value specifying the size of the quadratic or cubic filter. Computational complexity scales to the power of 2 (2D filter) or 3 (3D filter), which should be considered when choosing filter size.
prob – Probability the transform is applied to the data
- __call__(img, meta_dict=None)[source]#
- Parameters:
img – torch tensor data to apply filter to with shape: [channels, height, width[, depth]]
meta_dict – An optional dictionary with metadata
kwargs – optional arguments required by specific filters. E.g. sigma`if filter is `gauss. see py:func:monai.transforms.utility.array.ImageFilter for more details
- Returns:
A MetaTensor with the same shape as img and identical metadata
Dictionary Transforms#
Crop and Pad (Dict)#
Padd#
- class monai.transforms.Padd(keys, padder, mode=constant, allow_missing_keys=False, lazy=False)[source]#
Dictionary-based wrapper of
monai.transforms.Pad.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, padder, mode=constant, allow_missing_keys=False, lazy=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformpadder (
Pad) – pad transform for the input image.mode (
Union[Sequence[str],str]) – available modes for numpy array:{"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html It also can be a sequence of string, each element corresponds to a key inkeys.allow_missing_keys (
bool) – don’t raise exception if key is missing.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,MetaTensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
SpatialPadd#
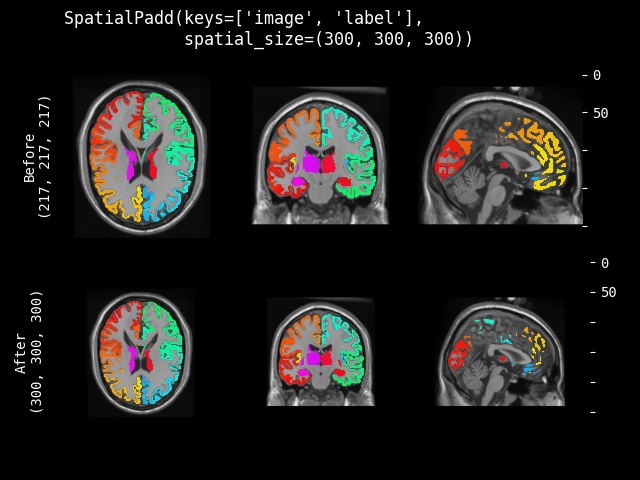
- class monai.transforms.SpatialPadd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.SpatialPad. Performs padding to the data, symmetric for all sides or all on one side for each dimension.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __init__(keys, spatial_size, method=symmetric, mode=constant, allow_missing_keys=False, lazy=False, **kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformspatial_size – the spatial size of output data after padding, if a dimension of the input data size is larger than the pad size, will not pad that dimension. If its components have non-positive values, the corresponding size of input image will be used. for example: if the spatial size of input data is [30, 30, 30] and spatial_size=[32, 25, -1], the spatial size of output data will be [32, 30, 30].
method – {
"symmetric","end"} Pad image symmetrically on every side or only pad at the end sides. Defaults to"symmetric".mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html It also can be a sequence of string, each element corresponds to a key inkeys.allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
BorderPadd#
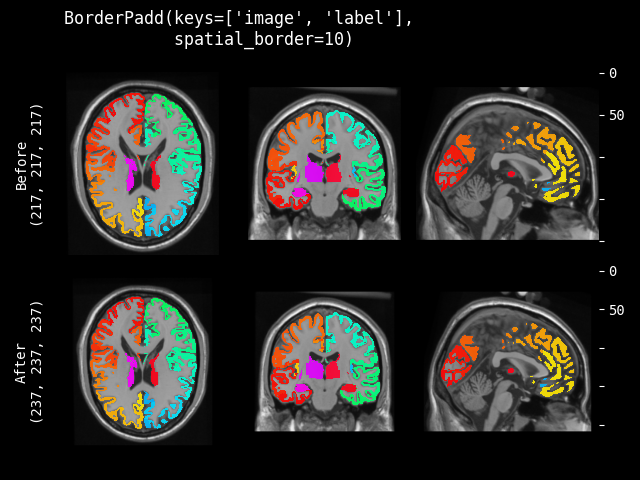
- class monai.transforms.BorderPadd(*args, **kwargs)[source]#
Pad the input data by adding specified borders to every dimension. Dictionary-based wrapper of
monai.transforms.BorderPad.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __init__(keys, spatial_border, mode=constant, allow_missing_keys=False, lazy=False, **kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformspatial_border –
specified size for every spatial border. it can be 3 shapes:
single int number, pad all the borders with the same size.
length equals the length of image shape, pad every spatial dimension separately. for example, image shape(CHW) is [1, 4, 4], spatial_border is [2, 1], pad every border of H dim with 2, pad every border of W dim with 1, result shape is [1, 8, 6].
length equals 2 x (length of image shape), pad every border of every dimension separately. for example, image shape(CHW) is [1, 4, 4], spatial_border is [1, 2, 3, 4], pad top of H dim with 1, pad bottom of H dim with 2, pad left of W dim with 3, pad right of W dim with 4. the result shape is [1, 7, 11].
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html It also can be a sequence of string, each element corresponds to a key inkeys.allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
DivisiblePadd#
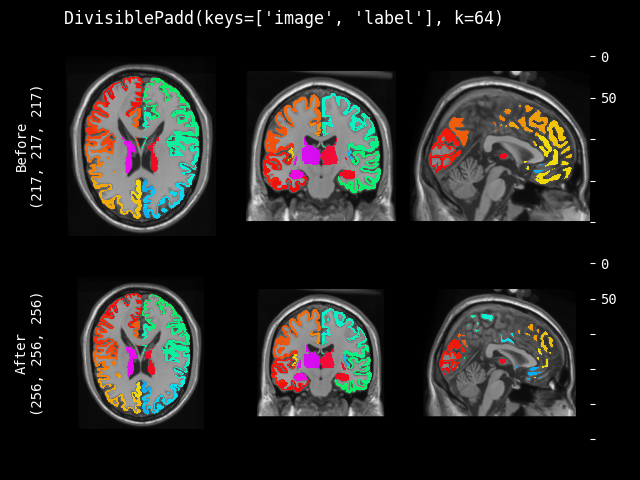
- class monai.transforms.DivisiblePadd(*args, **kwargs)[source]#
Pad the input data, so that the spatial sizes are divisible by k. Dictionary-based wrapper of
monai.transforms.DivisiblePad.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __init__(keys, k, mode=constant, method=symmetric, allow_missing_keys=False, lazy=False, **kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformk – the target k for each spatial dimension. if k is negative or 0, the original size is preserved. if k is an int, the same k be applied to all the input spatial dimensions.
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html It also can be a sequence of string, each element corresponds to a key inkeys.method – {
"symmetric","end"} Pad image symmetrically on every side or only pad at the end sides. Defaults to"symmetric".allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
See also
monai.transforms.SpatialPad
Cropd#
- class monai.transforms.Cropd(keys, cropper, allow_missing_keys=False, lazy=False)[source]#
Dictionary-based wrapper of abstract class
monai.transforms.Crop.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformcropper (
Crop) – crop transform for the input image.allow_missing_keys (
bool) – don’t raise exception if key is missing.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(data, lazy=None)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,MetaTensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
RandCropd#
- class monai.transforms.RandCropd(keys, cropper, allow_missing_keys=False, lazy=False)[source]#
Base class for random crop transform.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformcropper (
Crop) – random crop transform for the input image.allow_missing_keys (
bool) – don’t raise exception if key is missing.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- __call__(data, lazy=None)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- randomize(img_size)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
SpatialCropd#
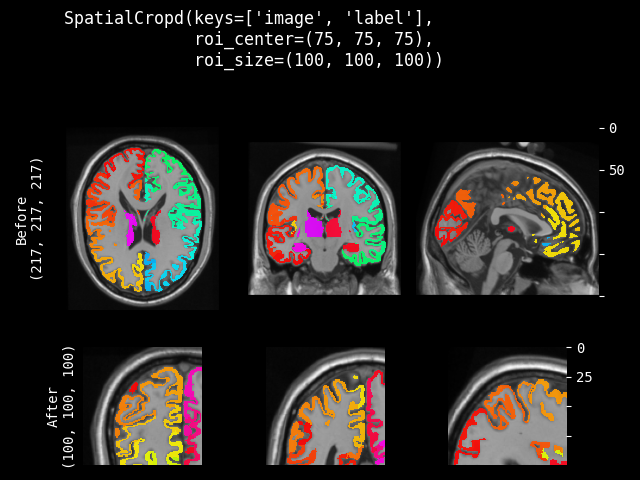
- class monai.transforms.SpatialCropd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.SpatialCrop. General purpose cropper to produce sub-volume region of interest (ROI). If a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape. It can support to crop ND spatial (channel-first) data.- The cropped region can be parameterised in various ways:
a list of slices for each spatial dimension (allows for use of -ve indexing and None)
a spatial center and size
the start and end coordinates of the ROI
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __init__(keys, roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None, allow_missing_keys=False, lazy=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformroi_center – voxel coordinates for center of the crop ROI.
roi_size – size of the crop ROI, if a dimension of ROI size is larger than image size, will not crop that dimension of the image.
roi_start – voxel coordinates for start of the crop ROI.
roi_end – voxel coordinates for end of the crop ROI, if a coordinate is out of image, use the end coordinate of image.
roi_slices – list of slices for each of the spatial dimensions.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
CenterSpatialCropd#
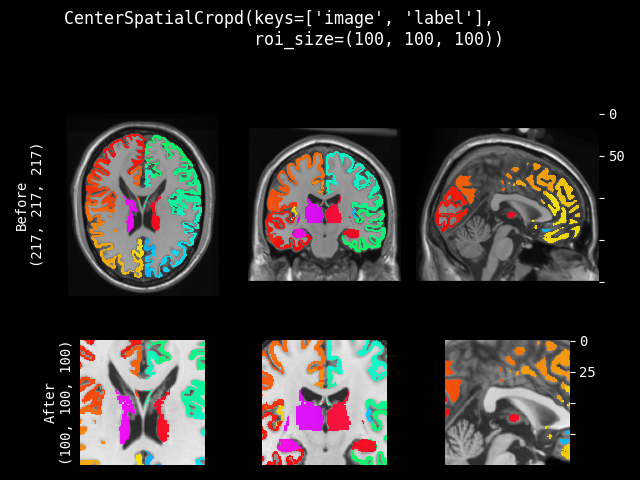
- class monai.transforms.CenterSpatialCropd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.CenterSpatialCrop. If a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
roi_size – the size of the crop region e.g. [224,224,128] if a dimension of ROI size is larger than image size, will not crop that dimension of the image. If its components have non-positive values, the corresponding size of input image will be used. for example: if the spatial size of input data is [40, 40, 40] and roi_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
RandSpatialCropd#
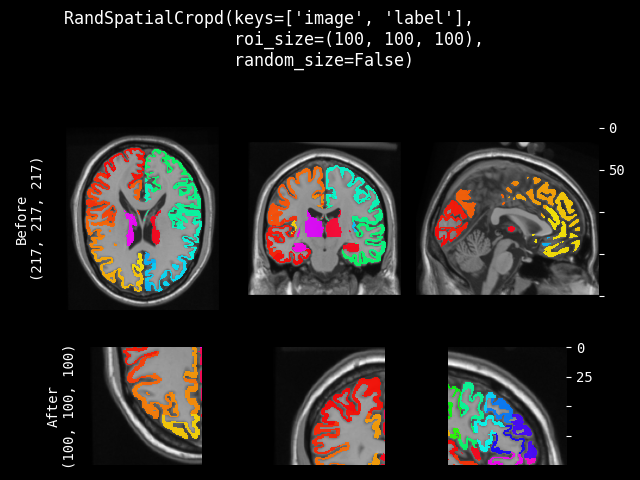
- class monai.transforms.RandSpatialCropd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandSpatialCrop. Crop image with random size or specific size ROI. It can crop at a random position as center or at the image center. And allows to set the minimum and maximum size to limit the randomly generated ROI. Suppose all the expected fields specified by keys have same shape.Note: even random_size=False, if a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
roi_size – if random_size is True, it specifies the minimum crop region. if random_size is False, it specifies the expected ROI size to crop. e.g. [224, 224, 128] if a dimension of ROI size is larger than image size, will not crop that dimension of the image. If its components have non-positive values, the corresponding size of input image will be used. for example: if the spatial size of input data is [40, 40, 40] and roi_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
max_roi_size – if random_size is True and roi_size specifies the min crop region size, max_roi_size can specify the max crop region size. if None, defaults to the input image size. if its components have non-positive values, the corresponding size of input image will be used.
random_center – crop at random position as center or the image center.
random_size – crop with random size or specific size ROI. if True, the actual size is sampled from: randint(roi_scale * image spatial size, max_roi_scale * image spatial size + 1).
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
RandSpatialCropSamplesd#
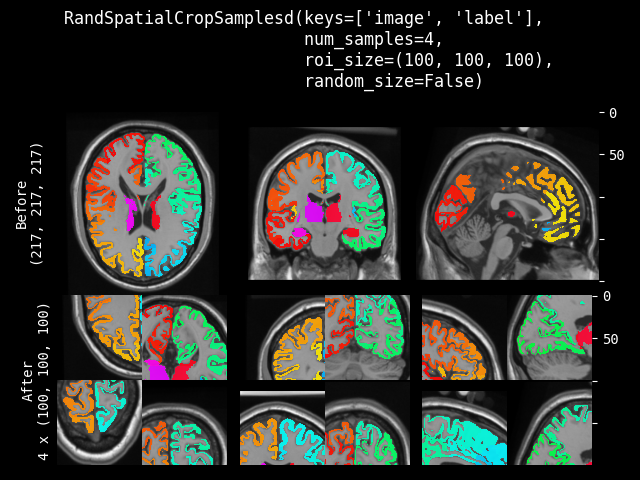
- class monai.transforms.RandSpatialCropSamplesd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandSpatialCropSamples. Crop image with random size or specific size ROI to generate a list of N samples. It can crop at a random position as center or at the image center. And allows to set the minimum size to limit the randomly generated ROI. Suppose all the expected fields specified by keys have same shape, and add patch_index to the corresponding metadata. It will return a list of dictionaries for all the cropped images.Note: even random_size=False, if a dimension of the expected ROI size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected ROI, and the cropped results of several images may not have exactly the same shape.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
roi_size – if random_size is True, it specifies the minimum crop region. if random_size is False, it specifies the expected ROI size to crop. e.g. [224, 224, 128] if a dimension of ROI size is larger than image size, will not crop that dimension of the image. If its components have non-positive values, the corresponding size of input image will be used. for example: if the spatial size of input data is [40, 40, 40] and roi_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
num_samples – number of samples (crop regions) to take in the returned list.
max_roi_size – if random_size is True and roi_size specifies the min crop region size, max_roi_size can specify the max crop region size. if None, defaults to the input image size. if its components have non-positive values, the corresponding size of input image will be used.
random_center – crop at random position as center or the image center.
random_size – crop with random size or specific size ROI. The actual size is sampled from randint(roi_size, img_size).
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- Raises:
ValueError – When
num_samplesis nonpositive.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
CropForegroundd#
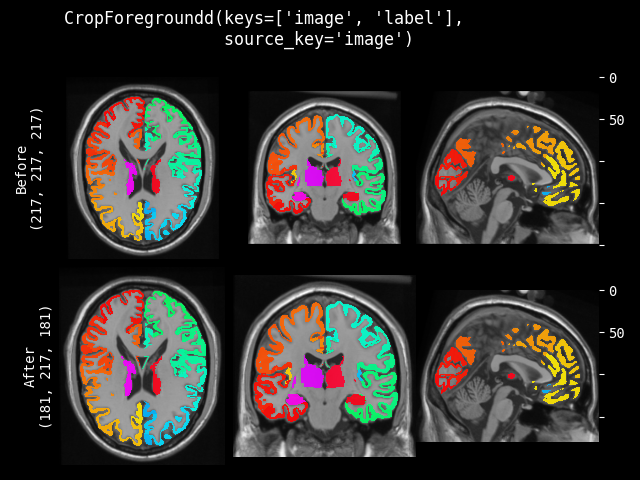
- class monai.transforms.CropForegroundd(keys, source_key, select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, k_divisible=1, mode=constant, start_coord_key='foreground_start_coord', end_coord_key='foreground_end_coord', allow_missing_keys=False, lazy=False, **pad_kwargs)[source]#
Dictionary-based version
monai.transforms.CropForeground. Crop only the foreground object of the expected images. The typical usage is to help training and evaluation if the valid part is small in the whole medical image. The valid part can be determined by any field in the data with source_key, for example: - Select values > 0 in image field as the foreground and crop on all fields specified by keys. - Select label = 3 in label field as the foreground to crop on all fields specified by keys. - Select label > 0 in the third channel of a One-Hot label field as the foreground to crop all keys fields. Users can define arbitrary function to select expected foreground from the whole source image or specified channels. And it can also add margin to every dim of the bounding box of foreground object.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, source_key, select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, k_divisible=1, mode=constant, start_coord_key='foreground_start_coord', end_coord_key='foreground_end_coord', allow_missing_keys=False, lazy=False, **pad_kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformsource_key – data source to generate the bounding box of foreground, can be image or label, etc.
select_fn – function to select expected foreground, default is to select values > 0.
channel_indices – if defined, select foreground only on the specified channels of image. if None, select foreground on the whole image.
margin – add margin value to spatial dims of the bounding box, if only 1 value provided, use it for all dims.
allow_smaller – when computing box size with margin, whether to allow the image edges to be smaller than the final box edges. If False, part of a padded output box might be outside of the original image, if True, the image edges will be used as the box edges. Default to True.
k_divisible – make each spatial dimension to be divisible by k, default to 1. if k_divisible is an int, the same k be applied to all the input spatial dimensions.
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html it also can be a sequence of string, each element corresponds to a key inkeys.start_coord_key – key to record the start coordinate of spatial bounding box for foreground.
end_coord_key – key to record the end coordinate of spatial bounding box for foreground.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
RandWeightedCropd#
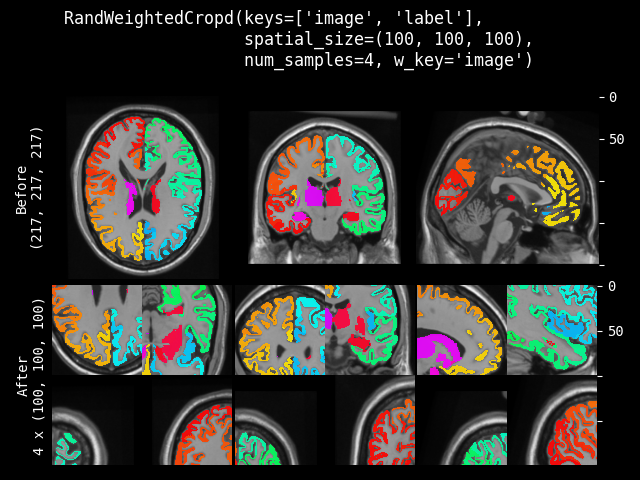
- class monai.transforms.RandWeightedCropd(*args, **kwargs)[source]#
Samples a list of num_samples image patches according to the provided weight_map.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformw_key – key for the weight map. The corresponding value will be used as the sampling weights, it should be a single-channel array in size, for example, (1, spatial_dim_0, spatial_dim_1, …)
spatial_size – the spatial size of the image patch e.g. [224, 224, 128]. If its components have non-positive values, the corresponding size of img will be used.
num_samples – number of samples (image patches) to take in the returned list.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
See also
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(weight_map)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandCropByPosNegLabeld#
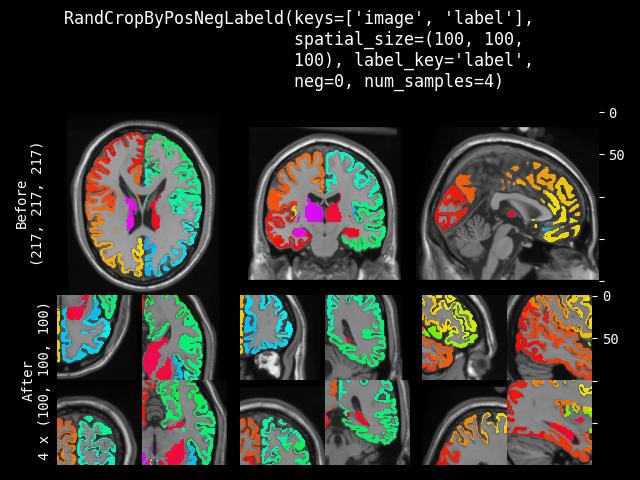
- class monai.transforms.RandCropByPosNegLabeld(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandCropByPosNegLabel. Crop random fixed sized regions with the center being a foreground or background voxel based on the Pos Neg Ratio. Suppose all the expected fields specified by keys have same shape, and add patch_index to the corresponding metadata. And will return a list of dictionaries for all the cropped images.If a dimension of the expected spatial size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than the expected size, and the cropped results of several images may not have exactly the same shape. And if the crop ROI is partly out of the image, will automatically adjust the crop center to ensure the valid crop ROI.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformlabel_key – name of key for label image, this will be used for finding foreground/background.
spatial_size – the spatial size of the crop region e.g. [224, 224, 128]. if a dimension of ROI size is larger than image size, will not crop that dimension of the image. if its components have non-positive values, the corresponding size of data[label_key] will be used. for example: if the spatial size of input data is [40, 40, 40] and spatial_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
pos – used with neg together to calculate the ratio
pos / (pos + neg)for the probability to pick a foreground voxel as a center rather than a background voxel.neg – used with pos together to calculate the ratio
pos / (pos + neg)for the probability to pick a foreground voxel as a center rather than a background voxel.num_samples – number of samples (crop regions) to take in each list.
image_key – if image_key is not None, use
label == 0 & image > image_thresholdto select the negative sample(background) center. so the crop center will only exist on valid image area.image_threshold – if enabled image_key, use
image > image_thresholdto determine the valid image content area.fg_indices_key – if provided pre-computed foreground indices of label, will ignore above image_key and image_threshold, and randomly select crop centers based on them, need to provide fg_indices_key and bg_indices_key together, expect to be 1 dim array of spatial indices after flattening. a typical usage is to call FgBgToIndicesd transform first and cache the results.
bg_indices_key – if provided pre-computed background indices of label, will ignore above image_key and image_threshold, and randomly select crop centers based on them, need to provide fg_indices_key and bg_indices_key together, expect to be 1 dim array of spatial indices after flattening. a typical usage is to call FgBgToIndicesd transform first and cache the results.
allow_smaller – if False, an exception will be raised if the image is smaller than the requested ROI in any dimension. If True, any smaller dimensions will be set to match the cropped size (i.e., no cropping in that dimension).
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- Raises:
ValueError – When
posornegare negative.ValueError – When
pos=0andneg=0. Incompatible values.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(label=None, fg_indices=None, bg_indices=None, image=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandCropByLabelClassesd#
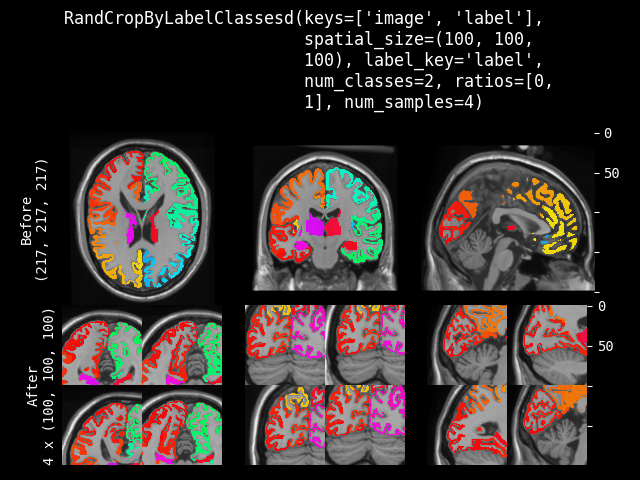
- class monai.transforms.RandCropByLabelClassesd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandCropByLabelClasses. Crop random fixed sized regions with the center being a class based on the specified ratios of every class. The label data can be One-Hot format array or Argmax data. And will return a list of arrays for all the cropped images. For example, crop two (3 x 3) arrays from (5 x 5) array with ratios=[1, 2, 3, 1]:cropper = RandCropByLabelClassesd( keys=["image", "label"], label_key="label", spatial_size=[3, 3], ratios=[1, 2, 3, 1], num_classes=4, num_samples=2, ) data = { "image": np.array([ [[0.0, 0.3, 0.4, 0.2, 0.0], [0.0, 0.1, 0.2, 0.1, 0.4], [0.0, 0.3, 0.5, 0.2, 0.0], [0.1, 0.2, 0.1, 0.1, 0.0], [0.0, 0.1, 0.2, 0.1, 0.0]] ]), "label": np.array([ [[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [0, 1, 3, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]] ]), } result = cropper(data) The 2 randomly cropped samples of `label` can be: [[0, 1, 2], [[0, 0, 0], [0, 1, 3], [1, 2, 1], [0, 0, 0]] [1, 3, 0]]If a dimension of the expected spatial size is larger than the input image size, will not crop that dimension. So the cropped result may be smaller than expected size, and the cropped results of several images may not have exactly same shape. And if the crop ROI is partly out of the image, will automatically adjust the crop center to ensure the valid crop ROI.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformlabel_key – name of key for label image, this will be used for finding indices of every class.
spatial_size – the spatial size of the crop region e.g. [224, 224, 128]. if a dimension of ROI size is larger than image size, will not crop that dimension of the image. if its components have non-positive values, the corresponding size of label will be used. for example: if the spatial size of input data is [40, 40, 40] and spatial_size=[32, 64, -1], the spatial size of output data will be [32, 40, 40].
ratios – specified ratios of every class in the label to generate crop centers, including background class. if None, every class will have the same ratio to generate crop centers.
num_classes – number of classes for argmax label, not necessary for One-Hot label.
num_samples – number of samples (crop regions) to take in each list.
image_key – if image_key is not None, only return the indices of every class that are within the valid region of the image (
image > image_threshold).image_threshold – if enabled image_key, use
image > image_thresholdto determine the valid image content area and select class indices only in this area.indices_key – if provided pre-computed indices of every class, will ignore above image and image_threshold, and randomly select crop centers based on them, expect to be 1 dim array of spatial indices after flattening. a typical usage is to call ClassesToIndices transform first and cache the results for better performance.
allow_smaller – if False, an exception will be raised if the image is smaller than the requested ROI in any dimension. If True, any smaller dimensions will remain unchanged.
allow_missing_keys – don’t raise exception if key is missing.
warn – if True prints a warning if a class is not present in the label.
max_samples_per_class – maximum length of indices in each class to reduce memory consumption. Default is None, no subsampling.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- randomize(label, indices=None, image=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- property requires_current_data#
Get whether the transform requires the input data to be up to date before the transform executes. Such transforms can still execute lazily by adding pending operations to the output tensors. :returns: True if the transform requires its inputs to be up to date and False if it does not
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
ResizeWithPadOrCropd#
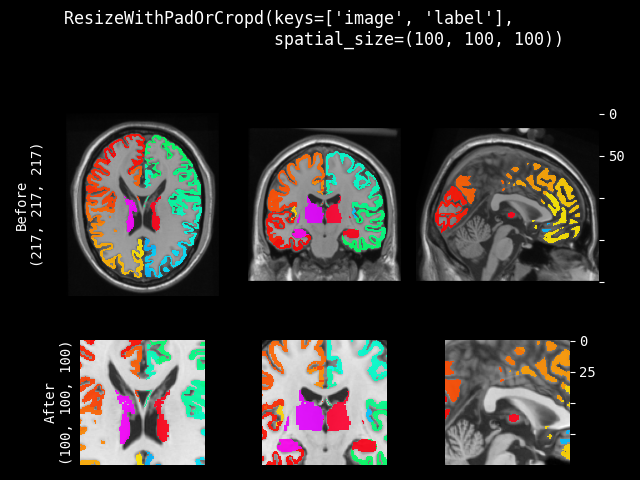
- class monai.transforms.ResizeWithPadOrCropd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ResizeWithPadOrCrop.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
spatial_size – the spatial size of output data after padding or crop. If has non-positive values, the corresponding size of input image will be used (no padding).
mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"constant". See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html It also can be a sequence of string, each element corresponds to a key inkeys.allow_missing_keys – don’t raise exception if key is missing.
method – {
"symmetric","end"} Pad image symmetrically on every side or only pad at the end sides. Defaults to"symmetric".lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
BoundingRectd#
- class monai.transforms.BoundingRectd(keys, bbox_key_postfix='bbox', select_fn=<function is_positive>, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.BoundingRect.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransformbbox_key_postfix (
str) – the output bounding box coordinates will be written to the value of {key}_{bbox_key_postfix}.select_fn (
Callable) – function to select expected foreground, default is to select values > 0.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- __call__(data)[source]#
See also:
monai.transforms.utils.generate_spatial_bounding_box.- Return type:
dict[Hashable,Union[ndarray,Tensor]]
RandScaleCropd#
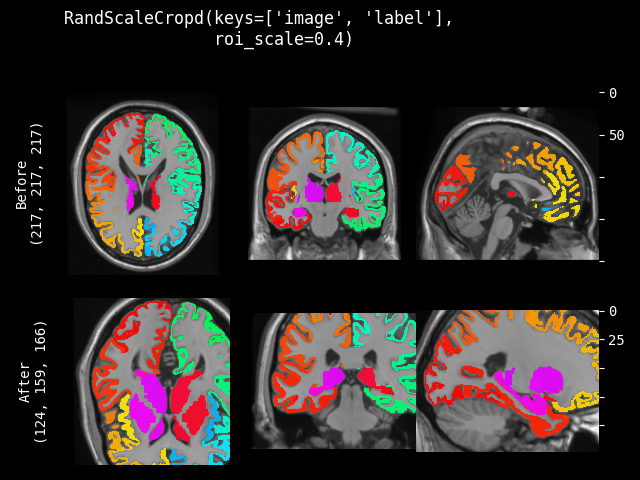
- class monai.transforms.RandScaleCropd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandScaleCrop. Crop image with random size or specific size ROI. It can crop at a random position as center or at the image center. And allows to set the minimum and maximum scale of image size to limit the randomly generated ROI. Suppose all the expected fields specified by keys have same shape.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
roi_scale – if random_size is True, it specifies the minimum crop size: roi_scale * image spatial size. if random_size is False, it specifies the expected scale of image size to crop. e.g. [0.3, 0.4, 0.5]. If its components have non-positive values, will use 1.0 instead, which means the input image size.
max_roi_scale – if random_size is True and roi_scale specifies the min crop region size, max_roi_scale can specify the max crop region size: max_roi_scale * image spatial size. if None, defaults to the input image size. if its components have non-positive values, will use 1.0 instead, which means the input image size.
random_center – crop at random position as center or the image center.
random_size – crop with random size or specified size ROI by roi_scale * image spatial size. if True, the actual size is sampled from: randint(roi_scale * image spatial size, max_roi_scale * image spatial size + 1).
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
CenterScaleCropd#
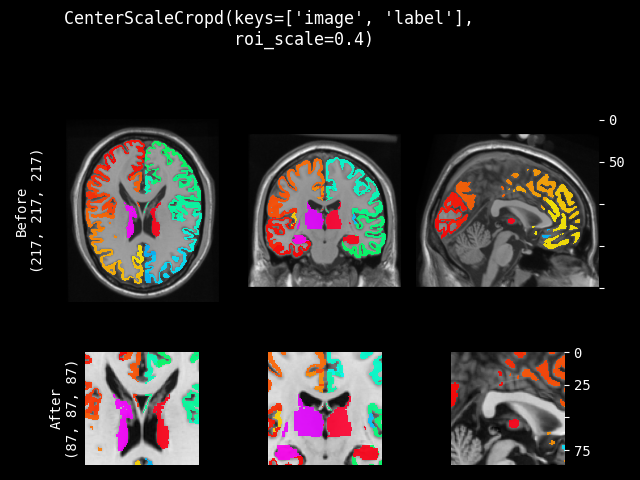
- class monai.transforms.CenterScaleCropd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.CenterScaleCrop. Note: as using the same scaled ROI to crop, all the input data specified by keys should have the same spatial shape.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
roi_scale – specifies the expected scale of image size to crop. e.g. [0.3, 0.4, 0.5] or a number for all dims. If its components have non-positive values, will use 1.0 instead, which means the input image size.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
Intensity (Dict)#
RandGaussianNoised#
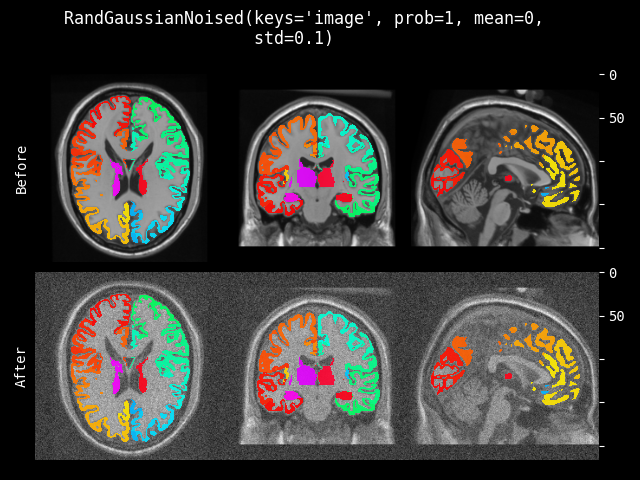
- class monai.transforms.RandGaussianNoised(keys, prob=0.1, mean=0.0, std=0.1, dtype=<class 'numpy.float32'>, allow_missing_keys=False, sample_std=True)[source]#
Dictionary-based version
monai.transforms.RandGaussianNoise. Add Gaussian noise to image. This transform assumes all the expected fields have same shape, if you want to add different noise for every field, please use this transform separately.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformprob (
float) – Probability to add Gaussian noise.mean (
float) – Mean or “centre” of the distribution.std (
float) – Standard deviation (spread) of distribution.dtype (
Union[dtype,type,str,None]) – output data type, if None, same as input image. defaults to float32.allow_missing_keys (
bool) – don’t raise exception if key is missing.sample_std (
bool) – If True, sample the spread of the Gaussian distribution uniformly from 0 to std.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
ShiftIntensityd#
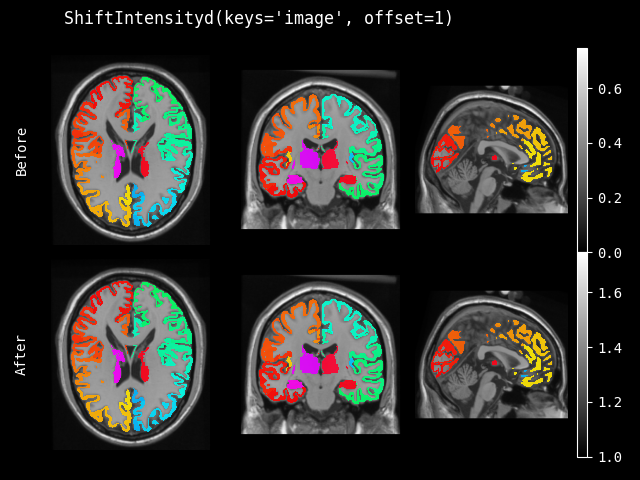
- class monai.transforms.ShiftIntensityd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ShiftIntensity.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, offset, safe=False, factor_key=None, meta_keys=None, meta_key_postfix='meta_dict', allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformoffset – offset value to shift the intensity of image.
safe – if True, then do safe dtype convert when intensity overflow. default to False. E.g., [256, -12] -> [array(0), array(244)]. If True, then [256, -12] -> [array(255), array(0)].
factor_key – if not None, use it as the key to extract a value from the corresponding metadata dictionary of key at runtime, and multiply the offset to shift intensity. Usually, IntensityStatsd transform can pre-compute statistics of intensity values and store in the metadata. it also can be a sequence of strings, map to keys.
meta_keys – explicitly indicate the key of the corresponding metadata dictionary. used to extract the factor value is factor_key is not None. for example, for data with key image, the metadata by default is in image_meta_dict. the metadata is a dictionary object which contains: filename, original_shape, etc. it can be a sequence of string, map to the keys. if None, will try to construct meta_keys by key_{meta_key_postfix}.
meta_key_postfix – if meta_keys is None, use key_{postfix} to fetch the metadata according to the key data, default is meta_dict, the metadata is a dictionary object. used to extract the factor value is factor_key is not None.
allow_missing_keys – don’t raise exception if key is missing.
RandShiftIntensityd#
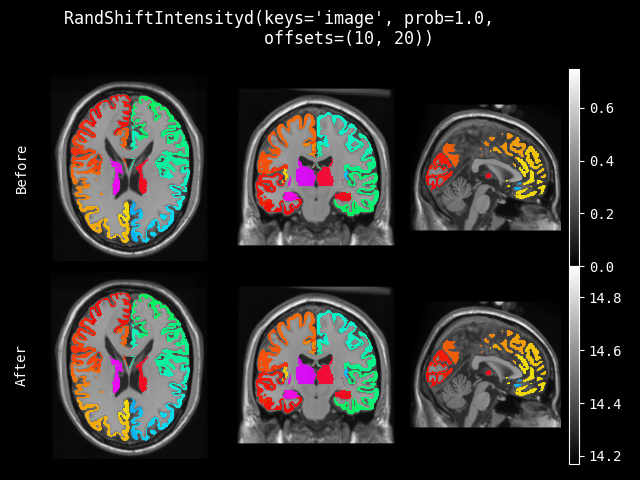
- class monai.transforms.RandShiftIntensityd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandShiftIntensity.- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, offsets, safe=False, factor_key=None, meta_keys=None, meta_key_postfix='meta_dict', prob=0.1, channel_wise=False, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformoffsets – offset range to randomly shift. if single number, offset value is picked from (-offsets, offsets).
safe – if True, then do safe dtype convert when intensity overflow. default to False. E.g., [256, -12] -> [array(0), array(244)]. If True, then [256, -12] -> [array(255), array(0)].
factor_key – if not None, use it as the key to extract a value from the corresponding metadata dictionary of key at runtime, and multiply the random offset to shift intensity. Usually, IntensityStatsd transform can pre-compute statistics of intensity values and store in the metadata. it also can be a sequence of strings, map to keys.
meta_keys – explicitly indicate the key of the corresponding metadata dictionary. used to extract the factor value is factor_key is not None. for example, for data with key image, the metadata by default is in image_meta_dict. the metadata is a dictionary object which contains: filename, original_shape, etc. it can be a sequence of string, map to the keys. if None, will try to construct meta_keys by key_{meta_key_postfix}.
meta_key_postfix – if meta_keys is None, use key_{postfix} to fetch the metadata according to the key data, default is meta_dict, the metadata is a dictionary object. used to extract the factor value is factor_key is not None.
prob – probability of shift. (Default 0.1, with 10% probability it returns an array shifted intensity.)
channel_wise – if True, shift intensity on each channel separately. For each channel, a random offset will be chosen. Please ensure that the first dimension represents the channel of the image if True.
allow_missing_keys – don’t raise exception if key is missing.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
StdShiftIntensityd#
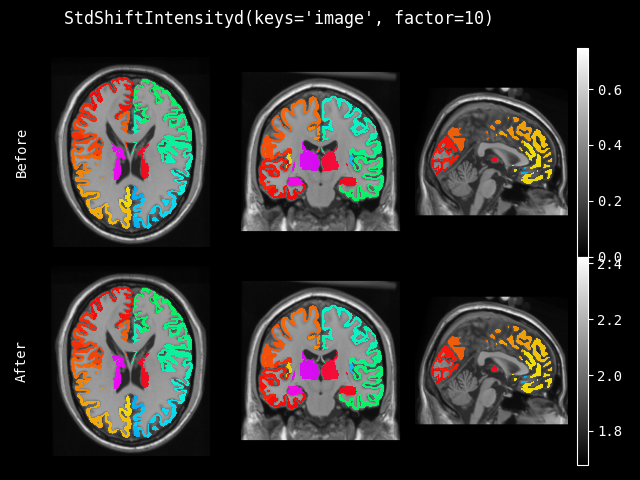
- class monai.transforms.StdShiftIntensityd(keys, factor, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.StdShiftIntensity.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, factor, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformfactor (
float) – factor shift byv = v + factor * std(v).nonzero (
bool) – whether only count non-zero values.channel_wise (
bool) – if True, calculate on each channel separately. Please ensure that the first dimension represents the channel of the image if True.dtype (
Union[dtype,type,str,None]) – output data type, if None, same as input image. defaults to float32.allow_missing_keys (
bool) – don’t raise exception if key is missing.
RandStdShiftIntensityd#
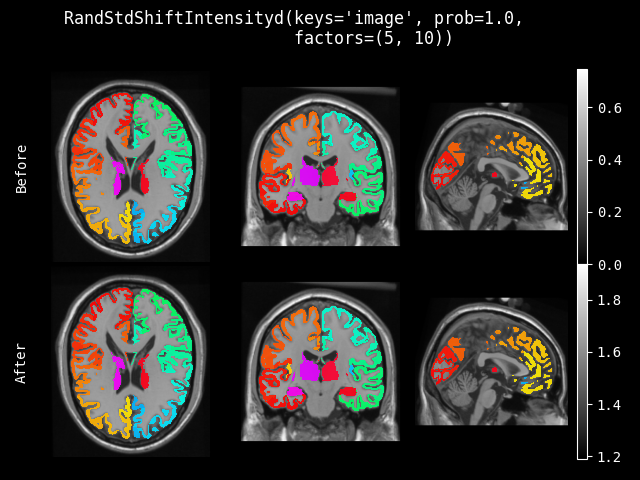
- class monai.transforms.RandStdShiftIntensityd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandStdShiftIntensity.- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, factors, prob=0.1, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformfactors – if tuple, the randomly picked range is (min(factors), max(factors)). If single number, the range is (-factors, factors).
prob – probability of std shift.
nonzero – whether only count non-zero values.
channel_wise – if True, calculate on each channel separately.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandBiasFieldd#
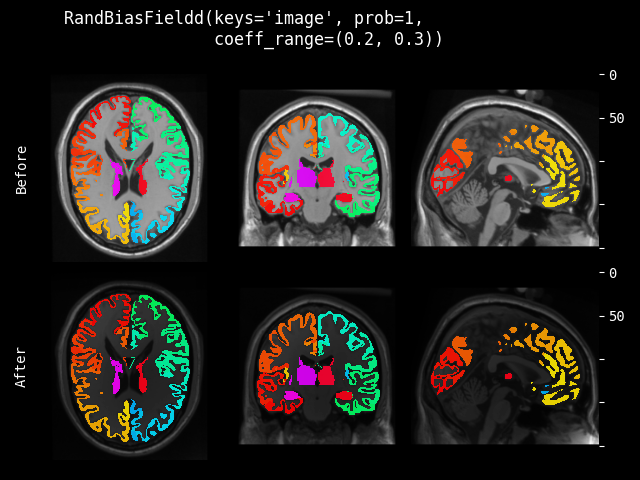
- class monai.transforms.RandBiasFieldd(keys, degree=3, coeff_range=(0.0, 0.1), dtype=<class 'numpy.float32'>, prob=0.1, allow_missing_keys=False)[source]#
Dictionary-based version
monai.transforms.RandBiasField.- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, degree=3, coeff_range=(0.0, 0.1), dtype=<class 'numpy.float32'>, prob=0.1, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformdegree (
int) – degree of freedom of the polynomials. The value should be no less than 1. Defaults to 3.coeff_range (
tuple[float,float]) – range of the random coefficients. Defaults to (0.0, 0.1).dtype (
Union[dtype,type,str,None]) – output data type, if None, same as input image. defaults to float32.prob (
float) – probability to do random bias field.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
ScaleIntensityd#
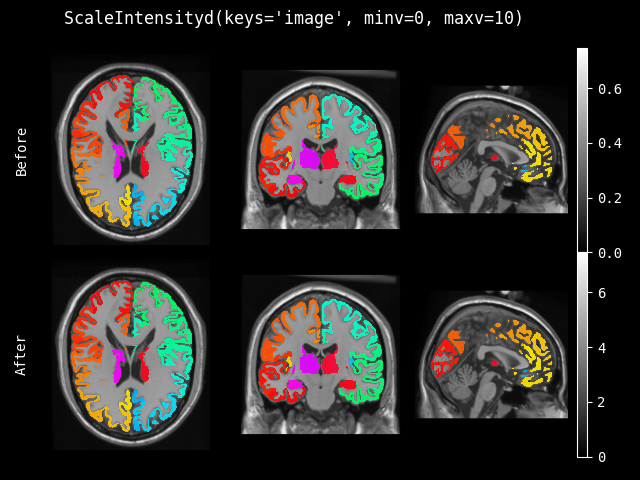
- class monai.transforms.ScaleIntensityd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ScaleIntensity. Scale the intensity of input image to the given value range (minv, maxv). If minv and maxv not provided, use factor to scale image byv = v * (1 + factor).- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, minv=0.0, maxv=1.0, factor=None, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformminv – minimum value of output data.
maxv – maximum value of output data.
factor – factor scale by
v = v * (1 + factor). In order to use this parameter, please set both minv and maxv into None.channel_wise – if True, scale on each channel separately. Please ensure that the first dimension represents the channel of the image if True.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
ClipIntensityPercentilesd#
- class monai.transforms.ClipIntensityPercentilesd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ClipIntensityPercentiles. Clip the intensity values of input image to a specific range based on the intensity distribution of the input. If sharpness_factor is provided, the intensity values will be soft clipped according to f(x) = x + (1/sharpness_factor) * softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv))- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict- Returns:
An updated dictionary version of
databy applying the transform.
RandScaleIntensityd#
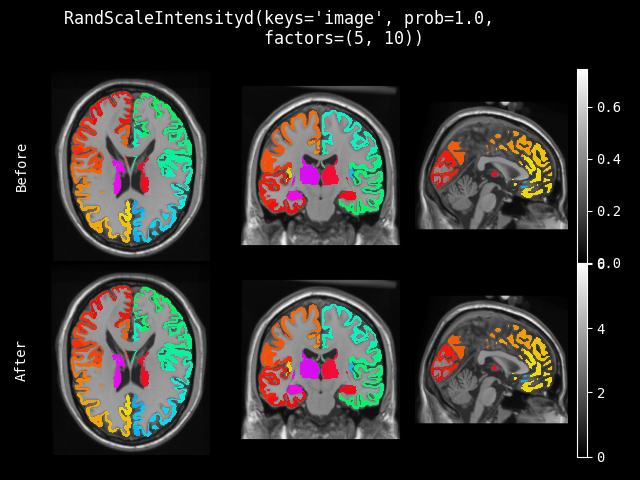
- class monai.transforms.RandScaleIntensityd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandScaleIntensity.- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, factors, prob=0.1, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformfactors – factor range to randomly scale by
v = v * (1 + factor). if single number, factor value is picked from (-factors, factors).prob – probability of scale. (Default 0.1, with 10% probability it returns a scaled array.)
channel_wise – if True, scale on each channel separately. Please ensure that the first dimension represents the channel of the image if True.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandScaleIntensityFixedMeand#
- class monai.transforms.RandScaleIntensityFixedMeand(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandScaleIntensity. Subtract the mean intensity before scaling with factor, then add the same value after scaling to ensure that the output has the same mean as the input.- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, factors, fixed_mean=True, preserve_range=False, prob=0.1, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformfactors – factor range to randomly scale by
v = v * (1 + factor). if single number, factor value is picked from (-factors, factors).preserve_range – clips the output array/tensor to the range of the input array/tensor
fixed_mean – subtract the mean intensity before scaling with factor, then add the same value after scaling to ensure that the output has the same mean as the input.
channel_wise – if True, scale on each channel separately. preserve_range and fixed_mean are also applied
the (on each channel separately if channel_wise is True. Please ensure that the first dimension represents)
True. (channel of the image if)
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
NormalizeIntensityd#
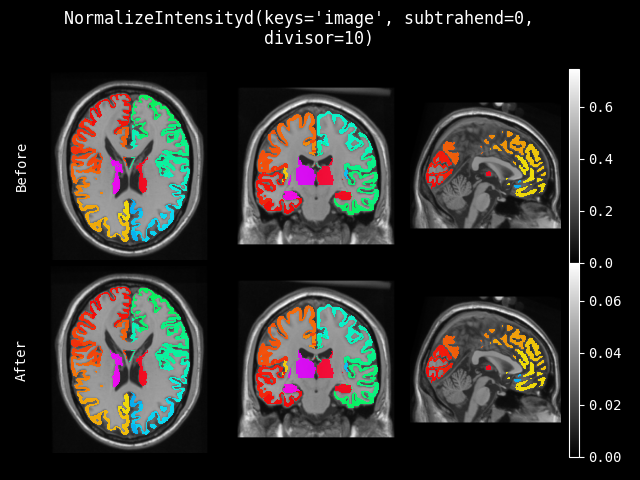
- class monai.transforms.NormalizeIntensityd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.NormalizeIntensity. This transform can normalize only non-zero values or entire image, and can also calculate mean and std on each channel separately.- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
subtrahend – the amount to subtract by (usually the mean)
divisor – the amount to divide by (usually the standard deviation)
nonzero – whether only normalize non-zero values.
channel_wise – if True, calculate on each channel separately, otherwise, calculate on the entire image directly. default to False.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ThresholdIntensityd#
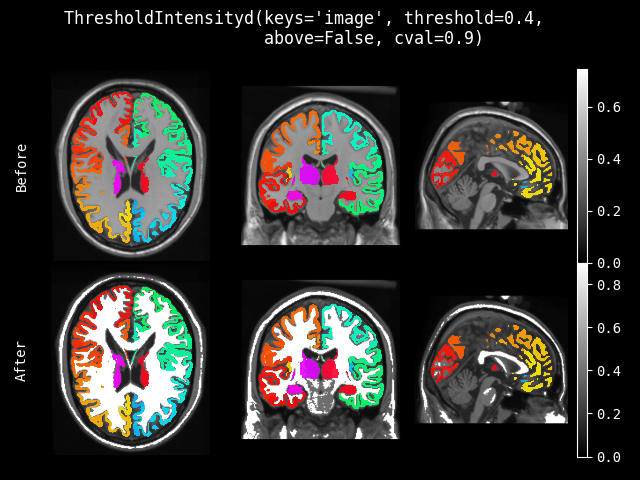
- class monai.transforms.ThresholdIntensityd(keys, threshold, above=True, cval=0.0, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.ThresholdIntensity.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransformthreshold (
float) – the threshold to filter intensity values.above (
bool) – filter values above the threshold or below the threshold, default is True.cval (
float) – value to fill the remaining parts of the image, default is 0.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ScaleIntensityRanged#
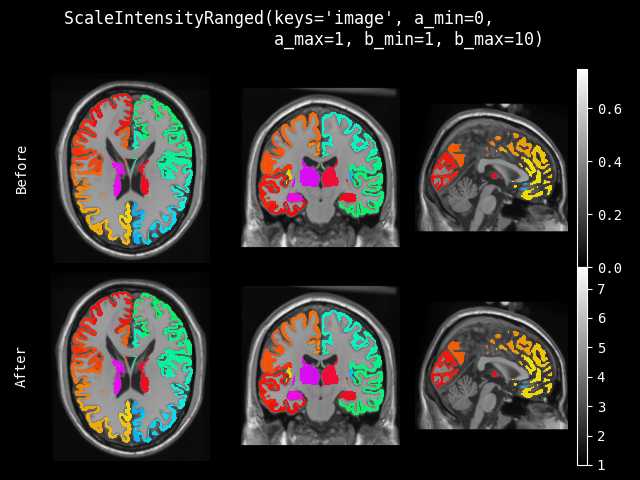
- class monai.transforms.ScaleIntensityRanged(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ScaleIntensityRange.- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
a_min – intensity original range min.
a_max – intensity original range max.
b_min – intensity target range min.
b_max – intensity target range max.
clip – whether to perform clip after scaling.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
GibbsNoised#
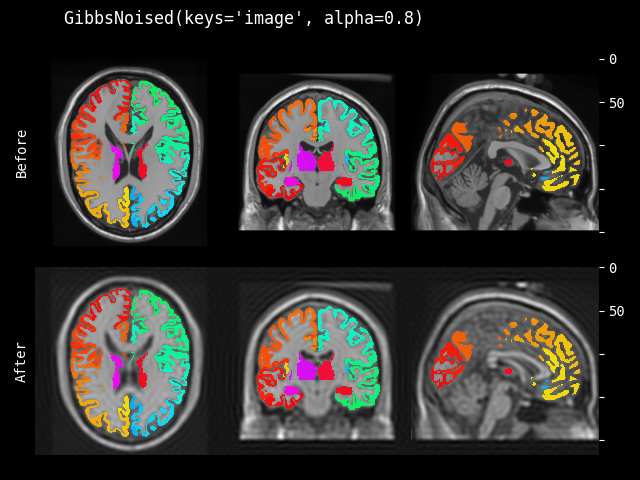
- class monai.transforms.GibbsNoised(keys, alpha=0.5, allow_missing_keys=False)[source]#
Dictionary-based version of GibbsNoise.
The transform applies Gibbs noise to 2D/3D MRI images. Gibbs artifacts are one of the common type of type artifacts appearing in MRI scans.
For general information on Gibbs artifacts, please refer to: https://pubs.rsna.org/doi/full/10.1148/rg.313105115 https://pubs.rsna.org/doi/full/10.1148/radiographics.22.4.g02jl14949
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – ‘image’, ‘label’, or [‘image’, ‘label’] depending on which data you need to transform.alpha (float) – Parametrizes the intensity of the Gibbs noise filter applied. Takes values in the interval [0,1] with alpha = 0 acting as the identity mapping.
allow_missing_keys (
bool) – do not raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
RandGibbsNoised#
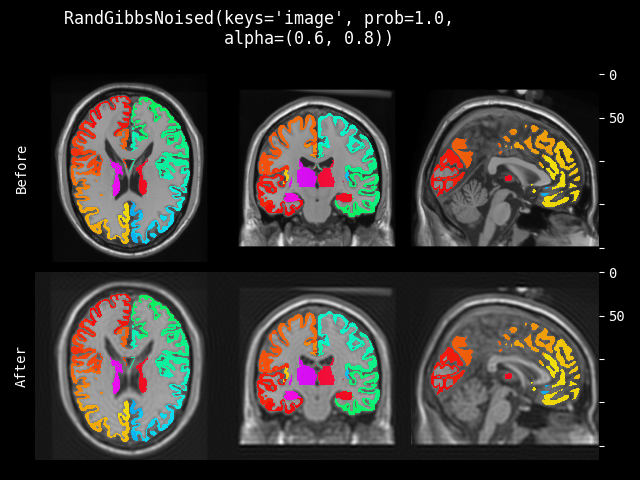
- class monai.transforms.RandGibbsNoised(*args, **kwargs)[source]#
Dictionary-based version of RandGibbsNoise.
Naturalistic image augmentation via Gibbs artifacts. The transform randomly applies Gibbs noise to 2D/3D MRI images. Gibbs artifacts are one of the common type of type artifacts appearing in MRI scans.
The transform is applied to all the channels in the data.
For general information on Gibbs artifacts, please refer to: https://pubs.rsna.org/doi/full/10.1148/rg.313105115 https://pubs.rsna.org/doi/full/10.1148/radiographics.22.4.g02jl14949
- Parameters:
keys – ‘image’, ‘label’, or [‘image’, ‘label’] depending on which data you need to transform.
prob (float) – probability of applying the transform.
alpha (float, Sequence[float]) – Parametrizes the intensity of the Gibbs noise filter applied. Takes values in the interval [0,1] with alpha = 0 acting as the identity mapping. If a length-2 list is given as [a,b] then the value of alpha will be sampled uniformly from the interval [a,b]. If a float is given, then the value of alpha will be sampled uniformly from the interval [0, alpha].
allow_missing_keys – do not raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
KSpaceSpikeNoised#
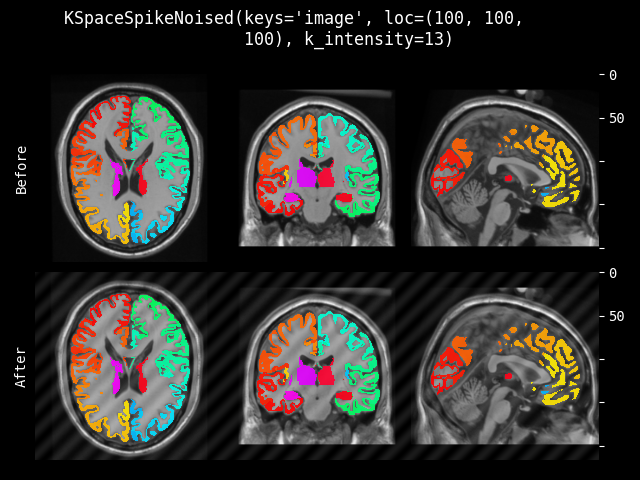
- class monai.transforms.KSpaceSpikeNoised(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.KSpaceSpikeNoise.Applies localized spikes in k-space at the given locations and intensities. Spike (Herringbone) artifact is a type of data acquisition artifact which may occur during MRI scans.
For general information on spike artifacts, please refer to:
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- Parameters:
keys – “image”, “label”, or [“image”, “label”] depending on which data you need to transform.
loc – spatial location for the spikes. For images with 3D spatial dimensions, the user can provide (C, X, Y, Z) to fix which channel C is affected, or (X, Y, Z) to place the same spike in all channels. For 2D cases, the user can provide (C, X, Y) or (X, Y).
k_intensity – value for the log-intensity of the k-space version of the image. If one location is passed to
locor the channel is not specified, then this argument should receive a float. Iflocis given a sequence of locations, then this argument should receive a sequence of intensities. This value should be tested as it is data-dependent. The default values are the 2.5 the mean of the log-intensity for each channel.allow_missing_keys – do not raise exception if key is missing.
Example
When working with 4D data,
KSpaceSpikeNoised("image", loc = ((3,60,64,32), (64,60,32)), k_intensity = (13,14))will place a spike at [3, 60, 64, 32] with log-intensity = 13, and one spike per channel located respectively at [: , 64, 60, 32] with log-intensity = 14.
RandKSpaceSpikeNoised#
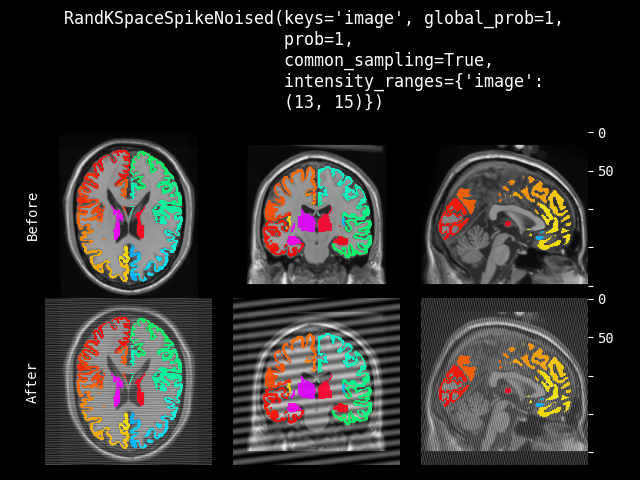
- class monai.transforms.RandKSpaceSpikeNoised(*args, **kwargs)[source]#
Dictionary-based version of
monai.transforms.RandKSpaceSpikeNoise.Naturalistic data augmentation via spike artifacts. The transform applies localized spikes in k-space.
For general information on spike artifacts, please refer to:
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- Parameters:
keys – “image”, “label”, or [“image”, “label”] depending on which data you need to transform.
prob – probability to add spike artifact to each item in the dictionary provided it is realized that the noise will be applied to the dictionary.
intensity_range – pass a tuple (a, b) to sample the log-intensity from the interval (a, b) uniformly for all channels. Or pass sequence of intervals ((a0, b0), (a1, b1), …) to sample for each respective channel. In the second case, the number of 2-tuples must match the number of channels. Default ranges is (0.95x, 1.10x) where x is the mean log-intensity for each channel.
channel_wise – treat each channel independently. True by default.
allow_missing_keys – do not raise exception if key is missing.
Example
To apply k-space spikes randomly on the image only, with probability 0.5, and log-intensity sampled from the interval [13, 15] for each channel independently, one uses
RandKSpaceSpikeNoised("image", prob=0.5, intensity_ranges=(13, 15), channel_wise=True).- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandRicianNoised#
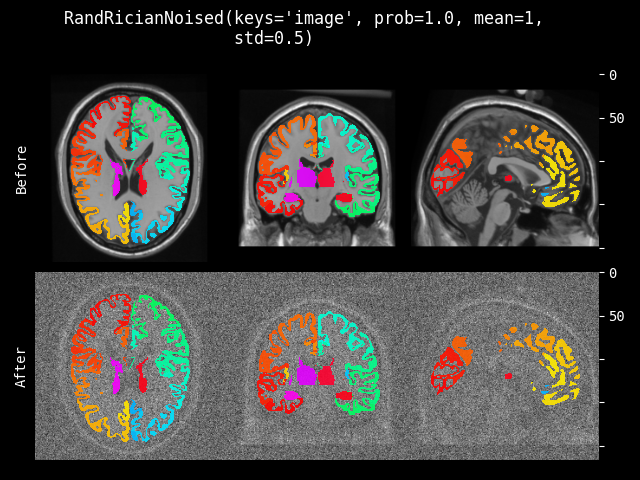
- class monai.transforms.RandRicianNoised(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandRicianNoise. Add Rician noise to image. This transform assumes all the expected fields have same shape, if want to add different noise for every field, please use this transform separately.- Parameters:
keys – Keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformprob – Probability to add Rician noise to the dictionary.
mean – Mean or “centre” of the Gaussian distributions sampled to make up the Rician noise.
std – Standard deviation (spread) of the Gaussian distributions sampled to make up the Rician noise.
channel_wise – If True, treats each channel of the image separately.
relative – If True, the spread of the sampled Gaussian distributions will be std times the standard deviation of the image or channel’s intensity histogram.
sample_std – If True, sample the spread of the Gaussian distributions uniformly from 0 to std.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – Don’t raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
ScaleIntensityRangePercentilesd#
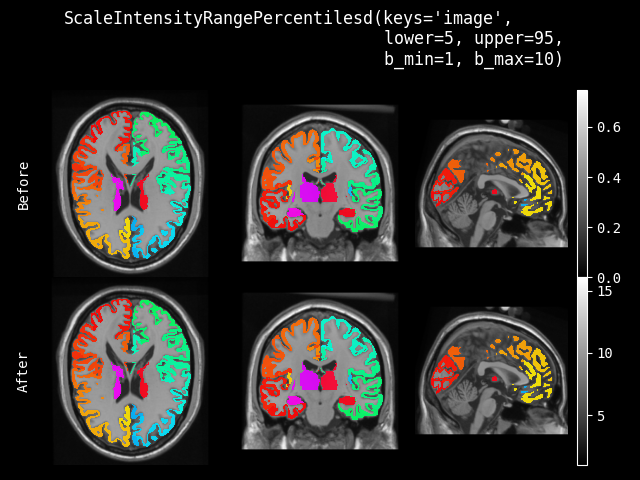
- class monai.transforms.ScaleIntensityRangePercentilesd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ScaleIntensityRangePercentiles.- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
lower – lower percentile.
upper – upper percentile.
b_min – intensity target range min.
b_max – intensity target range max.
clip – whether to perform clip after scaling.
relative – whether to scale to the corresponding percentiles of [b_min, b_max]
channel_wise – if True, compute intensity percentile and normalize every channel separately. default to False.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
AdjustContrastd#
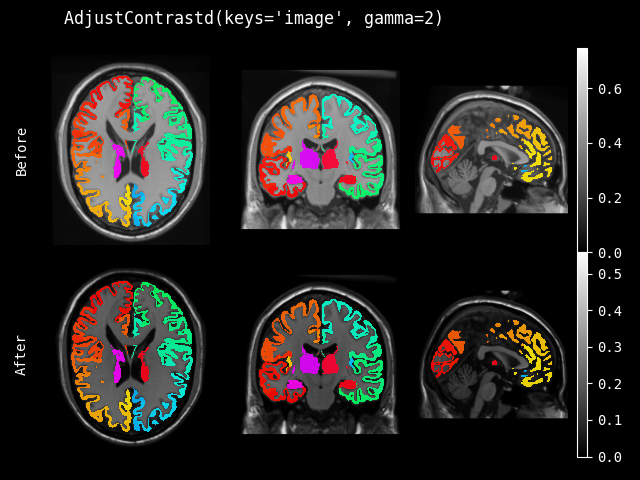
- class monai.transforms.AdjustContrastd(keys, gamma, invert_image=False, retain_stats=False, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.AdjustContrast. Changes image intensity with gamma transform. Each pixel/voxel intensity is updated as:x = ((x - min) / intensity_range) ^ gamma * intensity_range + min
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransformgamma (
float) – gamma value to adjust the contrast as function.invert_image (
bool) –whether to invert the image before applying gamma augmentation. If True, multiply all intensity values with -1 before the gamma transform and again after the gamma transform. This behaviour is mimicked from nnU-Net, specifically this function.
retain_stats (
bool) –if True, applies a scaling factor and an offset to all intensity values after gamma transform to ensure that the output intensity distribution has the same mean and standard deviation as the intensity distribution of the input. This behaviour is mimicked from nnU-Net, specifically this function.
allow_missing_keys (
bool) – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
RandAdjustContrastd#
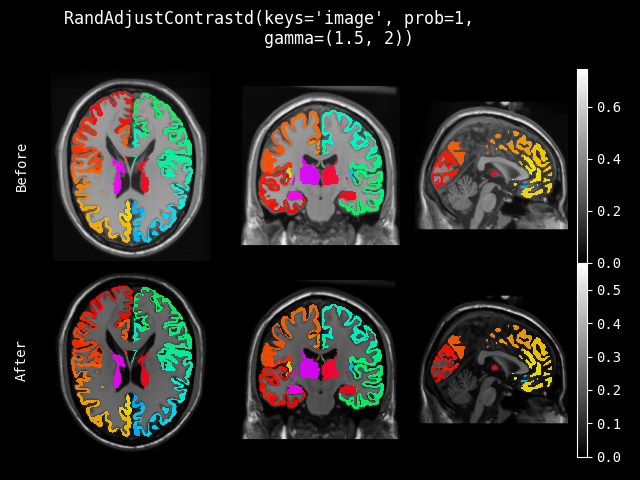
- class monai.transforms.RandAdjustContrastd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandAdjustContrast. Randomly changes image intensity with gamma transform. Each pixel/voxel intensity is updated as:x = ((x - min) / intensity_range) ^ gamma * intensity_range + min
- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
prob – Probability of adjustment.
gamma – Range of gamma values. If single number, value is picked from (0.5, gamma), default is (0.5, 4.5).
invert_image –
whether to invert the image before applying gamma augmentation. If True, multiply all intensity values with -1 before the gamma transform and again after the gamma transform. This behaviour is mimicked from nnU-Net, specifically this function.
retain_stats –
if True, applies a scaling factor and an offset to all intensity values after gamma transform to ensure that the output intensity distribution has the same mean and standard deviation as the intensity distribution of the input. This behaviour is mimicked from nnU-Net, specifically this function.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
MaskIntensityd#
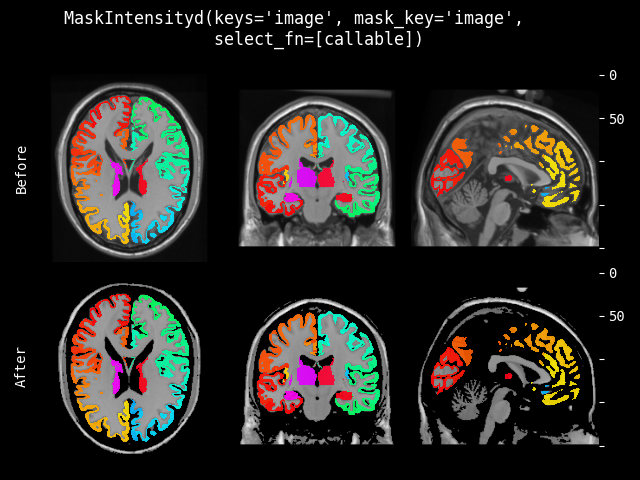
- class monai.transforms.MaskIntensityd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.MaskIntensity.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformmask_data – if mask data is single channel, apply to every channel of input image. if multiple channels, the channel number must match input data. the intensity values of input image corresponding to the selected values in the mask data will keep the original value, others will be set to 0. if None, will extract the mask data from input data based on mask_key.
mask_key – the key to extract mask data from input dictionary, only works when mask_data is None.
select_fn – function to select valid values of the mask_data, default is to select values > 0.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
SavitzkyGolaySmoothd#
- class monai.transforms.SavitzkyGolaySmoothd(keys, window_length, order, axis=1, mode='zeros', allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.SavitzkyGolaySmooth.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformwindow_length (
int) – length of the filter window, must be a positive odd integer.order (
int) – order of the polynomial to fit to each window, must be less thanwindow_length.axis (
int) – optional axis along which to apply the filter kernel. Default 1 (first spatial dimension).mode (
str) – optional padding mode, passed to convolution class.'zeros','reflect','replicate'or'circular'. default:'zeros'. Seetorch.nn.Conv1d()for more information.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
MedianSmoothd#
- class monai.transforms.MedianSmoothd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.MedianSmooth.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformradius – if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
GaussianSmoothd#
- class monai.transforms.GaussianSmoothd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.GaussianSmooth.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformsigma – if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
approx – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see also
monai.networks.layers.GaussianFilter().allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
RandGaussianSmoothd#
- class monai.transforms.RandGaussianSmoothd(keys, sigma_x=(0.25, 1.5), sigma_y=(0.25, 1.5), sigma_z=(0.25, 1.5), approx='erf', prob=0.1, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.GaussianSmooth.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformsigma_x (
tuple[float,float]) – randomly select sigma value for the first spatial dimension.sigma_y (
tuple[float,float]) – randomly select sigma value for the second spatial dimension if have.sigma_z (
tuple[float,float]) – randomly select sigma value for the third spatial dimension if have.approx (
str) – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see alsomonai.networks.layers.GaussianFilter().prob (
float) – probability of Gaussian smooth.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
GaussianSharpend#
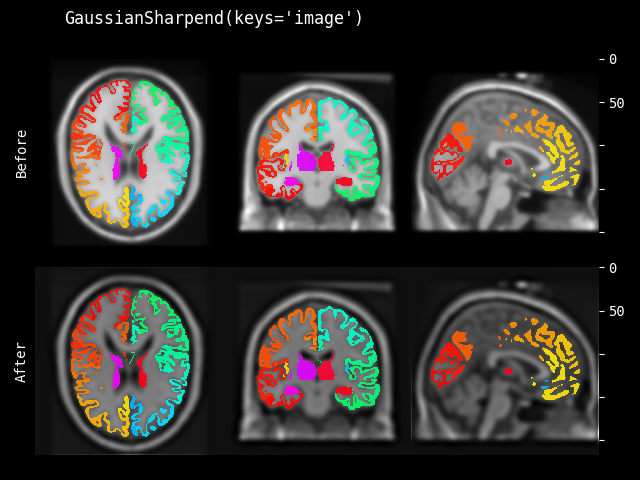
- class monai.transforms.GaussianSharpend(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.GaussianSharpen.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformsigma1 – sigma parameter for the first gaussian kernel. if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
sigma2 – sigma parameter for the second gaussian kernel. if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
alpha – weight parameter to compute the final result.
approx – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see also
monai.networks.layers.GaussianFilter().allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
RandGaussianSharpend#
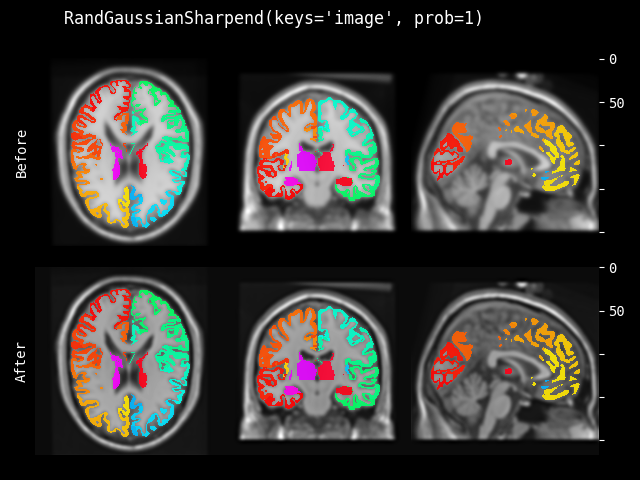
- class monai.transforms.RandGaussianSharpend(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.GaussianSharpen.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformsigma1_x – randomly select sigma value for the first spatial dimension of first gaussian kernel.
sigma1_y – randomly select sigma value for the second spatial dimension(if have) of first gaussian kernel.
sigma1_z – randomly select sigma value for the third spatial dimension(if have) of first gaussian kernel.
sigma2_x – randomly select sigma value for the first spatial dimension of second gaussian kernel. if only 1 value X provided, it must be smaller than sigma1_x and randomly select from [X, sigma1_x].
sigma2_y – randomly select sigma value for the second spatial dimension(if have) of second gaussian kernel. if only 1 value Y provided, it must be smaller than sigma1_y and randomly select from [Y, sigma1_y].
sigma2_z – randomly select sigma value for the third spatial dimension(if have) of second gaussian kernel. if only 1 value Z provided, it must be smaller than sigma1_z and randomly select from [Z, sigma1_z].
alpha – randomly select weight parameter to compute the final result.
approx – discrete Gaussian kernel type, available options are “erf”, “sampled”, and “scalespace”. see also
monai.networks.layers.GaussianFilter().prob – probability of Gaussian sharpen.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandHistogramShiftd#
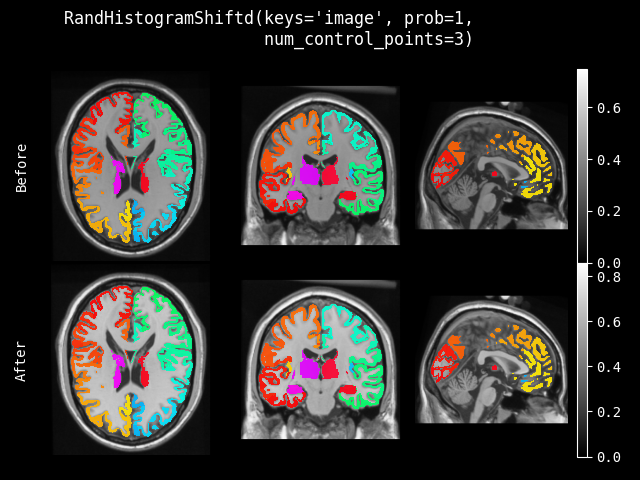
- class monai.transforms.RandHistogramShiftd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandHistogramShift. Apply random nonlinear transform the image’s intensity histogram.- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
num_control_points – number of control points governing the nonlinear intensity mapping. a smaller number of control points allows for larger intensity shifts. if two values provided, number of control points selecting from range (min_value, max_value).
prob – probability of histogram shift.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandCoarseDropoutd#
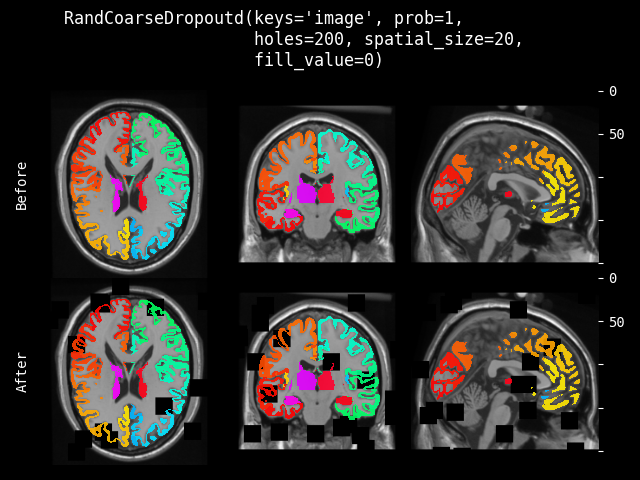
- class monai.transforms.RandCoarseDropoutd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.RandCoarseDropout. Expect all the data specified by keys have same spatial shape and will randomly dropout the same regions for every key, if want to dropout differently for every key, please use this transform separately.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformholes – number of regions to dropout, if max_holes is not None, use this arg as the minimum number to randomly select the expected number of regions.
spatial_size – spatial size of the regions to dropout, if max_spatial_size is not None, use this arg as the minimum spatial size to randomly select size for every region. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
dropout_holes – if True, dropout the regions of holes and fill value, if False, keep the holes and dropout the outside and fill value. default to True.
fill_value – target value to fill the dropout regions, if providing a number, will use it as constant value to fill all the regions. if providing a tuple for the min and max, will randomly select value for every pixel / voxel from the range [min, max). if None, will compute the min and max value of input image then randomly select value to fill, default to None.
max_holes – if not None, define the maximum number to randomly select the expected number of regions.
max_spatial_size – if not None, define the maximum spatial size to randomly select size for every region. if some components of the max_spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, max_spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
prob – probability of applying the transform.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandCoarseShuffled#
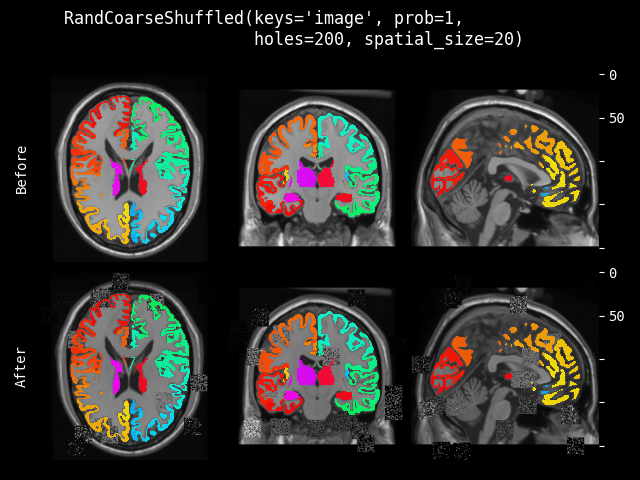
- class monai.transforms.RandCoarseShuffled(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.RandCoarseShuffle. Expect all the data specified by keys have same spatial shape and will randomly dropout the same regions for every key, if want to shuffle different regions for every key, please use this transform separately.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformholes – number of regions to dropout, if max_holes is not None, use this arg as the minimum number to randomly select the expected number of regions.
spatial_size – spatial size of the regions to dropout, if max_spatial_size is not None, use this arg as the minimum spatial size to randomly select size for every region. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
max_holes – if not None, define the maximum number to randomly select the expected number of regions.
max_spatial_size – if not None, define the maximum spatial size to randomly select size for every region. if some components of the max_spatial_size are non-positive values, the transform will use the corresponding components of input img size. For example, max_spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
prob – probability of applying the transform.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
HistogramNormalized#
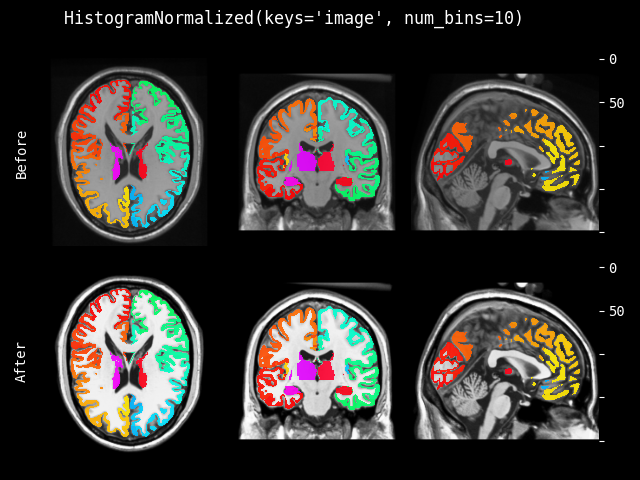
- class monai.transforms.HistogramNormalized(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.HistogramNormalize.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformnum_bins – number of the bins to use in histogram, default to 256. for more details: https://numpy.org/doc/stable/reference/generated/numpy.histogram.html.
min – the min value to normalize input image, default to 255.
max – the max value to normalize input image, default to 255.
mask – if provided, must be ndarray of bools or 0s and 1s, and same shape as image. only points at which mask==True are used for the equalization. can also provide the mask by mask_key at runtime.
mask_key – if mask is None, will try to get the mask with mask_key.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – do not raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ForegroundMaskd#
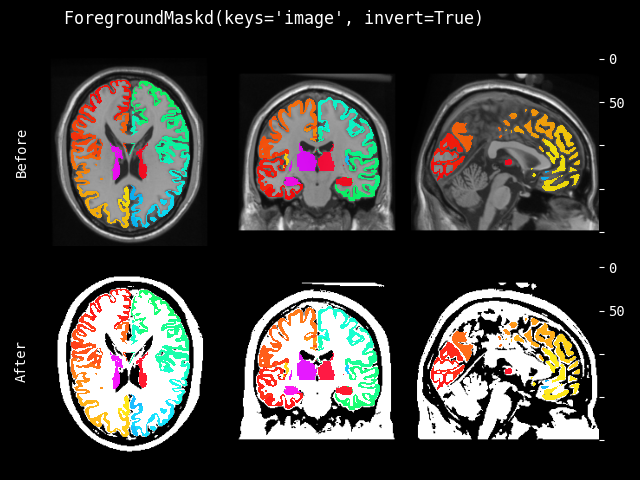
- class monai.transforms.ForegroundMaskd(*args, **kwargs)[source]#
Creates a binary mask that defines the foreground based on thresholds in RGB or HSV color space. This transform receives an RGB (or grayscale) image where by default it is assumed that the foreground has low values (dark) while the background is white.
- Parameters:
keys – keys of the corresponding items to be transformed.
threshold – an int or a float number that defines the threshold that values less than that are foreground. It also can be a callable that receives each dimension of the image and calculate the threshold, or a string that defines such callable from skimage.filter.threshold_…. For the list of available threshold functions, please refer to https://scikit-image.org/docs/stable/api/skimage.filters.html Moreover, a dictionary can be passed that defines such thresholds for each channel, like {“R”: 100, “G”: “otsu”, “B”: skimage.filter.threshold_mean}
hsv_threshold – similar to threshold but HSV color space (“H”, “S”, and “V”). Unlike RBG, in HSV, value greater than hsv_threshold are considered foreground.
invert – invert the intensity range of the input image, so that the dtype maximum is now the dtype minimum, and vice-versa.
new_key_prefix – this prefix be prepended to the key to create a new key for the output and keep the value of key intact. By default not prefix is set and the corresponding array to the key will be replaced.
allow_missing_keys – do not raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ComputeHoVerMapsd#
- class monai.transforms.ComputeHoVerMapsd(keys, dtype='float32', new_key_prefix='hover_', allow_missing_keys=False)[source]#
Compute horizontal and vertical maps from an instance mask It generates normalized horizontal and vertical distances to the center of mass of each region.
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed.dtype (
Union[dtype,type,str,None]) – the type of output Tensor. Defaults to “float32”.new_key_prefix (
str) – this prefix be prepended to the key to create a new key for the output and keep the value of key intact. Defaults to ‘“_hover”, so if the input key is “mask” the output will be “hover_mask”.allow_missing_keys (
bool) – do not raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
IO (Dict)#
LoadImaged#
- class monai.transforms.LoadImaged(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.LoadImage, It can load both image data and metadata. When loading a list of files in one key, the arrays will be stacked and a new dimension will be added as the first dimension In this case, the metadata of the first image will be used to represent the stacked result. The affine transform of all the stacked images should be same. The output metadata field will be created asmeta_keysorkey_{meta_key_postfix}.If reader is not specified, this class automatically chooses readers based on the supported suffixes and in the following order:
User-specified reader at runtime when calling this loader.
User-specified reader in the constructor of LoadImage.
Readers from the last to the first in the registered list.
Current default readers: (nii, nii.gz -> NibabelReader), (png, jpg, bmp -> PILReader), (npz, npy -> NumpyReader), (dcm, DICOM series and others -> ITKReader).
Please note that for png, jpg, bmp, and other 2D formats, readers by default swap axis 0 and 1 after loading the array with
reverse_indexingset toTruebecause the spatial axes definition for non-medical specific file formats is different from other common medical packages.Note
If reader is specified, the loader will attempt to use the specified readers and the default supported readers. This might introduce overheads when handling the exceptions of trying the incompatible loaders. In this case, it is therefore recommended setting the most appropriate reader as the last item of the reader parameter.
See also
tutorial: Project-MONAI/tutorials
- __call__(data, reader=None)[source]#
- Raises:
KeyError – When not
self.overwritingand key already exists indata.
- __init__(keys, reader=None, dtype=<class 'numpy.float32'>, meta_keys=None, meta_key_postfix='meta_dict', overwriting=False, image_only=True, ensure_channel_first=False, simple_keys=False, prune_meta_pattern=None, prune_meta_sep='.', allow_missing_keys=False, expanduser=True, *args, **kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformreader – reader to load image file and metadata - if reader is None, a default set of SUPPORTED_READERS will be used. - if reader is a string, it’s treated as a class name or dotted path (such as
"monai.data.ITKReader"), the supported built-in reader classes are"ITKReader","NibabelReader","NumpyReader". a reader instance will be constructed with the *args and **kwargs parameters. - if reader is a reader class/instance, it will be registered to this loader accordingly.dtype – if not None, convert the loaded image data to this data type.
meta_keys – explicitly indicate the key to store the corresponding metadata dictionary. the metadata is a dictionary object which contains: filename, original_shape, etc. it can be a sequence of string, map to the keys. if None, will try to construct meta_keys by key_{meta_key_postfix}.
meta_key_postfix – if meta_keys is None, use key_{postfix} to store the metadata of the nifti image, default is meta_dict. The metadata is a dictionary object. For example, load nifti file for image, store the metadata into image_meta_dict.
overwriting – whether allow overwriting existing metadata of same key. default is False, which will raise exception if encountering existing key.
image_only – if True return dictionary containing just only the image volumes, otherwise return dictionary containing image data array and header dict per input key.
ensure_channel_first – if True and loaded both image array and metadata, automatically convert the image array shape to channel first. default to False.
simple_keys – whether to remove redundant metadata keys, default to False for backward compatibility.
prune_meta_pattern – combined with prune_meta_sep, a regular expression used to match and prune keys in the metadata (nested dictionary), default to None, no key deletion.
prune_meta_sep – combined with prune_meta_pattern, used to match and prune keys in the metadata (nested dictionary). default is “.”, see also
monai.transforms.DeleteItemsd. e.g.prune_meta_pattern=".*_code$", prune_meta_sep=" "removes meta keys that ends with"_code".allow_missing_keys – don’t raise exception if key is missing.
expanduser – if True cast filename to Path and call .expanduser on it, otherwise keep filename as is.
args – additional parameters for reader if providing a reader name.
kwargs – additional parameters for reader if providing a reader name.
SaveImaged#
- class monai.transforms.SaveImaged(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.SaveImage.Note
Image should be channel-first shape: [C,H,W,[D]]. If the data is a patch of an image, the patch index will be appended to the filename.
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformmeta_keys – explicitly indicate the key of the corresponding metadata dictionary. For example, for data with key
image, the metadata by default is inimage_meta_dict. The metadata is a dictionary contains values such asfilename,original_shape. This argument can be a sequence of strings, mapped to thekeys. IfNone, will try to constructmeta_keysbykey_{meta_key_postfix}.meta_key_postfix – if
meta_keysisNone, usekey_{meta_key_postfix}to retrieve the metadict.output_dir – output image directory. Handled by
folder_layoutinstead, iffolder_layoutis notNone.output_postfix – a string appended to all output file names, default to
trans. Handled byfolder_layoutinstead, iffolder_layoutis notNone.output_ext – output file extension name, available extensions:
.nii.gz,.nii,.png,.dcm. Handled byfolder_layoutinstead, iffolder_layoutnotNone.resample – whether to resample image (if needed) before saving the data array, based on the
spatial_shape(andoriginal_affine) from metadata.mode –
This option is used when
resample=True. Defaults to"nearest". Depending on the writers, the possible options are:{
"bilinear","nearest","bicubic"}. See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample{
"nearest","linear","bilinear","bicubic","trilinear","area"}. See also: https://pytorch.org/docs/stable/nn.functional.html#interpolate
padding_mode – This option is used when
resample = True. Defaults to"border". Possible options are {"zeros","border","reflection"} See also: https://pytorch.org/docs/stable/nn.functional.html#grid-samplescale – {
255,65535} postprocess data by clipping to [0, 1] and scaling [0, 255] (uint8) or [0, 65535] (uint16). Default isNone(no scaling).dtype – data type during resampling computation. Defaults to
np.float64for best precision. if None, use the data type of input data. To set the output data type, useoutput_dtype.output_dtype – data type for saving data. Defaults to
np.float32.allow_missing_keys – don’t raise exception if key is missing.
squeeze_end_dims – if True, any trailing singleton dimensions will be removed (after the channel has been moved to the end). So if input is (C,H,W,D), this will be altered to (H,W,D,C), and then if C==1, it will be saved as (H,W,D). If D is also 1, it will be saved as (H,W). If false, image will always be saved as (H,W,D,C).
data_root_dir –
if not empty, it specifies the beginning parts of the input file’s absolute path. It’s used to compute
input_file_rel_path, the relative path to the file fromdata_root_dirto preserve folder structure when saving in case there are files in different folders with the same file names. For example, with the following inputs:input_file_name:
/foo/bar/test1/image.niioutput_postfix:
segoutput_ext:
.nii.gzoutput_dir:
/outputdata_root_dir:
/foo/bar
The output will be:
/output/test1/image/image_seg.nii.gzHandled by
folder_layoutinstead, iffolder_layoutis notNone.separate_folder – whether to save every file in a separate folder. For example: for the input filename
image.nii, postfixsegand folder_pathoutput, ifseparate_folder=True, it will be saved as:output/image/image_seg.nii, ifFalse, saving asoutput/image_seg.nii. Default toTrue. Handled byfolder_layoutinstead, iffolder_layoutis notNone.print_log – whether to print logs when saving. Default to
True.output_format – an optional string to specify the output image writer. see also:
monai.data.image_writer.SUPPORTED_WRITERS.writer – a customised
monai.data.ImageWritersubclass to save data arrays. ifNone, use the default writer frommonai.data.image_writeraccording tooutput_ext. if it’s a string, it’s treated as a class name or dotted path; the supported built-in writer classes are"NibabelWriter","ITKWriter","PILWriter".output_name_formatter – a callable function (returning a kwargs dict) to format the output file name. see also:
monai.data.folder_layout.default_name_formatter(). If using a customfolder_layout, consider providing your own formatter.folder_layout – A customized
monai.data.FolderLayoutBasesubclass to define file naming schemes. ifNone, uses the defaultFolderLayout.savepath_in_metadict – if
True, adds a keysaved_toto the metadata, which contains the path to where the input image has been saved.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
Post-processing (Dict)#
Activationsd#
- class monai.transforms.Activationsd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.AddActivations. Add activation layers to the input data specified by keys.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, sigmoid=False, softmax=False, other=None, allow_missing_keys=False, **kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to model output and label. See also:
monai.transforms.compose.MapTransformsigmoid – whether to execute sigmoid function on model output before transform. it also can be a sequence of bool, each element corresponds to a key in
keys.softmax – whether to execute softmax function on model output before transform. it also can be a sequence of bool, each element corresponds to a key in
keys.other – callable function to execute other activation layers, for example: other = torch.tanh. it also can be a sequence of Callable, each element corresponds to a key in
keys.allow_missing_keys – don’t raise exception if key is missing.
kwargs – additional parameters to torch.softmax (used when
softmax=True). Defaults todim=0, unrecognized parameters will be ignored.
AsDiscreted#
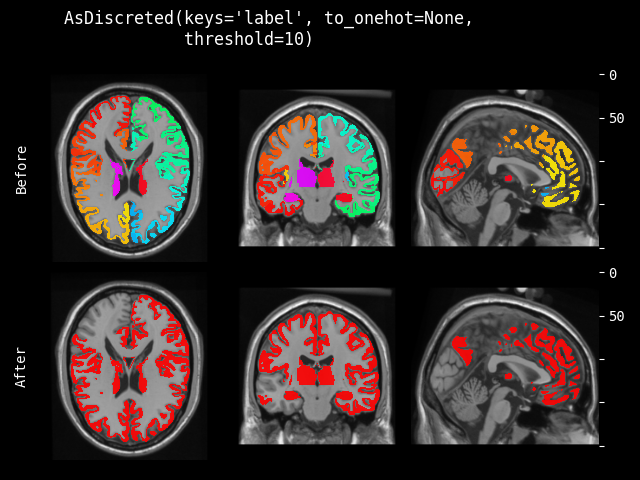
- class monai.transforms.AsDiscreted(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.AsDiscrete.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, argmax=False, to_onehot=None, threshold=None, rounding=None, allow_missing_keys=False, **kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to model output and label. See also:
monai.transforms.compose.MapTransformargmax – whether to execute argmax function on input data before transform. it also can be a sequence of bool, each element corresponds to a key in
keys.to_onehot – if not None, convert input data into the one-hot format with specified number of classes. defaults to
None. it also can be a sequence, each element corresponds to a key inkeys.threshold – if not None, threshold the float values to int number 0 or 1 with specified threshold value. defaults to
None. it also can be a sequence, each element corresponds to a key inkeys.rounding – if not None, round the data according to the specified option, available options: [“torchrounding”]. it also can be a sequence of str or None, each element corresponds to a key in
keys.allow_missing_keys – don’t raise exception if key is missing.
kwargs – additional parameters to
AsDiscrete.dim,keepdim,dtypeare supported, unrecognized parameters will be ignored. These default to0,True,torch.floatrespectively.
KeepLargestConnectedComponentd#
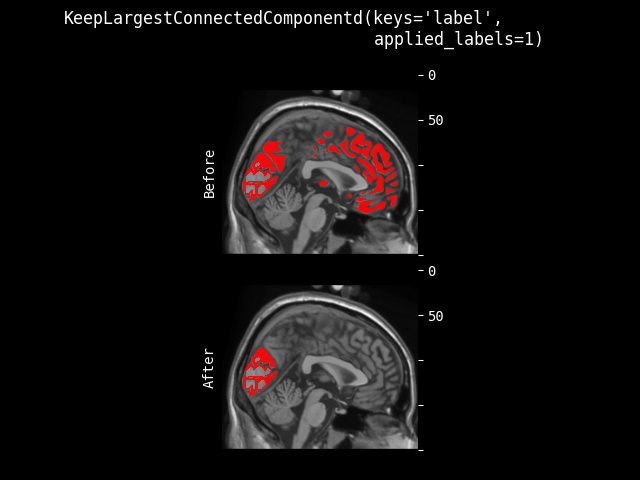
- class monai.transforms.KeepLargestConnectedComponentd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.KeepLargestConnectedComponent.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, applied_labels=None, is_onehot=None, independent=True, connectivity=None, num_components=1, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformapplied_labels – Labels for applying the connected component analysis on. If given, voxels whose value is in this list will be analyzed. If None, all non-zero values will be analyzed.
is_onehot – if True, treat the input data as OneHot format data, otherwise, not OneHot format data. default to None, which treats multi-channel data as OneHot and single channel data as not OneHot.
independent – whether to treat
applied_labelsas a union of foreground labels. IfTrue, the connected component analysis will be performed on each foreground label independently and return the intersection of the largest components. IfFalse, the analysis will be performed on the union of foreground labels. default is True.connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. If
None, a full connectivity ofinput.ndimis used. for more details: https://scikit-image.org/docs/dev/api/skimage.measure.html#skimage.measure.label.num_components – The number of largest components to preserve.
allow_missing_keys – don’t raise exception if key is missing.
DistanceTransformEDTd#
- class monai.transforms.DistanceTransformEDTd(*args, **kwargs)[source]#
Applies the Euclidean distance transform on the input. Either GPU based with CuPy / cuCIM or CPU based with scipy. To use the GPU implementation, make sure cuCIM is available and that the data is a torch.tensor on a GPU device.
Note that the results of the libraries can differ, so stick to one if possible. For details, check out the SciPy and cuCIM documentation and / or
monai.transforms.utils.distance_transform_edt().- Note on the input shape:
Has to be a channel first array, must have shape: (num_channels, H, W [,D]). Can be of any type but will be converted into binary: 1 wherever image equates to True, 0 elsewhere. Input gets passed channel-wise to the distance-transform, thus results from this function will differ from directly calling
distance_transform_edt()in CuPy or SciPy.
- Parameters:
keys – keys of the corresponding items to be transformed.
allow_missing_keys – don’t raise exception if key is missing.
sampling – Spacing of elements along each dimension. If a sequence, must be of length equal to the input rank -1; if a single number, this is used for all axes. If not specified, a grid spacing of unity is implied.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Mapping[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
RemoveSmallObjectsd#

- class monai.transforms.RemoveSmallObjectsd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.RemoveSmallObjectsd.- Parameters:
min_size – objects smaller than this size (in number of voxels; or surface area/volume value in whatever units your image is if by_measure is True) are removed.
connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. If
None, a full connectivity ofinput.ndimis used. For more details refer to linked scikit-image documentation.independent_channels – Whether or not to consider channels as independent. If true, then conjoining islands from different labels will be removed if they are below the threshold. If false, the overall size islands made from all non-background voxels will be used.
by_measure – Whether the specified min_size is in number of voxels. if this is True then min_size represents a surface area or volume value of whatever units your image is in (mm^3, cm^2, etc.) default is False. e.g. if min_size is 3, by_measure is True and the units of your data is mm, objects smaller than 3mm^3 are removed.
pixdim – the pixdim of the input image. if a single number, this is used for all axes. If a sequence of numbers, the length of the sequence must be equal to the image dimensions.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
LabelFilterd#
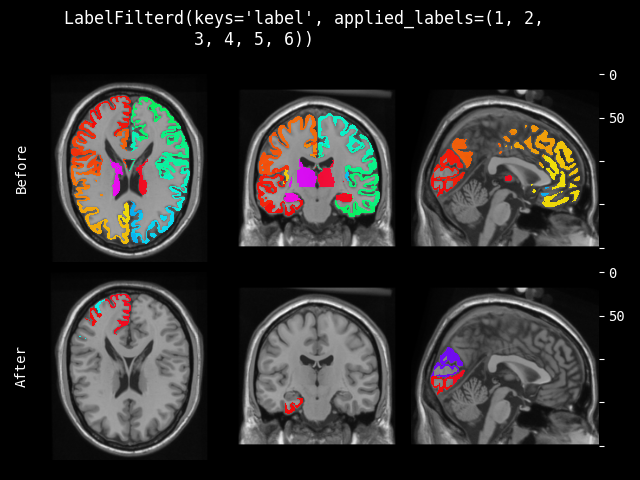
- class monai.transforms.LabelFilterd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.LabelFilter.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
FillHolesd#
- class monai.transforms.FillHolesd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.FillHoles.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, applied_labels=None, connectivity=None, allow_missing_keys=False)[source]#
Initialize the connectivity and limit the labels for which holes are filled.
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformapplied_labels (Optional[Union[Iterable[int], int]], optional) – Labels for which to fill holes. Defaults to None, that is filling holes for all labels.
connectivity (int, optional) – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. Defaults to a full connectivity of
input.ndim.allow_missing_keys – don’t raise exception if key is missing.
LabelToContourd#
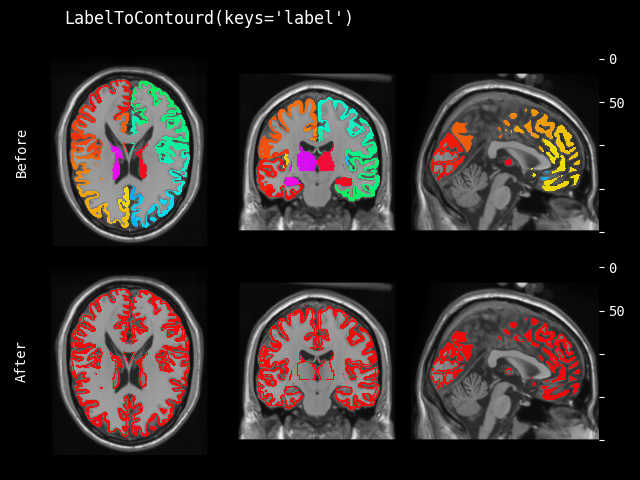
- class monai.transforms.LabelToContourd(keys, kernel_type='Laplace', allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.LabelToContour.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, kernel_type='Laplace', allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformkernel_type (
str) – the method applied to do edge detection, default is “Laplace”.allow_missing_keys (
bool) – don’t raise exception if key is missing.
Ensembled#
- class monai.transforms.Ensembled(*args, **kwargs)[source]#
Base class of dictionary-based ensemble transforms.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, ensemble, output_key=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be stack and execute ensemble. if only 1 key provided, suppose it’s a PyTorch Tensor with data stacked on dimension E.
output_key – the key to store ensemble result in the dictionary.
ensemble – callable method to execute ensemble on specified data. if only 1 key provided in keys, output_key can be None and use keys as default.
allow_missing_keys – don’t raise exception if key is missing.
- Raises:
TypeError – When
ensembleis notcallable.ValueError – When
len(keys) > 1andoutput_key=None. Incompatible values.
MeanEnsembled#
- class monai.transforms.MeanEnsembled(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.MeanEnsemble.- __init__(keys, output_key=None, weights=None)[source]#
- Parameters:
keys – keys of the corresponding items to be stack and execute ensemble. if only 1 key provided, suppose it’s a PyTorch Tensor with data stacked on dimension E.
output_key – the key to store ensemble result in the dictionary. if only 1 key provided in keys, output_key can be None and use keys as default.
weights – can be a list or tuple of numbers for input data with shape: [E, C, H, W[, D]]. or a Numpy ndarray or a PyTorch Tensor data. the weights will be added to input data from highest dimension, for example: 1. if the weights only has 1 dimension, it will be added to the E dimension of input data. 2. if the weights has 2 dimensions, it will be added to E and C dimensions. it’s a typical practice to add weights for different classes: to ensemble 3 segmentation model outputs, every output has 4 channels(classes), so the input data shape can be: [3, 4, H, W, D]. and add different weights for different classes, so the weights shape can be: [3, 4]. for example: weights = [[1, 2, 3, 4], [4, 3, 2, 1], [1, 1, 1, 1]].
VoteEnsembled#
- class monai.transforms.VoteEnsembled(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.VoteEnsemble.- __init__(keys, output_key=None, num_classes=None)[source]#
- Parameters:
keys – keys of the corresponding items to be stack and execute ensemble. if only 1 key provided, suppose it’s a PyTorch Tensor with data stacked on dimension E.
output_key – the key to store ensemble result in the dictionary. if only 1 key provided in keys, output_key can be None and use keys as default.
num_classes – if the input is single channel data instead of One-Hot, we can’t get class number from channel, need to explicitly specify the number of classes to vote.
Invertd#
- class monai.transforms.Invertd(*args, **kwargs)[source]#
Utility transform to invert the previously applied transforms.
Taking the
transformpreviously applied onorig_keys, thisInvertdwill apply the inverse of it to the data stored atkeys.Invertd’s output will also include a copy of the metadata dictionary (originally fromorig_meta_keysor the metadata oforig_keys), with the relevant fields inverted and stored atmeta_keys.A typical usage is to apply the inverse of the preprocessing (
transform=preprocessings) on inputorig_keys=imageto the model predictionskeys=pred.A detailed usage example is available in the tutorial: Project-MONAI/tutorials
Note
The output of the inverted data and metadata will be stored at
keysandmeta_keysrespectively.To correctly invert the transforms, the information of the previously applied transforms should be available at
{orig_keys}_transforms, and the original metadata atorig_meta_keys. (meta_key_postfixis an optional string to conveniently construct “meta_keys” and/or “orig_meta_keys”.) see also:monai.transforms.TraceableTransform.The transform will not change the content in
orig_keysandorig_meta_key. These keys are only used to represent the data status ofkeybefore inverting.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Any]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, transform, orig_keys=None, meta_keys=None, orig_meta_keys=None, meta_key_postfix='meta_dict', nearest_interp=True, to_tensor=True, device=None, post_func=None, allow_missing_keys=False)[source]#
- Parameters:
keys – the key of expected data in the dict, the inverse of
transformswill be applied on it in-place. It also can be a list of keys, will apply the inverse transform respectively.transform – the transform applied to
orig_key, its inverse will be applied onkey.orig_keys – the key of the original input data in the dict. These keys default to self.keys if not set. the transform trace information of
transformsshould be stored at{orig_keys}_transforms. It can also be a list of keys, each matches thekeys.meta_keys – The key to output the inverted metadata dictionary. The metadata is a dictionary optionally containing: filename, original_shape. It can be a sequence of strings, maps to
keys. If None, will try to create a metadata dict with the default key: {key}_{meta_key_postfix}.orig_meta_keys – the key of the metadata of original input data. The metadata is a dictionary optionally containing: filename, original_shape. It can be a sequence of strings, maps to the keys. If None, will try to create a metadata dict with the default key: {orig_key}_{meta_key_postfix}. This metadata dict will also be included in the inverted dict, stored in meta_keys.
meta_key_postfix – if orig_meta_keys is None, use {orig_key}_{meta_key_postfix} to fetch the metadata from dict, if meta_keys is None, use {key}_{meta_key_postfix}. Default:
"meta_dict".nearest_interp – whether to use nearest interpolation mode when inverting the spatial transforms, default to True. If False, use the same interpolation mode as the original transform. It also can be a list of bool, each matches to the keys data.
to_tensor – whether to convert the inverted data into PyTorch Tensor first, default to True. It also can be a list of bool, each matches to the keys data.
device – if converted to Tensor, move the inverted results to target device before post_func, default to None, it also can be a list of string or torch.device, each matches to the keys data.
post_func – post processing for the inverted data, should be a callable function. It also can be a list of callable, each matches to the keys data.
allow_missing_keys – don’t raise exception if key is missing.
SaveClassificationd#
- class monai.transforms.SaveClassificationd(*args, **kwargs)[source]#
Save the classification results and metadata into CSV file or other storage.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, meta_keys=None, meta_key_postfix='meta_dict', saver=None, output_dir='./', filename='predictions.csv', delimiter=',', overwrite=True, flush=True, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to model output, this transform only supports 1 key. See also:
monai.transforms.compose.MapTransformmeta_keys – explicitly indicate the key of the corresponding metadata dictionary. for example, for data with key image, the metadata by default is in image_meta_dict. the metadata is a dictionary object which contains: filename, original_shape, etc. it can be a sequence of string, map to the keys. if None, will try to construct meta_keys by key_{meta_key_postfix}. will extract the filename of input image to save classification results.
meta_key_postfix – key_{postfix} was used to store the metadata in LoadImaged. so need the key to extract the metadata of input image, like filename, etc. default is meta_dict. for example, for data with key image, the metadata by default is in image_meta_dict. the metadata is a dictionary object which contains: filename, original_shape, etc. this arg only works when meta_keys=None. if no corresponding metadata, set to None.
saver – the saver instance to save classification results, if None, create a CSVSaver internally. the saver must provide save(data, meta_data) and finalize() APIs.
output_dir – if saver=None, specify the directory to save the CSV file.
filename – if saver=None, specify the name of the saved CSV file.
delimiter – the delimiter character in the saved file, default to “,” as the default output type is csv. to be consistent with: https://docs.python.org/3/library/csv.html#csv.Dialect.delimiter.
overwrite – if saver=None, indicate whether to overwriting existing CSV file content, if True, will clear the file before saving. otherwise, will append new content to the CSV file.
flush – if saver=None, indicate whether to write the cache data to CSV file immediately in this transform and clear the cache. default to True. If False, may need user to call saver.finalize() manually or use ClassificationSaver handler.
allow_missing_keys – don’t raise exception if key is missing.
ProbNMSd#
- class monai.transforms.ProbNMSd(*args, **kwargs)[source]#
Performs probability based non-maximum suppression (NMS) on the probabilities map via iteratively selecting the coordinate with highest probability and then move it as well as its surrounding values. The remove range is determined by the parameter box_size. If multiple coordinates have the same highest probability, only one of them will be selected.
- Parameters:
spatial_dims – number of spatial dimensions of the input probabilities map. Defaults to 2.
sigma – the standard deviation for gaussian filter. It could be a single value, or spatial_dims number of values. Defaults to 0.0.
prob_threshold – the probability threshold, the function will stop searching if the highest probability is no larger than the threshold. The value should be no less than 0.0. Defaults to 0.5.
box_size – the box size (in pixel) to be removed around the pixel with the maximum probability. It can be an integer that defines the size of a square or cube, or a list containing different values for each dimensions. Defaults to 48.
- Returns:
a list of selected lists, where inner lists contain probability and coordinates. For example, for 3D input, the inner lists are in the form of [probability, x, y, z].
- Raises:
ValueError – When
prob_thresholdis less than 0.0.ValueError – When
box_sizeis a list or tuple, and its length is not equal to spatial_dims.ValueError – When
box_sizehas a less than 1 value.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
SobelGradientsd#
- class monai.transforms.SobelGradientsd(*args, **kwargs)[source]#
Calculate Sobel horizontal and vertical gradients of a grayscale image.
- Parameters:
keys – keys of the corresponding items to model output.
kernel_size – the size of the Sobel kernel. Defaults to 3.
spatial_axes – the axes that define the direction of the gradient to be calculated. It calculate the gradient along each of the provide axis. By default it calculate the gradient for all spatial axes.
normalize_kernels – if normalize the Sobel kernel to provide proper gradients. Defaults to True.
normalize_gradients – if normalize the output gradient to 0 and 1. Defaults to False.
padding_mode – the padding mode of the image when convolving with Sobel kernels. Defaults to “reflect”. Acceptable values are
'zeros','reflect','replicate'or'circular'. Seetorch.nn.Conv1d()for more information.dtype – kernel data type (torch.dtype). Defaults to torch.float32.
new_key_prefix – this prefix be prepended to the key to create a new key for the output and keep the value of key intact. By default not prefix is set and the corresponding array to the key will be replaced.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
Regularization (Dict)#
CutMixd#
- class monai.transforms.CutMixd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.CutMix.Notice that the mixture weights will be the same for all entries for consistency, i.e. images and labels must be aggregated with the same weights, but the random crops are not.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
CutOutd#
- class monai.transforms.CutOutd(keys, batch_size, allow_missing_keys=False)[source]#
Dictionary-based version
monai.transforms.CutOut.Notice that the cutout is different for every entry in the dictionary.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
MixUpd#
- class monai.transforms.MixUpd(keys, batch_size, alpha=1.0, allow_missing_keys=False)[source]#
Dictionary-based version
monai.transforms.MixUp.Notice that the mixup transformation will be the same for all entries for consistency, i.e. images and labels must be applied the same augmenation.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
Signal (Dict)#
SignalFillEmptyd#
- class monai.transforms.SignalFillEmptyd(keys=None, allow_missing_keys=False, replacement=0.0)[source]#
Applies the SignalFillEmptyd transform on the input. All NaN values will be replaced with the replacement value.
- Parameters:
keys (
Union[Collection[Hashable],Hashable,None]) – keys of the corresponding items to model output.allow_missing_keys (
bool) – don’t raise exception if key is missing.replacement – The value that the NaN entries shall be mapped to.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Mapping[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
Spatial (Dict)#
SpatialResampled#
- class monai.transforms.SpatialResampled(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.SpatialResample.This transform assumes the
datadictionary has a key for the input data’s metadata and containssrc_affineanddst_affinerequired by SpatialResample. The key is formed bykey_{meta_key_postfix}. The transform will swapsrc_affineanddst_affineaffine (with potential data type changes) in the dictionary so thatsrc_affinealways refers to the current status of affine.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
See also
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, dst_keys='dst_affine', allow_missing_keys=False, lazy=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.align_corners – Geometrically, we consider the pixels of the input as squares rather than points. See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample It also can be a sequence of bool, each element corresponds to a key in
keys.dtype – data type for resampling computation. Defaults to
float64for best precision. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32. It also can be a sequence of dtypes, each element corresponds to a key inkeys.dst_keys – the key of the corresponding
dst_affinein the metadata dictionary.allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
ResampleToMatchd#
- class monai.transforms.ResampleToMatchd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ResampleToMatch.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, key_dst, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, allow_missing_keys=False, lazy=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
key_dst – key of image to resample to match.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.align_corners – Geometrically, we consider the pixels of the input as squares rather than points. See also: https://pytorch.org/docs/stable/nn.functional.html#grid-sample It also can be a sequence of bool, each element corresponds to a key in
keys.dtype – data type for resampling computation. Defaults to
float64for best precision. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32. It also can be a sequence of dtypes, each element corresponds to a key inkeys.allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
Spacingd#
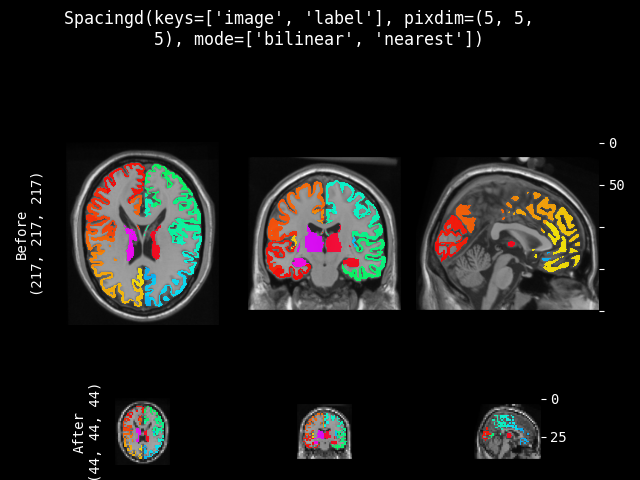
- class monai.transforms.Spacingd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Spacing.This transform assumes the
datadictionary has a key for the input data’s metadata and contains affine field. The key is formed bykey_{meta_key_postfix}.After resampling the input array, this transform will write the new affine to the affine field of metadata which is formed by
key_{meta_key_postfix}.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
See also
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, pixdim, diagonal=False, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, scale_extent=False, recompute_affine=False, min_pixdim=None, max_pixdim=None, ensure_same_shape=True, allow_missing_keys=False, lazy=False)[source]#
- Parameters:
pixdim – output voxel spacing. if providing a single number, will use it for the first dimension. items of the pixdim sequence map to the spatial dimensions of input image, if length of pixdim sequence is longer than image spatial dimensions, will ignore the longer part, if shorter, will pad with 1.0. if the components of the pixdim are non-positive values, the transform will use the corresponding components of the original pixdim, which is computed from the affine matrix of input image.
diagonal –
whether to resample the input to have a diagonal affine matrix. If True, the input data is resampled to the following affine:
np.diag((pixdim_0, pixdim_1, pixdim_2, 1))
This effectively resets the volume to the world coordinate system (RAS+ in nibabel). The original orientation, rotation, shearing are not preserved.
If False, the axes orientation, orthogonal rotation and translations components from the original affine will be preserved in the target affine. This option will not flip/swap axes against the original ones.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.align_corners – Geometrically, we consider the pixels of the input as squares rather than points. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html It also can be a sequence of bool, each element corresponds to a key in
keys.dtype – data type for resampling computation. Defaults to
float64for best precision. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32. It also can be a sequence of dtypes, each element corresponds to a key inkeys.scale_extent – whether the scale is computed based on the spacing or the full extent of voxels, default False. The option is ignored if output spatial size is specified when calling this transform. See also:
monai.data.utils.compute_shape_offset(). When this is True, align_corners should be True because compute_shape_offset already provides the corner alignment shift/scaling.recompute_affine – whether to recompute affine based on the output shape. The affine computed analytically does not reflect the potential quantization errors in terms of the output shape. Set this flag to True to recompute the output affine based on the actual pixdim. Default to
False.min_pixdim – minimal input spacing to be resampled. If provided, input image with a larger spacing than this value will be kept in its original spacing (not be resampled to pixdim). Set it to None to use the value of pixdim. Default to None.
max_pixdim – maximal input spacing to be resampled. If provided, input image with a smaller spacing than this value will be kept in its original spacing (not be resampled to pixdim). Set it to None to use the value of pixdim. Default to None.
ensure_same_shape – when the inputs have the same spatial shape, and almost the same pixdim, whether to ensure exactly the same output spatial shape. Default to True.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
Orientationd#
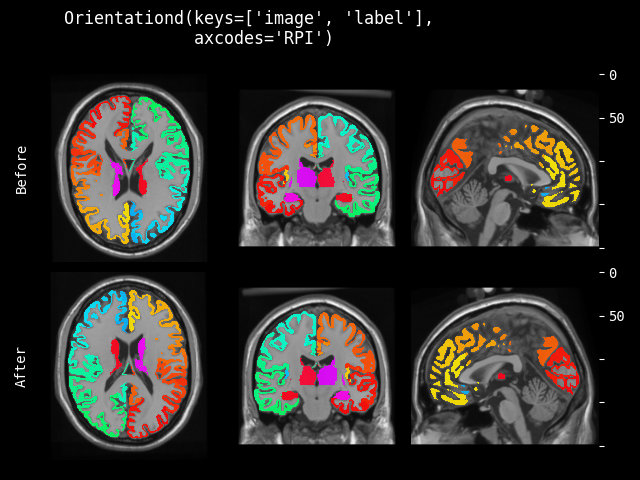
- class monai.transforms.Orientationd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Orientation.This transform assumes the channel-first input format. In the case of using this transform for normalizing the orientations of images, it should be used before any anisotropic spatial transforms.
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, axcodes=None, as_closest_canonical=False, labels=(('L', 'R'), ('P', 'A'), ('I', 'S')), allow_missing_keys=False, lazy=False)[source]#
- Parameters:
axcodes – N elements sequence for spatial ND input’s orientation. e.g. axcodes=’RAS’ represents 3D orientation: (Left, Right), (Posterior, Anterior), (Inferior, Superior). default orientation labels options are: ‘L’ and ‘R’ for the first dimension, ‘P’ and ‘A’ for the second, ‘I’ and ‘S’ for the third.
as_closest_canonical – if True, load the image as closest to canonical axis format.
labels – optional, None or sequence of (2,) sequences (2,) sequences are labels for (beginning, end) of output axis. Defaults to
(('L', 'R'), ('P', 'A'), ('I', 'S')).allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
See also
nibabel.orientations.ornt2axcodes.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
Flipd#
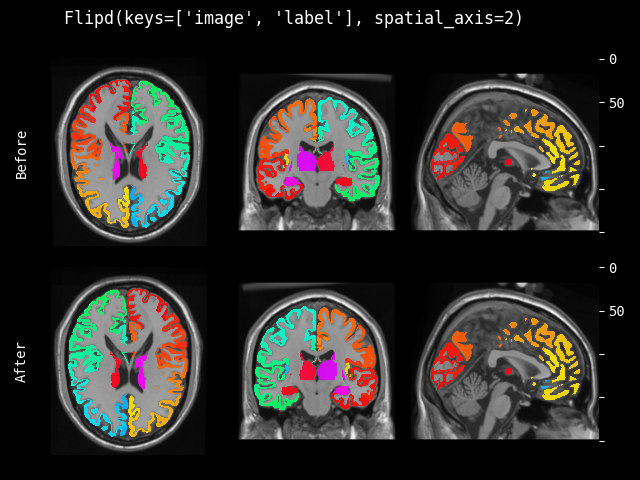
- class monai.transforms.Flipd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Flip.See numpy.flip for additional details. https://docs.scipy.org/doc/numpy/reference/generated/numpy.flip.html
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – Keys to pick data for transformation.
spatial_axis – Spatial axes along which to flip over. Default is None.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
RandFlipd#
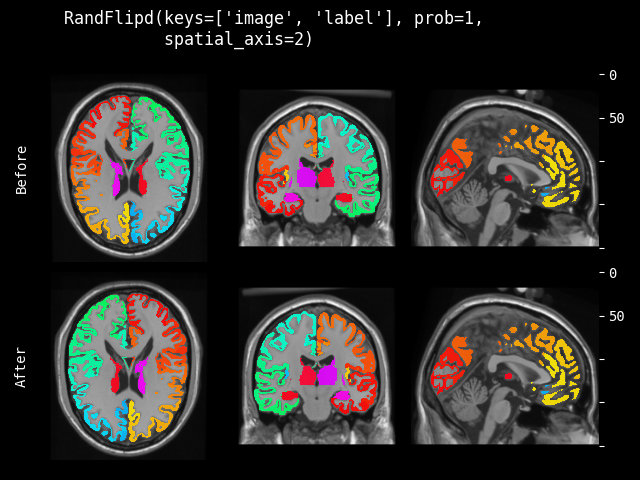
- class monai.transforms.RandFlipd(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandFlip.See numpy.flip for additional details. https://docs.scipy.org/doc/numpy/reference/generated/numpy.flip.html
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – Keys to pick data for transformation.
prob – Probability of flipping.
spatial_axis – Spatial axes along which to flip over. Default is None.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandAxisFlipd#
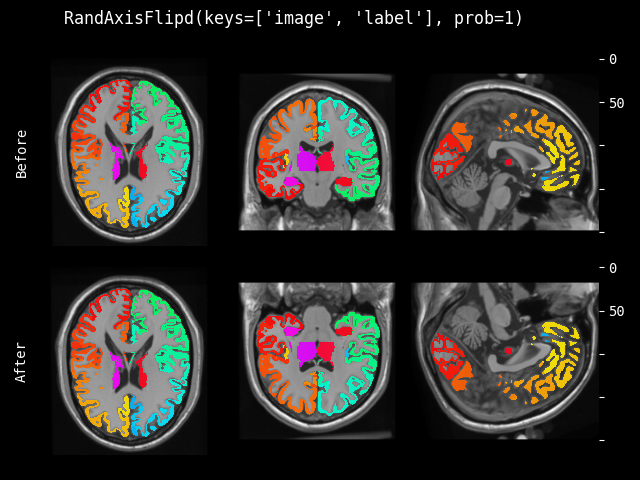
- class monai.transforms.RandAxisFlipd(keys, prob=0.1, allow_missing_keys=False, lazy=False)[source]#
Dictionary-based version
monai.transforms.RandAxisFlip.See numpy.flip for additional details. https://docs.scipy.org/doc/numpy/reference/generated/numpy.flip.html
This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – Keys to pick data for transformation.prob (
float) – Probability of flipping.allow_missing_keys (
bool) – don’t raise exception if key is missing.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
Rotated#
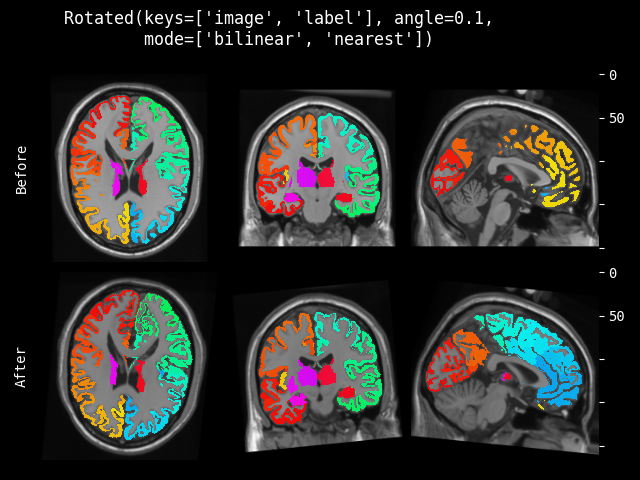
- class monai.transforms.Rotated(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Rotate.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – Keys to pick data for transformation.
angle – Rotation angle(s) in radians.
keep_size – If it is False, the output shape is adapted so that the input array is contained completely in the output. If it is True, the output shape is the same as the input. Default is True.
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html It also can be a sequence of string, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html It also can be a sequence of string, each element corresponds to a key inkeys.align_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html It also can be a sequence of bool, each element corresponds to a key in
keys.dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32. It also can be a sequence of dtype or None, each element corresponds to a key inkeys.allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
RandRotated#
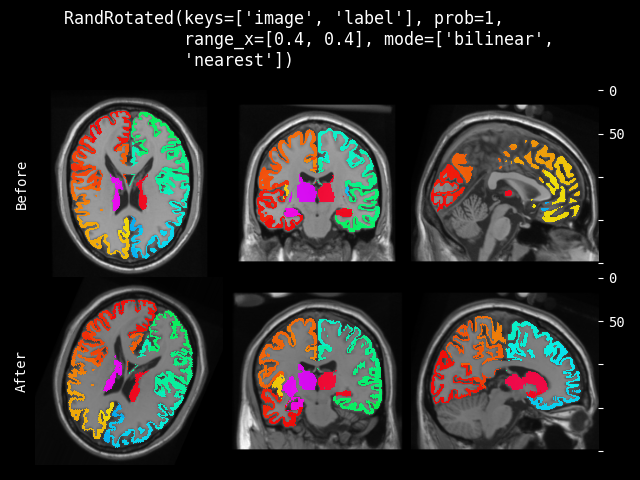
- class monai.transforms.RandRotated(*args, **kwargs)[source]#
Dictionary-based version
monai.transforms.RandRotateRandomly rotates the input arrays.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – Keys to pick data for transformation.
range_x – Range of rotation angle in radians in the plane defined by the first and second axes. If single number, angle is uniformly sampled from (-range_x, range_x).
range_y – Range of rotation angle in radians in the plane defined by the first and third axes. If single number, angle is uniformly sampled from (-range_y, range_y). only work for 3D data.
range_z – Range of rotation angle in radians in the plane defined by the second and third axes. If single number, angle is uniformly sampled from (-range_z, range_z). only work for 3D data.
prob – Probability of rotation.
keep_size – If it is False, the output shape is adapted so that the input array is contained completely in the output. If it is True, the output shape is the same as the input. Default is True.
mode – {
"bilinear","nearest"} Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html It also can be a sequence of string, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html It also can be a sequence of string, each element corresponds to a key inkeys.align_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html It also can be a sequence of bool, each element corresponds to a key in
keys.dtype – data type for resampling computation. Defaults to
float64for best precision. If None, use the data type of input data. To be compatible with other modules, the output data type is alwaysfloat32. It also can be a sequence of dtype or None, each element corresponds to a key inkeys.allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
Zoomd#
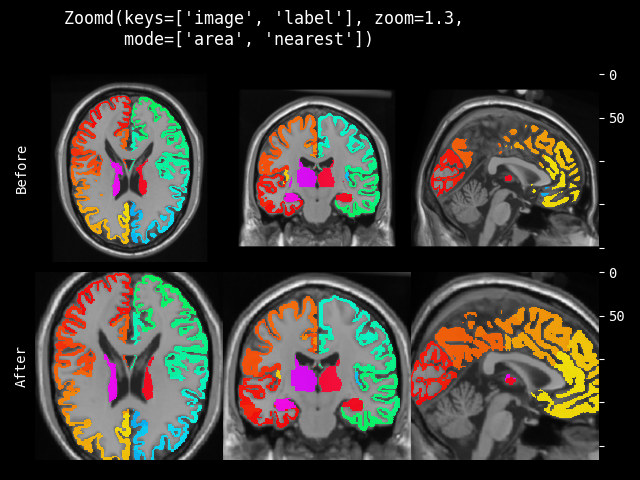
- class monai.transforms.Zoomd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Zoom.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – Keys to pick data for transformation.
zoom – The zoom factor along the spatial axes. If a float, zoom is the same for each spatial axis. If a sequence, zoom should contain one value for each spatial axis.
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults to"area". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html It also can be a sequence of string, each element corresponds to a key inkeys.padding_mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"edge". The mode to pad data after zooming. See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: None. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html It also can be a sequence of bool or None, each element corresponds to a key in
keys.dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data.keep_size – Should keep original size (pad if needed), default is True.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
RandZoomd#
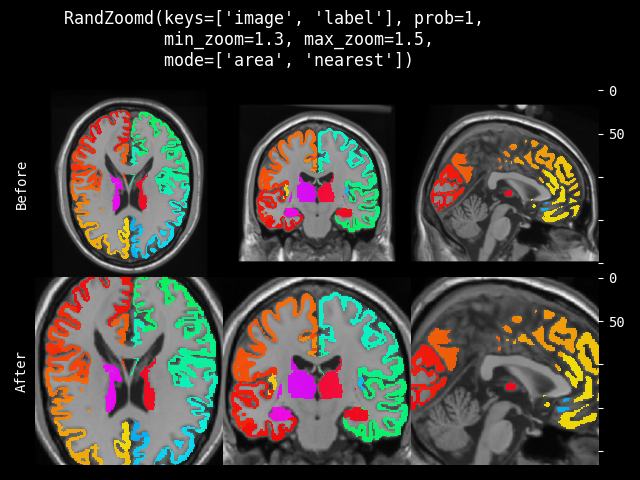
- class monai.transforms.RandZoomd(*args, **kwargs)[source]#
Dict-based version
monai.transforms.RandZoom.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – Keys to pick data for transformation.
prob – Probability of zooming.
min_zoom – Min zoom factor. Can be float or sequence same size as image. If a float, select a random factor from [min_zoom, max_zoom] then apply to all spatial dims to keep the original spatial shape ratio. If a sequence, min_zoom should contain one value for each spatial axis. If 2 values provided for 3D data, use the first value for both H & W dims to keep the same zoom ratio.
max_zoom – Max zoom factor. Can be float or sequence same size as image. If a float, select a random factor from [min_zoom, max_zoom] then apply to all spatial dims to keep the original spatial shape ratio. If a sequence, max_zoom should contain one value for each spatial axis. If 2 values provided for 3D data, use the first value for both H & W dims to keep the same zoom ratio.
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults to"area". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html It also can be a sequence of string, each element corresponds to a key inkeys.padding_mode – available modes for numpy array:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} available modes for PyTorch Tensor: {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to"edge". The mode to pad data after zooming. See also: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: None. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html It also can be a sequence of bool or None, each element corresponds to a key in
keys.dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data.keep_size – Should keep original size (pad if needed), default is True.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
kwargs – other args for np.pad API, note that np.pad treats channel dimension as the first dimension. more details: https://numpy.org/doc/1.18/reference/generated/numpy.pad.html
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
GridPatchd#
- class monai.transforms.GridPatchd(*args, **kwargs)[source]#
Extract all the patches sweeping the entire image in a row-major sliding-window manner with possible overlaps. It can sort the patches and return all or a subset of them.
- Parameters:
keys – keys of the corresponding items to be transformed.
patch_size – size of patches to generate slices for, 0 or None selects whole dimension
offset – starting position in the array, default is 0 for each dimension. np.random.randint(0, patch_size, 2) creates random start between 0 and patch_size for a 2D image.
num_patches – number of patches (or maximum number of patches) to return. If the requested number of patches is greater than the number of available patches, padding will be applied to provide exactly num_patches patches unless threshold is set. When threshold is set, this value is treated as the maximum number of patches. Defaults to None, which does not limit number of the patches.
overlap – amount of overlap between patches in each dimension. Default to 0.0.
sort_fn – when num_patches is provided, it determines if keep patches with highest values (“max”), lowest values (“min”), or in their default order (None). Default to None.
threshold – a value to keep only the patches whose sum of intensities are less than the threshold. Defaults to no filtering.
pad_mode – the mode for padding the input image by patch_size to include patches that cross boundaries. Available modes: (Numpy) {
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to None, which means no padding will be applied. See also: https://numpy.org/doc/stable/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html requires pytorch >= 1.10 for best compatibility.allow_missing_keys – don’t raise exception if key is missing.
pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- Returns:
- dictionary, contains the all the original key/value with the values for keys
replaced by the patches, a MetaTensor with following metadata:
PatchKeys.LOCATION: the starting location of the patch in the image,
PatchKeys.COUNT: total number of patches in the image,
”spatial_shape”: spatial size of the extracted patch, and
”offset”: the amount of offset for the patches in the image (starting position of the first patch)
- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – a dictionary containing the tensor-like data to be processed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
RandGridPatchd#
- class monai.transforms.RandGridPatchd(*args, **kwargs)[source]#
Extract all the patches sweeping the entire image in a row-major sliding-window manner with possible overlaps, and with random offset for the minimal corner of the image, (0,0) for 2D and (0,0,0) for 3D. It can sort the patches and return all or a subset of them.
- Parameters:
keys – keys of the corresponding items to be transformed.
patch_size – size of patches to generate slices for, 0 or None selects whole dimension
min_offset – the minimum range of starting position to be selected randomly. Defaults to 0.
max_offset – the maximum range of starting position to be selected randomly. Defaults to image size modulo patch size.
num_patches – number of patches (or maximum number of patches) to return. If the requested number of patches is greater than the number of available patches, padding will be applied to provide exactly num_patches patches unless threshold is set. When threshold is set, this value is treated as the maximum number of patches. Defaults to None, which does not limit number of the patches.
overlap – the amount of overlap of neighboring patches in each dimension (a value between 0.0 and 1.0). If only one float number is given, it will be applied to all dimensions. Defaults to 0.0.
sort_fn – when num_patches is provided, it determines if keep patches with highest values (“max”), lowest values (“min”), in random (“random”), or in their default order (None). Default to None.
threshold – a value to keep only the patches whose sum of intensities are less than the threshold. Defaults to no filtering.
pad_mode – the mode for padding the input image by patch_size to include patches that cross boundaries. Available modes: (Numpy) {
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch) {"constant","reflect","replicate","circular"}. One of the listed string values or a user supplied function. Defaults to None, which means no padding will be applied. See also: https://numpy.org/doc/stable/reference/generated/numpy.pad.html https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html requires pytorch >= 1.10 for best compatibility.allow_missing_keys – don’t raise exception if key is missing.
pad_kwargs – other arguments for the np.pad or torch.pad function. note that np.pad treats channel dimension as the first dimension.
- Returns:
- dictionary, contains the all the original key/value with the values for keys
replaced by the patches, a MetaTensor with following metadata:
PatchKeys.LOCATION: the starting location of the patch in the image,
PatchKeys.COUNT: total number of patches in the image,
”spatial_shape”: spatial size of the extracted patch, and
”offset”: the amount of offset for the patches in the image (starting position of the first patch)
- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – a dictionary containing the tensor-like data to be processed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
GridSplitd#
- class monai.transforms.GridSplitd(*args, **kwargs)[source]#
Split the image into patches based on the provided grid in 2D.
- Parameters:
keys – keys of the corresponding items to be transformed.
grid – a tuple define the shape of the grid upon which the image is split. Defaults to (2, 2)
size – a tuple or an integer that defines the output patch sizes, or a dictionary that define it separately for each key, like {“image”: 3, “mask”, (2, 2)}. If it’s an integer, the value will be repeated for each dimension. The default is None, where the patch size will be inferred from the grid shape.
allow_missing_keys – don’t raise exception if key is missing.
Note: This transform currently support only image with two spatial dimensions.
- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – a dictionary containing the tensor-like data to be processed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
list[dict[Hashable,Union[ndarray,Tensor]]]- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
RandRotate90d#
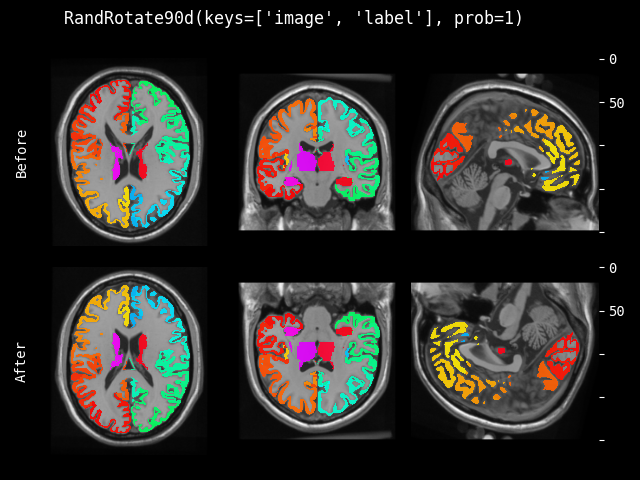
- class monai.transforms.RandRotate90d(keys, prob=0.1, max_k=3, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
Dictionary-based version
monai.transforms.RandRotate90. With probability prob, input arrays are rotated by 90 degrees in the plane specified by spatial_axes.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, prob=0.1, max_k=3, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformprob (
float) – probability of rotating. (Default 0.1, with 10% probability it returns a rotated array.)max_k (
int) – number of rotations will be sampled from np.random.randint(max_k) + 1. (Default 3)spatial_axes (
tuple[int,int]) – 2 int numbers, defines the plane to rotate with 2 spatial axes. Default: (0, 1), this is the first two axis in spatial dimensions.allow_missing_keys (
bool) – don’t raise exception if key is missing.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
Rotate90d#
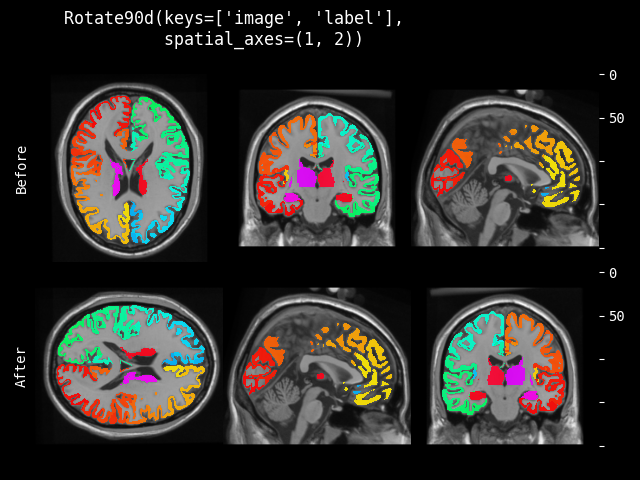
- class monai.transforms.Rotate90d(keys, k=1, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
Dictionary-based wrapper of
monai.transforms.Rotate90.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, k=1, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
- Parameters:
k (
int) – number of times to rotate by 90 degrees.spatial_axes (
tuple[int,int]) – 2 int numbers, defines the plane to rotate with 2 spatial axes. Default: (0, 1), this is the first two axis in spatial dimensions.allow_missing_keys (
bool) – don’t raise exception if key is missing.lazy (
bool) – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
Resized#
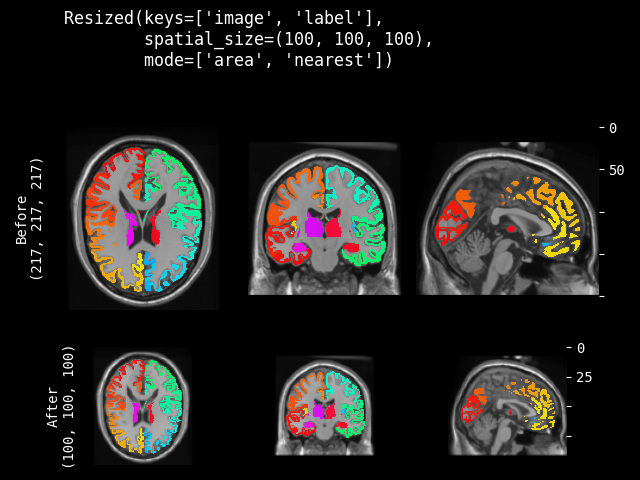
- class monai.transforms.Resized(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Resize.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformspatial_size – expected shape of spatial dimensions after resize operation. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
size_mode – should be “all” or “longest”, if “all”, will use spatial_size for all the spatial dims, if “longest”, rescale the image so that only the longest side is equal to specified spatial_size, which must be an int number in this case, keeping the aspect ratio of the initial image, refer to: https://albumentations.ai/docs/api_reference/augmentations/geometric/resize/ #albumentations.augmentations.geometric.resize.LongestMaxSize.
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} The interpolation mode. Defaults to"area". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html It also can be a sequence of string, each element corresponds to a key inkeys.align_corners – This only has an effect when mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: None. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html It also can be a sequence of bool or None, each element corresponds to a key in
keys.anti_aliasing – bool Whether to apply a Gaussian filter to smooth the image prior to downsampling. It is crucial to filter when downsampling the image to avoid aliasing artifacts. See also
skimage.transform.resizeanti_aliasing_sigma – {float, tuple of floats}, optional Standard deviation for Gaussian filtering used when anti-aliasing. By default, this value is chosen as (s - 1) / 2 where s is the downsampling factor, where s > 1. For the up-size case, s < 1, no anti-aliasing is performed prior to rescaling.
dtype – data type for resampling computation. Defaults to
float32. If None, use the data type of input data.allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
Affined#
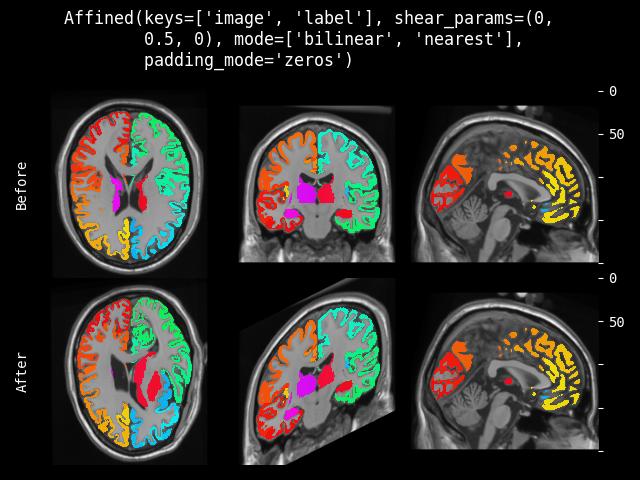
- class monai.transforms.Affined(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Affine.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, rotate_params=None, shear_params=None, translate_params=None, scale_params=None, affine=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None, dtype=<class 'numpy.float32'>, align_corners=False, allow_missing_keys=False, lazy=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
rotate_params – a rotation angle in radians, a scalar for 2D image, a tuple of 3 floats for 3D. Defaults to no rotation.
shear_params –
shearing factors for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ] a tuple of 2 floats for 2D, a tuple of 6 floats for 3D. Defaults to no shearing.
translate_params – a tuple of 2 floats for 2D, a tuple of 3 floats for 3D. Translation is in pixel/voxel relative to the center of the input image. Defaults to no translation.
scale_params – scale factor for every spatial dims. a tuple of 2 floats for 2D, a tuple of 3 floats for 3D. Defaults to 1.0.
affine – if applied, ignore the params (rotate_params, etc.) and use the supplied matrix. Should be square with each side = num of image spatial dimensions + 1.
spatial_size – output image spatial size. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"reflection". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.device – device on which the tensor will be allocated.
dtype – data type for resampling computation. Defaults to
float32. IfNone, use the data type of input data. To be compatible with other modules, the output data type is always float32.align_corners – Defaults to False. See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
See also
monai.transforms.compose.MapTransformRandAffineGridfor the random affine parameters configurations.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
RandAffined#
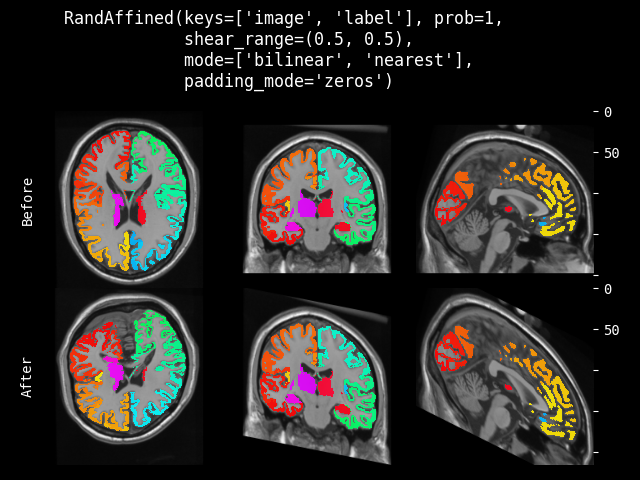
- class monai.transforms.RandAffined(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.RandAffine.This transform is capable of lazy execution. See the Lazy Resampling topic for more information.
- __call__(data, lazy=None)[source]#
- Parameters:
data – a dictionary containing the tensor-like data to be processed. The
keysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensionslazy – a flag to indicate whether this transform should execute lazily or not during this call. Setting this to False or True overrides the
lazyflag set during initialization for this call. Defaults to None.
- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, spatial_size=None, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, mode=bilinear, padding_mode=reflection, cache_grid=False, device=None, allow_missing_keys=False, lazy=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
spatial_size – output image spatial size. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
prob – probability of returning a randomized affine grid. defaults to 0.1, with 10% chance returns a randomized grid.
rotate_range – angle range in radians. If element i is a pair of (min, max) values, then uniform[-rotate_range[i][0], rotate_range[i][1]) will be used to generate the rotation parameter for the i`th spatial dimension. If not, `uniform[-rotate_range[i], rotate_range[i]) will be used. This can be altered on a per-dimension basis. E.g., ((0,3), 1, …): for dim0, rotation will be in range [0, 3], and for dim1 [-1, 1] will be used. Setting a single value will use [-x, x] for dim0 and nothing for the remaining dimensions.
shear_range –
shear range with format matching rotate_range, it defines the range to randomly select shearing factors(a tuple of 2 floats for 2D, a tuple of 6 floats for 3D) for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – translate range with format matching rotate_range, it defines the range to randomly select pixel/voxel to translate for every spatial dims.
scale_range – scaling range with format matching rotate_range. it defines the range to randomly select the scale factor to translate for every spatial dims. A value of 1.0 is added to the result. This allows 0 to correspond to no change (i.e., a scaling of 1.0).
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"reflection". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.cache_grid – whether to cache the identity sampling grid. If the spatial size is not dynamically defined by input image, enabling this option could accelerate the transform.
device – device on which the tensor will be allocated.
allow_missing_keys – don’t raise exception if key is missing.
lazy – a flag to indicate whether this transform should execute lazily or not. Defaults to False
See also
monai.transforms.compose.MapTransformRandAffineGridfor the random affine parameters configurations.
- inverse(data)[source]#
Inverse of
__call__.- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- property lazy#
Get whether lazy evaluation is enabled for this transform instance. :returns: True if the transform is operating in a lazy fashion, False if not.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
Rand2DElasticd#
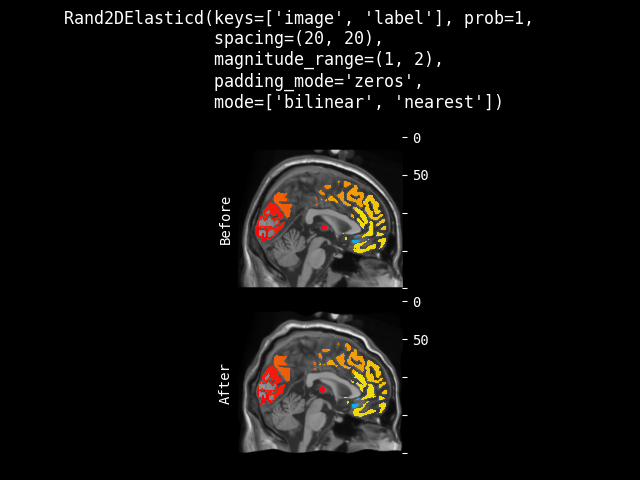
- class monai.transforms.Rand2DElasticd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Rand2DElastic.- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – a dictionary containing the tensor-like data to be processed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, spacing, magnitude_range, spatial_size=None, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, mode=bilinear, padding_mode=reflection, device=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
spacing – distance in between the control points.
magnitude_range – 2 int numbers, the random offsets will be generated from
uniform[magnitude[0], magnitude[1]).spatial_size – specifying output image spatial size [h, w]. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, -1) will be adapted to (32, 64) if the second spatial dimension size of img is 64.
prob – probability of returning a randomized affine grid. defaults to 0.1, with 10% chance returns a randomized grid, otherwise returns a
spatial_sizecentered area extracted from the input image.rotate_range – angle range in radians. If element i is a pair of (min, max) values, then uniform[-rotate_range[i][0], rotate_range[i][1]) will be used to generate the rotation parameter for the i`th spatial dimension. If not, `uniform[-rotate_range[i], rotate_range[i]) will be used. This can be altered on a per-dimension basis. E.g., ((0,3), 1, …): for dim0, rotation will be in range [0, 3], and for dim1 [-1, 1] will be used. Setting a single value will use [-x, x] for dim0 and nothing for the remaining dimensions.
shear_range –
shear range with format matching rotate_range, it defines the range to randomly select shearing factors(a tuple of 2 floats for 2D) for affine matrix, take a 2D affine as example:
[ [1.0, params[0], 0.0], [params[1], 1.0, 0.0], [0.0, 0.0, 1.0], ]
translate_range – translate range with format matching rotate_range, it defines the range to randomly select pixel to translate for every spatial dims.
scale_range – scaling range with format matching rotate_range. it defines the range to randomly select the scale factor to translate for every spatial dims. A value of 1.0 is added to the result. This allows 0 to correspond to no change (i.e., a scaling of 1.0).
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"reflection". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.device – device on which the tensor will be allocated.
allow_missing_keys – don’t raise exception if key is missing.
See also
RandAffineGridfor the random affine parameters configurations.Affinefor the affine transformation parameters configurations.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
Rand3DElasticd#
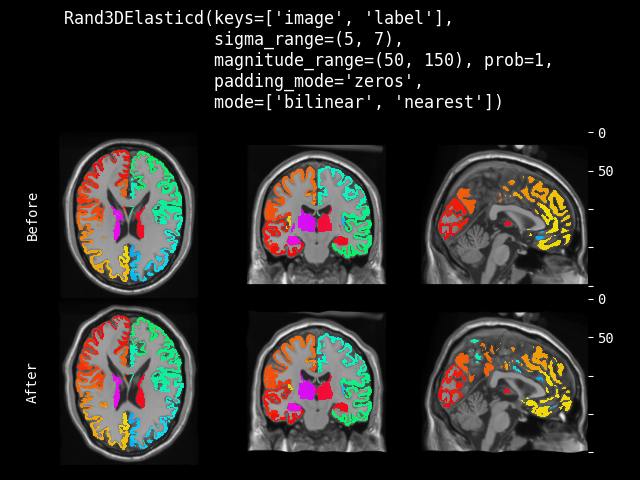
- class monai.transforms.Rand3DElasticd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Rand3DElastic.- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Tensor]) – a dictionary containing the tensor-like data to be processed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
dict[Hashable,Tensor]- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, sigma_range, magnitude_range, spatial_size=None, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, mode=bilinear, padding_mode=reflection, device=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
sigma_range – a Gaussian kernel with standard deviation sampled from
uniform[sigma_range[0], sigma_range[1])will be used to smooth the random offset grid.magnitude_range – the random offsets on the grid will be generated from
uniform[magnitude[0], magnitude[1]).spatial_size – specifying output image spatial size [h, w, d]. if spatial_size and self.spatial_size are not defined, or smaller than 1, the transform will use the spatial size of img. if some components of the spatial_size are non-positive values, the transform will use the corresponding components of img size. For example, spatial_size=(32, 32, -1) will be adapted to (32, 32, 64) if the third spatial dimension size of img is 64.
prob – probability of returning a randomized affine grid. defaults to 0.1, with 10% chance returns a randomized grid, otherwise returns a
spatial_sizecentered area extracted from the input image.rotate_range – angle range in radians. If element i is a pair of (min, max) values, then uniform[-rotate_range[i][0], rotate_range[i][1]) will be used to generate the rotation parameter for the i`th spatial dimension. If not, `uniform[-rotate_range[i], rotate_range[i]) will be used. This can be altered on a per-dimension basis. E.g., ((0,3), 1, …): for dim0, rotation will be in range [0, 3], and for dim1 [-1, 1] will be used. Setting a single value will use [-x, x] for dim0 and nothing for the remaining dimensions.
shear_range –
shear range with format matching rotate_range, it defines the range to randomly select shearing factors(a tuple of 6 floats for 3D) for affine matrix, take a 3D affine as example:
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – translate range with format matching rotate_range, it defines the range to randomly select voxel to translate for every spatial dims.
scale_range – scaling range with format matching rotate_range. it defines the range to randomly select the scale factor to translate for every spatial dims. A value of 1.0 is added to the result. This allows 0 to correspond to no change (i.e., a scaling of 1.0).
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"reflection". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.device – device on which the tensor will be allocated.
allow_missing_keys – don’t raise exception if key is missing.
See also
RandAffineGridfor the random affine parameters configurations.Affinefor the affine transformation parameters configurations.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
GridDistortiond#
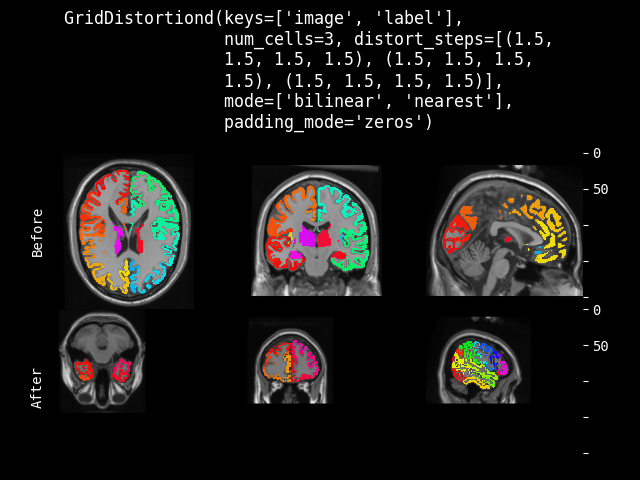
- class monai.transforms.GridDistortiond(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.GridDistortion.- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Tensor]) – a dictionary containing the tensor-like data to be processed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
dict[Hashable,Tensor]- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, num_cells, distort_steps, mode=bilinear, padding_mode=border, device=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
num_cells – number of grid cells on each dimension.
distort_steps – This argument is a list of tuples, where each tuple contains the distort steps of the corresponding dimensions (in the order of H, W[, D]). The length of each tuple equals to num_cells + 1. Each value in the tuple represents the distort step of the related cell.
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.device – device on which the tensor will be allocated.
allow_missing_keys – don’t raise exception if key is missing.
RandGridDistortiond#
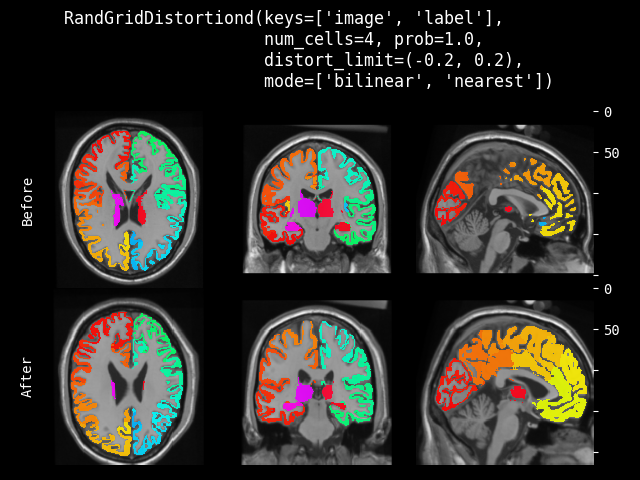
- class monai.transforms.RandGridDistortiond(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.RandGridDistortion.- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Tensor]) – a dictionary containing the tensor-like data to be processed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
dict[Hashable,Tensor]- Returns:
a dictionary containing the transformed data, as well as any other data present in the dictionary
- __init__(keys, num_cells=5, prob=0.1, distort_limit=(-0.03, 0.03), mode=bilinear, padding_mode=border, device=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
num_cells – number of grid cells on each dimension.
prob – probability of returning a randomized grid distortion transform. Defaults to 0.1.
distort_limit – range to randomly distort. If single number, distort_limit is picked from (-distort_limit, distort_limit). Defaults to (-0.03, 0.03).
mode – {
"bilinear","nearest"} or spline interpolation order 0-5 (integers). Interpolation mode to calculate output values. Defaults to"bilinear". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When it’s an integer, the numpy (cpu tensor)/cupy (cuda tensor) backends will be used and the value represents the order of the spline interpolation. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.padding_mode – {
"zeros","border","reflection"} Padding mode for outside grid values. Defaults to"border". See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html When mode is an integer, using numpy/cupy backends, this argument accepts {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}. See also: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html It also can be a sequence, each element corresponds to a key inkeys.device – device on which the tensor will be allocated.
allow_missing_keys – don’t raise exception if key is missing.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandSimulateLowResolutiond#
- class monai.transforms.RandSimulateLowResolutiond(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.RandSimulateLowResolution. Random simulation of low resolution corresponding to nnU-Net’s SimulateLowResolutionTransform (MIC-DKFZ/batchgenerators) First, the array/tensor is resampled at lower resolution as determined by the zoom_factor which is uniformly sampled from the zoom_range. Then, the array/tensor is resampled at the original resolution.- __call__(data)[source]#
- Parameters:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – a dictionary containing the tensor-like data to be transformed. Thekeysspecified in this dictionary must be tensor like arrays that are channel first and have at most three spatial dimensions- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, prob=0.1, downsample_mode=nearest, upsample_mode=trilinear, zoom_range=(0.5, 1.0), align_corners=False, allow_missing_keys=False, device=None)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed.
prob – probability of performing this augmentation
downsample_mode – interpolation mode for downsampling operation
upsample_mode – interpolation mode for upsampling operation
zoom_range – range from which the random zoom factor for the downsampling and upsampling operation is
tensor. (sampled. It determines the shape of the downsampled)
align_corners – This only has an effect when downsample_mode or upsample_mode is ‘linear’, ‘bilinear’, ‘bicubic’ or ‘trilinear’. Default: False See also: https://pytorch.org/docs/stable/generated/torch.nn.functional.interpolate.html
allow_missing_keys – don’t raise exception if key is missing.
device – device on which the tensor will be allocated.
See also
monai.transforms.compose.MapTransform
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
Smooth Field (Dict)#
RandSmoothFieldAdjustContrastd#
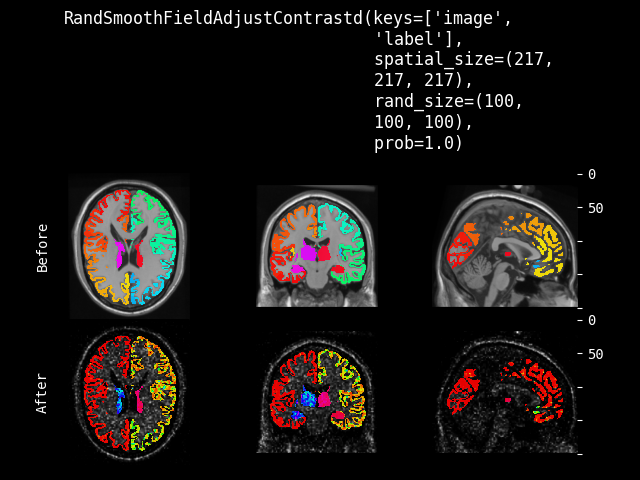
- class monai.transforms.RandSmoothFieldAdjustContrastd(*args, **kwargs)[source]#
Dictionary version of RandSmoothFieldAdjustContrast.
The field is randomized once per invocation by default so the same field is applied to every selected key. The mode parameter specifying interpolation mode for the field can be a single value or a sequence of values with one for each key in keys.
- Parameters:
keys – key names to apply the augment to
spatial_size – size of input arrays, all arrays stated in keys must have same dimensions
rand_size – size of the randomized field to start from
pad – number of pixels/voxels along the edges of the field to pad with 0
mode – interpolation mode to use when upsampling
align_corners – if True align the corners when upsampling field
prob – probability transform is applied
gamma – (min, max) range for exponential field
device – Pytorch device to define field on
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Mapping[Hashable,Union[ndarray,Tensor]]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandSmoothFieldAdjustIntensityd#
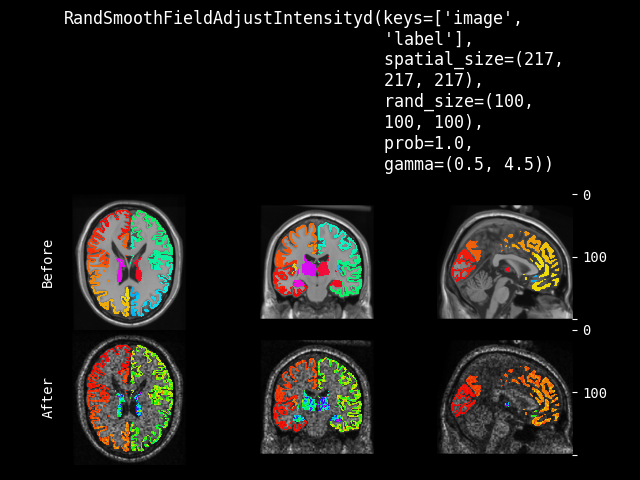
- class monai.transforms.RandSmoothFieldAdjustIntensityd(*args, **kwargs)[source]#
Dictionary version of RandSmoothFieldAdjustIntensity.
The field is randomized once per invocation by default so the same field is applied to every selected key. The mode parameter specifying interpolation mode for the field can be a single value or a sequence of values with one for each key in keys.
- Parameters:
keys – key names to apply the augment to
spatial_size – size of input arrays, all arrays stated in keys must have same dimensions
rand_size – size of the randomized field to start from
pad – number of pixels/voxels along the edges of the field to pad with 0
mode – interpolation mode to use when upsampling
align_corners – if True align the corners when upsampling field
prob – probability transform is applied
gamma – (min, max) range of intensity multipliers
device – Pytorch device to define field on
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Mapping[Hashable,Union[ndarray,Tensor]]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
RandSmoothDeformd#

- class monai.transforms.RandSmoothDeformd(*args, **kwargs)[source]#
Dictionary version of RandSmoothDeform.
The field is randomized once per invocation by default so the same field is applied to every selected key. The field_mode parameter specifying interpolation mode for the field can be a single value or a sequence of values with one for each key in keys. Similarly the grid_mode parameter can be one value or one per key.
- Parameters:
keys – key names to apply the augment to
spatial_size – input array size to which deformation grid is interpolated
rand_size – size of the randomized field to start from
pad – number of pixels/voxels along the edges of the field to pad with 0
field_mode – interpolation mode to use when upsampling the deformation field
align_corners – if True align the corners when upsampling field
prob – probability transform is applied
def_range – value of the deformation range in image size fractions
grid_dtype – type for the deformation grid calculated from the field
grid_mode – interpolation mode used for sampling input using deformation grid
grid_padding_mode – padding mode used for sampling input using deformation grid
grid_align_corners – if True align the corners when sampling the deformation grid
device – Pytorch device to define field on
- __call__(data)[source]#
datais an element which often comes from an iteration over an iterable, such astorch.utils.data.Dataset. This method should return an updated version ofdata. To simplify the input validations, most of the transforms assume thatdatais a Numpy ndarray, PyTorch Tensor or string,the data shape can be:
string data without shape, LoadImage transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChannel expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
This method can optionally take additional arguments to help execute transformation operation.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
Mapping[Hashable,Union[ndarray,Tensor]]
- randomize(data=None)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- set_random_state(seed=None, state=None)[source]#
Set the random state locally, to control the randomness, the derived classes should use
self.Rinstead of np.random to introduce random factors.- Parameters:
seed – set the random state with an integer seed.
state – set the random state with a np.random.RandomState object.
- Raises:
TypeError – When
stateis not anOptional[np.random.RandomState].- Returns:
a Randomizable instance.
MRI transforms (Dict)#
Kspace under-sampling (Dict)#
- class monai.apps.reconstruction.transforms.dictionary.RandomKspaceMaskd(keys, center_fractions, accelerations, spatial_dims=2, is_complex=True, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.apps.reconstruction.transforms.array.RandomKspacemask. Other mask transforms can inherit from this class, for example:monai.apps.reconstruction.transforms.dictionary.EquispacedKspaceMaskd.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransformcenter_fractions (
Sequence[float]) – Fraction of low-frequency columns to be retained. If multiple values are provided, then one of these numbers is chosen uniformly each time.accelerations (
Sequence[float]) – Amount of under-sampling. This should have the same length as center_fractions. If multiple values are provided, then one of these is chosen uniformly each time.spatial_dims (
int) – Number of spatial dims (e.g., it’s 2 for a 2D data; it’s also 2 for pseudo-3D datasets like the fastMRI dataset). The last spatial dim is selected for sampling. For the fastMRI dataset, k-space has the form (…,num_slices,num_coils,H,W) and sampling is done along W. For a general 3D data with the shape (…,num_coils,H,W,D), sampling is done along D.is_complex (
bool) – if True, then the last dimension will be reserved for real/imaginary parts.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- class monai.apps.reconstruction.transforms.dictionary.EquispacedKspaceMaskd(keys, center_fractions, accelerations, spatial_dims=2, is_complex=True, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.apps.reconstruction.transforms.array.EquispacedKspaceMask.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransformcenter_fractions (
Sequence[float]) – Fraction of low-frequency columns to be retained. If multiple values are provided, then one of these numbers is chosen uniformly each time.accelerations (
Sequence[float]) – Amount of under-sampling. This should have the same length as center_fractions. If multiple values are provided, then one of these is chosen uniformly each time.spatial_dims (
int) – Number of spatial dims (e.g., it’s 2 for a 2D data; it’s also 2 for pseudo-3D datasets like the fastMRI dataset). The last spatial dim is selected for sampling. For the fastMRI dataset, k-space has the form (…,num_slices,num_coils,H,W) and sampling is done along W. For a general 3D data with the shape (…,num_coils,H,W,D), sampling is done along D.is_complex (
bool) – if True, then the last dimension will be reserved for real/imaginary parts.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- __call__(data)#
- Parameters:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – is a dictionary containing (key,value) pairs from the loaded dataset- Return type:
dict[Hashable,Tensor]- Returns:
the new data dictionary
ExtractDataKeyFromMetaKeyd#
- class monai.apps.reconstruction.transforms.dictionary.ExtractDataKeyFromMetaKeyd(keys, meta_key, allow_missing_keys=False)[source]#
Moves keys from meta to data. It is useful when a dataset of paired samples is loaded and certain keys should be moved from meta to data.
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys to be transferred from meta to datameta_key (
str) – the meta key where all the meta-data is storedallow_missing_keys (
bool) – don’t raise exception if key is missing
Example
When the fastMRI dataset is loaded, “kspace” is stored in the data dictionary, but the ground-truth image with the key “reconstruction_rss” is stored in the meta data. In this case, ExtractDataKeyFromMetaKeyd moves “reconstruction_rss” to data.
ReferenceBasedSpatialCropd#
- class monai.apps.reconstruction.transforms.dictionary.ReferenceBasedSpatialCropd(keys, ref_key, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.SpatialCrop. This is similar tomonai.transforms.SpatialCropdwhich is a general purpose cropper to produce sub-volume region of interest (ROI). Their difference is that this transform does cropping according to a reference image.If a dimension of the expected ROI size is larger than the input image size, will not crop that dimension.
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformref_key (
str) – key of the item to be used to crop items of “keys”allow_missing_keys (
bool) – don’t raise exception if key is missing.
Example
In an image reconstruction task, let keys=[“image”] and ref_key=[“target”]. Also, let data be the data dictionary. Then, ReferenceBasedSpatialCropd center-crops data[“image”] based on the spatial size of data[“target”] by calling
monai.transforms.SpatialCrop.- __call__(data)[source]#
This transform can support to crop ND spatial (channel-first) data. It also supports pseudo ND spatial data (e.g., (C,H,W) is a pseudo-3D data point where C is the number of slices)
- Parameters:
data (
Mapping[Hashable,Tensor]) – is a dictionary containing (key,value) pairs from the loaded dataset- Return type:
dict[Hashable,Tensor]- Returns:
the new data dictionary
ReferenceBasedNormalizeIntensityd#
- class monai.apps.reconstruction.transforms.dictionary.ReferenceBasedNormalizeIntensityd(keys, ref_key, subtrahend=None, divisor=None, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.NormalizeIntensity. This is similar tomonai.transforms.NormalizeIntensitydand can normalize non-zero values or the entire image. The difference is that this transform does normalization according to a reference image.- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
ref_key – key of the item to be used to normalize items of “keys”
subtrahend – the amount to subtract by (usually the mean)
divisor – the amount to divide by (usually the standard deviation)
nonzero – whether only normalize non-zero values.
channel_wise – if True, calculate on each channel separately, otherwise, calculate on the entire image directly. default to False.
dtype – output data type, if None, same as input image. defaults to float32.
allow_missing_keys – don’t raise exception if key is missing.
Example
In an image reconstruction task, let keys=[“image”, “target”] and ref_key=[“image”]. Also, let data be the data dictionary. Then, ReferenceBasedNormalizeIntensityd normalizes data[“target”] and data[“image”] based on the mean-std of data[“image”] by calling
monai.transforms.NormalizeIntensity.- __call__(data)[source]#
This transform can support to normalize ND spatial (channel-first) data. It also supports pseudo ND spatial data (e.g., (C,H,W) is a pseudo-3D data point where C is the number of slices)
- Parameters:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – is a dictionary containing (key,value) pairs from the loaded dataset- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
the new data dictionary
Lazy (Dict)#
ApplyPendingd#
- class monai.transforms.ApplyPendingd(keys)[source]#
ApplyPendingd can be inserted into a pipeline that is being executed lazily in order to ensure resampling happens before the next transform. It doesn’t do anything itself, but its presence causes the pipeline to be executed as it doesn’t implement
LazyTraitSee
Composefor a detailed explanation of the lazy resampling feature.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – the keys for tensors that should have their pending transforms executed
Utility (Dict)#
Identityd#
- class monai.transforms.Identityd(keys, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.Identity.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
AsChannelLastd#
- class monai.transforms.AsChannelLastd(keys, channel_dim=0, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.AsChannelLast.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, channel_dim=0, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformchannel_dim (
int) – which dimension of input image is the channel, default is the first dimension.allow_missing_keys (
bool) – don’t raise exception if key is missing.
EnsureChannelFirstd#
- class monai.transforms.EnsureChannelFirstd(keys, strict_check=True, allow_missing_keys=False, channel_dim=None)[source]#
Dictionary-based wrapper of
monai.transforms.EnsureChannelFirst.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, strict_check=True, allow_missing_keys=False, channel_dim=None)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformstrict_check (
bool) – whether to raise an error when the meta information is insufficient.allow_missing_keys (
bool) – don’t raise exception if key is missing.channel_dim – This argument can be used to specify the original channel dimension (integer) of the input array. It overrides the original_channel_dim from provided MetaTensor input. If the input array doesn’t have a channel dim, this value should be
'no_channel'. If this is set to None, this class relies on img or meta_dict to provide the channel dimension.
RepeatChanneld#
- class monai.transforms.RepeatChanneld(keys, repeats, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.RepeatChannel.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, repeats, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformrepeats (
int) – the number of repetitions for each element.allow_missing_keys (
bool) – don’t raise exception if key is missing.
SplitDimd#
- class monai.transforms.SplitDimd(*args, **kwargs)[source]#
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, output_postfixes=None, dim=0, keepdim=True, update_meta=True, list_output=False, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformoutput_postfixes – the postfixes to construct keys to store split data. for example: if the key of input data is pred and split 2 classes, the output data keys will be: pred_(output_postfixes[0]), pred_(output_postfixes[1]) if None, using the index number: pred_0, pred_1, … pred_N.
dim – which dimension of input image is the channel, default to 0.
keepdim – if True, output will have singleton in the split dimension. If False, this dimension will be squeezed.
update_meta – if True, copy [key]_meta_dict for each output and update affine to reflect the cropped image
list_output – it True, the output will be a list of dictionaries with the same keys as original.
allow_missing_keys – don’t raise exception if key is missing.
CastToTyped#
- class monai.transforms.CastToTyped(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.CastToType.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformdtype – convert image to this data type, default is np.float32. it also can be a sequence of dtypes or torch.dtype, each element corresponds to a key in
keys.allow_missing_keys – don’t raise exception if key is missing.
ToTensord#
- class monai.transforms.ToTensord(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ToTensor.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, dtype=None, device=None, wrap_sequence=True, track_meta=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformdtype – target data content type to convert, for example: torch.float, etc.
device – specify the target device to put the Tensor data.
wrap_sequence – if False, then lists will recursively call this function, default to True. E.g., if False, [1, 2] -> [tensor(1), tensor(2)], if True, then [1, 2] -> tensor([1, 2]).
track_meta – if True convert to
MetaTensor, otherwise to PytorchTensor, ifNonebehave according to return value of py:func:monai.data.meta_obj.get_track_meta.allow_missing_keys – don’t raise exception if key is missing.
ToNumpyd#
- class monai.transforms.ToNumpyd(keys, dtype=None, wrap_sequence=True, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.ToNumpy.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Any]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, dtype=None, wrap_sequence=True, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformdtype (
Union[dtype,type,str,None]) – target data type when converting to numpy array.wrap_sequence (
bool) – if False, then lists will recursively call this function, default to True. E.g., if False, [1, 2] -> [array(1), array(2)], if True, then [1, 2] -> array([1, 2]).allow_missing_keys (
bool) – don’t raise exception if key is missing.
ToPIL#
ToCupyd#
- class monai.transforms.ToCupyd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ToCupy.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformdtype – data type specifier. It is inferred from the input by default. if not None, must be an argument of numpy.dtype, for more details: https://docs.cupy.dev/en/stable/reference/generated/cupy.array.html.
wrap_sequence – if False, then lists will recursively call this function, default to True. E.g., if False, [1, 2] -> [array(1), array(2)], if True, then [1, 2] -> array([1, 2]).
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ToPILd#
- class monai.transforms.ToPILd(keys, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.ToNumpy.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Any]- Returns:
An updated dictionary version of
databy applying the transform.
DeleteItemsd#
- class monai.transforms.DeleteItemsd(*args, **kwargs)[source]#
Delete specified items from data dictionary to release memory. It will remove the key-values and copy the others to construct a new dictionary.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, sep='.', use_re=False)[source]#
- Parameters:
keys – keys of the corresponding items to delete, can be “A{sep}B{sep}C” to delete key C in nested dictionary, C can be regular expression. See also:
monai.transforms.compose.MapTransformsep – the separator tag to define nested dictionary keys, default to “.”.
use_re – whether the specified key is a regular expression, it also can be a list of bool values, mapping them to keys.
SelectItemsd#
- class monai.transforms.SelectItemsd(keys, allow_missing_keys=False)[source]#
Select only specified items from data dictionary to release memory. It will copy the selected key-values and construct a new dictionary.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
FlattenSubKeysd#
- class monai.transforms.FlattenSubKeysd(*args, **kwargs)[source]#
If an item is dictionary, it flatten the item by moving the sub-items (defined by sub-keys) to the top level. {“pred”: {“a”: …, “b”, … }} –> {“a”: …, “b”, … }
- Parameters:
keys – keys of the corresponding items to be flatten
sub_keys – the sub-keys of items to be flatten. If not provided all the sub-keys are flattened.
delete_keys – whether to delete the key of the items that their sub-keys are flattened. Default to True.
prefix – optional prefix to be added to the sub-keys when moving to the top level. By default no prefix will be added.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
Transposed#
- class monai.transforms.Transposed(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Transpose.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
SqueezeDimd#
- class monai.transforms.SqueezeDimd(keys, dim=0, update_meta=True, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.SqueezeDim.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, dim=0, update_meta=True, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformdim (
int) – dimension to be squeezed. Default: 0 (the first dimension)update_meta (
bool) – whether to update the meta info if the input is a metatensor. Default isTrue.allow_missing_keys (
bool) – don’t raise exception if key is missing.
DataStatsd#
- class monai.transforms.DataStatsd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.DataStats.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, prefix='Data', data_type=True, data_shape=True, value_range=True, data_value=False, additional_info=None, name='DataStats', allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformprefix – will be printed in format: “{prefix} statistics”. it also can be a sequence of string, each element corresponds to a key in
keys.data_type – whether to show the type of input data. it also can be a sequence of bool, each element corresponds to a key in
keys.data_shape – whether to show the shape of input data. it also can be a sequence of bool, each element corresponds to a key in
keys.value_range – whether to show the value range of input data. it also can be a sequence of bool, each element corresponds to a key in
keys.data_value – whether to show the raw value of input data. it also can be a sequence of bool, each element corresponds to a key in
keys. a typical example is to print some properties of Nifti image: affine, pixdim, etc.additional_info – user can define callable function to extract additional info from input data. it also can be a sequence of string, each element corresponds to a key in
keys.name – identifier of logging.logger to use, defaulting to “DataStats”.
allow_missing_keys – don’t raise exception if key is missing.
SimulateDelayd#
- class monai.transforms.SimulateDelayd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.SimulateDelay.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, delay_time=0.0, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformdelay_time – The minimum amount of time, in fractions of seconds, to accomplish this identity task. It also can be a sequence of string, each element corresponds to a key in
keys.allow_missing_keys – don’t raise exception if key is missing.
CopyItemsd#
- class monai.transforms.CopyItemsd(*args, **kwargs)[source]#
Copy specified items from data dictionary and save with different key names. It can copy several items together and copy several times.
- __call__(data)[source]#
- Raises:
KeyError – When a key in
self.namesalready exists indata.- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, times=1, names=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformtimes – expected copy times, for example, if keys is “img”, times is 3, it will add 3 copies of “img” data to the dictionary, default to 1.
names – the names corresponding to the newly copied data, the length should match len(keys) x times. for example, if keys is [“img”, “seg”] and times is 2, names can be: [“img_1”, “seg_1”, “img_2”, “seg_2”]. if None, use “{key}_{index}” as key for copy times N, index from 0 to N-1.
allow_missing_keys – don’t raise exception if key is missing.
- Raises:
ValueError – When
timesis nonpositive.ValueError – When
len(names)is notlen(keys) * times. Incompatible values.
ConcatItemsd#
- class monai.transforms.ConcatItemsd(keys, name, dim=0, allow_missing_keys=False)[source]#
Concatenate specified items from data dictionary together on the first dim to construct a big array. Expect all the items are numpy array or PyTorch Tensor or MetaTensor. Return the first input’s meta information when items are MetaTensor.
- __call__(data)[source]#
- Raises:
TypeError – When items in
datadiffer in type.TypeError – When the item type is not in
Union[numpy.ndarray, torch.Tensor, MetaTensor].
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, name, dim=0, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be concatenated together. See also:monai.transforms.compose.MapTransformname (
str) – the name corresponding to the key to store the concatenated data.dim (
int) – on which dimension to concatenate the items, default is 0.allow_missing_keys (
bool) – don’t raise exception if key is missing.
Lambdad#
- class monai.transforms.Lambdad(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.Lambda.For example:
input_data={'image': np.zeros((10, 2, 2)), 'label': np.ones((10, 2, 2))} lambd = Lambdad(keys='label', func=lambda x: x[:4, :, :]) print(lambd(input_data)['label'].shape) (4, 2, 2)
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformfunc – Lambda/function to be applied. It also can be a sequence of Callable, each element corresponds to a key in
keys.inv_func – Lambda/function of inverse operation if want to invert transforms, default to lambda x: x. It also can be a sequence of Callable, each element corresponds to a key in
keys.track_meta – If False, then standard data objects will be returned (e.g., torch.Tensor` and np.ndarray) as opposed to MONAI’s enhanced objects. By default, this is True.
overwrite – whether to overwrite the original data in the input dictionary with lambda function output. it can be bool or str, when setting to str, it will create a new key for the output and keep the value of key intact. default to True. it also can be a sequence of bool or str, each element corresponds to a key in
keys.allow_missing_keys – don’t raise exception if key is missing.
- Note: The inverse operation doesn’t allow to define extra_info or access other information, such as the
image’s original size. If need these complicated information, please write a new InvertibleTransform directly.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]- Returns:
An updated dictionary version of
databy applying the transform.
RandLambdad#
- class monai.transforms.RandLambdad(*args, **kwargs)[source]#
Randomizable version
monai.transforms.Lambdad, the input func may contain random logic, or randomly execute the function based on prob. so CacheDataset will not execute it and cache the results.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformfunc – Lambda/function to be applied. It also can be a sequence of Callable, each element corresponds to a key in
keys.inv_func – Lambda/function of inverse operation if want to invert transforms, default to lambda x: x. It also can be a sequence of Callable, each element corresponds to a key in
keys.track_meta – If False, then standard data objects will be returned (e.g., torch.Tensor` and np.ndarray) as opposed to MONAI’s enhanced objects. By default, this is True.
overwrite – whether to overwrite the original data in the input dictionary with lambda function output. default to True. it also can be a sequence of bool, each element corresponds to a key in
keys.prob – probability of executing the random function, default to 1.0, with 100% probability to execute. note that all the data specified by keys will share the same random probability to execute or not.
allow_missing_keys – don’t raise exception if key is missing.
For more details, please check
monai.transforms.Lambdad.- Note: The inverse operation doesn’t allow to define extra_info or access other information, such as the
image’s original size. If need these complicated information, please write a new InvertibleTransform directly.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
RemoveRepeatedChanneld#
- class monai.transforms.RemoveRepeatedChanneld(keys, repeats, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.RemoveRepeatedChannel.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, repeats, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformrepeats (
int) – the number of repetitions for each element.allow_missing_keys (
bool) – don’t raise exception if key is missing.
LabelToMaskd#
- class monai.transforms.LabelToMaskd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.LabelToMask.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformselect_labels – labels to generate mask from. for 1 channel label, the select_labels is the expected label values, like: [1, 2, 3]. for One-Hot format label, the select_labels is the expected channel indices.
merge_channels – whether to use np.any() to merge the result on channel dim. if yes, will return a single channel mask with binary data.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
FgBgToIndicesd#
- class monai.transforms.FgBgToIndicesd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.FgBgToIndices.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformfg_postfix – postfix to save the computed foreground indices in dict. for example, if computed on label and postfix = “_fg_indices”, the key will be label_fg_indices.
bg_postfix – postfix to save the computed background indices in dict. for example, if computed on label and postfix = “_bg_indices”, the key will be label_bg_indices.
image_key – if image_key is not None, use
label == 0 & image > image_thresholdto determine the negative sample(background). so the output items will not map to all the voxels in the label.image_threshold – if enabled image_key, use
image > image_thresholdto determine the valid image content area and select background only in this area.output_shape – expected shape of output indices. if not None, unravel indices to specified shape.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ClassesToIndicesd#
- class monai.transforms.ClassesToIndicesd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ClassesToIndices.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformindices_postfix – postfix to save the computed indices of all classes in dict. for example, if computed on label and postfix = “_cls_indices”, the key will be label_cls_indices.
num_classes – number of classes for argmax label, not necessary for One-Hot label.
image_key – if image_key is not None, use
image > image_thresholdto define valid region, and only select the indices within the valid region.image_threshold – if enabled image_key, use
image > image_thresholdto determine the valid image content area and select only the indices of classes in this area.output_shape – expected shape of output indices. if not None, unravel indices to specified shape.
max_samples_per_class – maximum length of indices to sample in each class to reduce memory consumption. Default is None, no subsampling.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Returns:
An updated dictionary version of
databy applying the transform.
ConvertToMultiChannelBasedOnBratsClassesd#
- class monai.transforms.ConvertToMultiChannelBasedOnBratsClassesd(keys, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.ConvertToMultiChannelBasedOnBratsClasses. Convert labels to multi channels based on brats18 classes: label 1 is the necrotic and non-enhancing tumor core label 2 is the peritumoral edema label 4 is the GD-enhancing tumor The possible classes are TC (Tumor core), WT (Whole tumor) and ET (Enhancing tumor).- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
AddExtremePointsChanneld#
- class monai.transforms.AddExtremePointsChanneld(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.AddExtremePointsChannel.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformlabel_key – key to label source to get the extreme points.
background – Class index of background label, defaults to 0.
pert – Random perturbation amount to add to the points, defaults to 0.0.
sigma – if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
rescale_min – minimum value of output data.
rescale_max – maximum value of output data.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
Call self as a function.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]
- randomize(label)[source]#
Within this method,
self.Rshould be used, instead of np.random, to introduce random factors.all
self.Rcalls happen here so that we have a better chance to identify errors of sync the random state.This method can generate the random factors based on properties of the input data.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
None
TorchVisiond#
- class monai.transforms.TorchVisiond(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.TorchVisionfor non-randomized transforms. For randomized transforms of TorchVision usemonai.transforms.RandTorchVisiond.Note
As most of the TorchVision transforms only work for PIL image and PyTorch Tensor, this transform expects input data to be dict of PyTorch Tensors, users can easily call ToTensord transform to convert Numpy to Tensor.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformname (
str) – The transform name in TorchVision package.allow_missing_keys (
bool) – don’t raise exception if key is missing.args – parameters for the TorchVision transform.
kwargs – parameters for the TorchVision transform.
RandTorchVisiond#
- class monai.transforms.RandTorchVisiond(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.TorchVisionfor randomized transforms. For deterministic non-randomized transforms of TorchVision usemonai.transforms.TorchVisiond.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformname (
str) – The transform name in TorchVision package.allow_missing_keys (
bool) – don’t raise exception if key is missing.args – parameters for the TorchVision transform.
kwargs – parameters for the TorchVision transform.
Note
As most of the TorchVision transforms only work for PIL image and PyTorch Tensor, this transform expects input data to be dict of PyTorch Tensors. Users should call ToTensord transform first to convert Numpy to Tensor.
This class inherits the
Randomizablepurely to prevent any dataset caching to skip the transform computation. If the random factor of the underlying torchvision transform is not derived from self.R, the results may not be deterministic. See Also:monai.transforms.Randomizable.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
MapLabelValued#
- class monai.transforms.MapLabelValued(keys, orig_labels, target_labels, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.MapLabelValue.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, orig_labels, target_labels, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformorig_labels (
Sequence) – original labels that map to others.target_labels (
Sequence) – expected label values, 1: 1 map to the orig_labels.dtype (
Union[dtype,type,str,None]) – convert the output data to dtype, default to float32. if dtype is from PyTorch, the transform will use the pytorch backend, else with numpy backend.allow_missing_keys (
bool) – don’t raise exception if key is missing.
EnsureTyped#
- class monai.transforms.EnsureTyped(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.EnsureType.Ensure the input data to be a PyTorch Tensor or numpy array, support: numpy array, PyTorch Tensor, float, int, bool, string and object keep the original. If passing a dictionary, list or tuple, still return dictionary, list or tuple and recursively convert every item to the expected data type if wrap_sequence=False.
Note: Currently, we only convert tensor data to numpy array or scalar number in the inverse operation.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, data_type='tensor', dtype=None, device=None, wrap_sequence=True, track_meta=None, allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformdata_type – target data type to convert, should be “tensor” or “numpy”.
dtype – target data content type to convert, for example: np.float32, torch.float, etc. It also can be a sequence of dtype, each element corresponds to a key in
keys.device – for Tensor data type, specify the target device.
wrap_sequence – if False, then lists will recursively call this function, default to True. E.g., if False, [1, 2] -> [tensor(1), tensor(2)], if True, then [1, 2] -> tensor([1, 2]).
track_meta – whether to convert to MetaTensor when data_type is “tensor”. If False, the output data type will be torch.Tensor. Default to the return value of get_track_meta.
allow_missing_keys – don’t raise exception if key is missing.
IntensityStatsd#
- class monai.transforms.IntensityStatsd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.IntensityStats. Compute statistics for the intensity values of input image and store into the metadata dictionary. For example: if ops=[lambda x: np.mean(x), “max”] and key_prefix=”orig”, may generate below stats: {“orig_custom_0”: 1.5, “orig_max”: 3.0}.- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformops – expected operations to compute statistics for the intensity. if a string, will map to the predefined operations, supported: [“mean”, “median”, “max”, “min”, “std”] mapping to np.nanmean, np.nanmedian, np.nanmax, np.nanmin, np.nanstd. if a callable function, will execute the function on input image.
key_prefix – the prefix to combine with ops name to generate the key to store the results in the metadata dictionary. if some ops are callable functions, will use “{key_prefix}_custom_{index}” as the key, where index counts from 0.
mask_keys – if not None, specify the mask array for the image to extract only the interested area to compute statistics, mask must have the same shape as the image. it should be a sequence of strings or None, map to the keys.
channel_wise – whether to compute statistics for every channel of input image separately. if True, return a list of values for every operation, default to False.
meta_keys – explicitly indicate the key of the corresponding metadata dictionary. used to store the computed statistics to the meta dict. for example, for data with key image, the metadata by default is in image_meta_dict. the metadata is a dictionary object which contains: filename, original_shape, etc. it can be a sequence of string, map to the keys. if None, will try to construct meta_keys by key_{meta_key_postfix}.
meta_key_postfix – if meta_keys is None, use key_{postfix} to fetch the metadata according to the key data, default is meta_dict, the metadata is a dictionary object. used to store the computed statistics to the meta dict.
allow_missing_keys – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ToDeviced#
- class monai.transforms.ToDeviced(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ToDevice.- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Tensor]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, device, allow_missing_keys=False, **kwargs)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformdevice – target device to move the Tensor, for example: “cuda:1”.
allow_missing_keys – don’t raise exception if key is missing.
kwargs – other args for the PyTorch Tensor.to() API, for more details: https://pytorch.org/docs/stable/generated/torch.Tensor.to.html.
CuCIMd#
- class monai.transforms.CuCIMd(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.CuCIMfor non-randomized transforms. For randomized transforms of CuCIM usemonai.transforms.RandCuCIMd.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformname (
str) – The transform name in CuCIM package.allow_missing_keys (
bool) – don’t raise exception if key is missing.args – parameters for the CuCIM transform.
kwargs – parameters for the CuCIM transform.
Note
CuCIM transforms only work with CuPy arrays, this transform expects input data to be cupy.ndarray. Users can call ToCuPy transform to convert a numpy array or torch tensor to cupy array.
RandCuCIMd#
- class monai.transforms.RandCuCIMd(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.CuCIMfor randomized transforms. For deterministic non-randomized transforms of CuCIM usemonai.transforms.CuCIMd.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformname (
str) – The transform name in CuCIM package.allow_missing_keys (
bool) – don’t raise exception if key is missing.args – parameters for the CuCIM transform.
kwargs – parameters for the CuCIM transform.
Note
CuCIM transform only work with CuPy arrays, so this transform expects input data to be cupy.ndarray. Users should call ToCuPy transform first to convert a numpy array or torch tensor to cupy array.
This class inherits the
Randomizablepurely to prevent any dataset caching to skip the transform computation. If the random factor of the underlying cuCIM transform is not derived from self.R, the results may not be deterministic. See Also:monai.transforms.Randomizable.
AddCoordinateChannelsd#
- class monai.transforms.AddCoordinateChannelsd(keys, spatial_dims, allow_missing_keys=False)[source]#
Dictionary-based wrapper of
monai.transforms.AddCoordinateChannels.- Parameters:
keys (
Union[Collection[Hashable],Hashable]) – keys of the corresponding items to be transformed. See also:monai.transforms.compose.MapTransformspatial_dims (
Sequence[int]) – the spatial dimensions that are to have their coordinates encoded in a channel and appended to the input image. E.g., (0, 1, 2) represents H, W, D dims and append three channels to the input image, encoding the coordinates of the input’s three spatial dimensions.allow_missing_keys (
bool) – don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
ImageFilterd#
- class monai.transforms.ImageFilterd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.ImageFilter.- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
kernel – A string specifying the kernel or a custom kernel as torch.Tenor or np.ndarray. Available options are: mean, laplacian, elliptical, sobel_{w,h,d}`
kernel_size – A single integer value specifying the size of the quadratic or cubic kernel. Computational complexity increases exponentially with kernel_size, which should be considered when choosing the kernel size.
allow_missing_keys – Don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
RandImageFilterd#
- class monai.transforms.RandImageFilterd(*args, **kwargs)[source]#
Dictionary-based wrapper of
monai.transforms.RandomFilterKernel.- Parameters:
keys – keys of the corresponding items to be transformed. See also: monai.transforms.MapTransform
kernel – A string specifying the kernel or a custom kernel as torch.Tenor or np.ndarray. Available options are: mean, laplacian, elliptical, sobel_{w,h,d}`
kernel_size – A single integer value specifying the size of the quadratic or cubic kernel. Computational complexity increases exponentially with kernel_size, which should be considered when choosing the kernel size.
prob – Probability the transform is applied to the data
allow_missing_keys – Don’t raise exception if key is missing.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
MetaTensor#
ToMetaTensord#
- class monai.transforms.ToMetaTensord(keys, allow_missing_keys=False)[source]#
Dictionary-based transform to convert a dictionary to MetaTensor.
If input is {“a”: torch.Tensor, “a_meta_dict”: dict, “b”: …}, then output will have the form {“a”: MetaTensor, “b”: MetaTensor}.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
FromMetaTensord#
- class monai.transforms.FromMetaTensord(*args, **kwargs)[source]#
Dictionary-based transform to convert MetaTensor to a dictionary.
If input is {“a”: MetaTensor, “b”: MetaTensor}, then output will have the form {“a”: torch.Tensor, “a_meta_dict”: dict, “a_transforms”: list, “b”: …}.
- __call__(data)[source]#
dataoften comes from an iteration over an iterable, such astorch.utils.data.Dataset.To simplify the input validations, this method assumes:
datais a Python dictionary,data[key]is a Numpy ndarray, PyTorch Tensor or string, wherekeyis an element ofself.keys, the data shape can be:string data without shape, LoadImaged transform expects file paths,
most of the pre-/post-processing transforms expect:
(num_channels, spatial_dim_1[, spatial_dim_2, ...]), except for example: AddChanneld expects (spatial_dim_1[, spatial_dim_2, …])
the channel dimension is often not omitted even if number of channels is one.
- Raises:
NotImplementedError – When the subclass does not override this method.
- Return type:
dict[Hashable,Union[ndarray,Tensor]]- Returns:
An updated dictionary version of
databy applying the transform.
- __init__(keys, data_type='tensor', allow_missing_keys=False)[source]#
- Parameters:
keys – keys of the corresponding items to be transformed. See also:
monai.transforms.compose.MapTransformdata_type – target data type to convert, should be “tensor” or “numpy”.
allow_missing_keys – don’t raise exception if key is missing.
Transform Adaptors#
How to use the adaptor function#
The key to using ‘adaptor’ lies in understanding the function that want to adapt. The ‘inputs’ and ‘outputs’ parameters take either strings, lists/tuples of strings or a dictionary mapping strings, depending on call signature of the function being called.
The adaptor function is written to minimise the cognitive load on the caller. There should be a minimal number of cases where the caller has to set anything on the input parameter, and for functions that return a single value, it is only necessary to name the dictionary keyword to which that value is assigned.
Use of outputs#
outputs can take either a string, a list/tuple of string or a dict of string to string, depending on what the transform being adapted returns:
If the transform returns a single argument, then outputs can be supplied a string that indicates what key to assign the return value to in the dictionary
If the transform returns a list/tuple of values, then outputs can be supplied a list/tuple of the same length. The strings in outputs map the return value at the corresponding position to a key in the dictionary
If the transform returns a dictionary of values, then outputs must be supplied a dictionary that maps keys in the function’s return dictionary to the dictionary being passed between functions
Note, the caller is free to use a more complex way of specifying the outputs parameter than is required. The following are synonymous and will be treated identically:
# single argument
adaptor(MyTransform(), 'image')
adaptor(MyTransform(), ['image'])
adaptor(MyTransform(), {'image': 'image'})
# multiple arguments
adaptor(MyTransform(), ['image', 'label'])
adaptor(MyTransform(), {'image': 'image', 'label': 'label'})
Use of inputs#
inputs can usually be omitted when using adaptor. It is only required when a the function’s parameter names do not match the names in the dictionary that is used to chain transform calls.
class MyTransform1:
def __call__(self, image):
# do stuff to image
return image + 1
class MyTransform2:
def __call__(self, img_dict):
# do stuff to image
img_dict["image"] += 1
return img_dict
xform = Compose([adaptor(MyTransform1(), "image"), MyTransform2()])
d = {"image": 1}
print(xform(d))
>>> {'image': 3}
class MyTransform3:
def __call__(self, img_dict):
# do stuff to image
img_dict["image"] -= 1
img_dict["segment"] = img_dict["image"]
return img_dict
class MyTransform4:
def __call__(self, img, seg):
# do stuff to image
img -= 1
seg -= 1
return img, seg
xform = Compose([MyTransform3(), adaptor(MyTransform4(), ["img", "seg"], {"image": "img", "segment": "seg"})])
d = {"image": 1}
print(xform(d))
>>> {'image': 0, 'segment': 0, 'img': -1, 'seg': -1}
Inputs:
dictionary in: None | Name maps
params in (match): None | Name list | Name maps
params in (mismatch): Name maps
params & **kwargs (match) : None | Name maps
params & **kwargs (mismatch) : Name maps
Outputs:
dictionary out: None | Name maps
list/tuple out: list/tuple
variable out: string
FunctionSignature#
adaptor#
apply_alias#
to_kwargs#
Utilities#
- class monai.transforms.utils.Fourier[source]#
Helper class storing Fourier mappings
- static inv_shift_fourier(k, spatial_dims, n_dims=None)[source]#
Applies inverse shift and fourier transform. Only the spatial dimensions are transformed.
- Parameters:
k – K-space data.
spatial_dims – Number of spatial dimensions.
- Returns:
Tensor in image space.
- Return type:
x
- static shift_fourier(x, spatial_dims)[source]#
Applies fourier transform and shifts the zero-frequency component to the center of the spectrum. Only the spatial dimensions get transformed.
- Parameters:
x (
Union[ndarray,Tensor]) – Image to transform.spatial_dims (
int) – Number of spatial dimensions.
- Returns
k: K-space data.
- Return type:
Union[ndarray,Tensor]
- monai.transforms.utils.allow_missing_keys_mode(transform)[source]#
Temporarily set all MapTransforms to not throw an error if keys are missing. After, revert to original states.
- Parameters:
transform – either MapTransform or a Compose
Example:
data = {"image": np.arange(16, dtype=float).reshape(1, 4, 4)} t = SpatialPadd(["image", "label"], 10, allow_missing_keys=False) _ = t(data) # would raise exception with allow_missing_keys_mode(t): _ = t(data) # OK!
- monai.transforms.utils.attach_hook(func, hook, mode='pre')[source]#
Adds hook before or after a func call. If mode is “pre”, the wrapper will call hook then func. If the mode is “post”, the wrapper will call func then hook.
- monai.transforms.utils.check_boundaries(boundaries)[source]#
Check boundaries for Signal transforms
- Return type:
None
- monai.transforms.utils.check_non_lazy_pending_ops(input_array, name=None, raise_error=False)[source]#
Check whether the input array has pending operations, raise an error or warn when it has.
- Parameters:
input_array – input array to be checked.
name – an optional name to be included in the error message.
raise_error – whether to raise an error, default to False, a warning message will be issued instead.
- monai.transforms.utils.compute_divisible_spatial_size(spatial_shape, k)[source]#
Compute the target spatial size which should be divisible by k.
- Parameters:
spatial_shape – original spatial shape.
k – the target k for each spatial dimension. if k is negative or 0, the original size is preserved. if k is an int, the same k be applied to all the input spatial dimensions.
- monai.transforms.utils.convert_applied_interp_mode(trans_info, mode='nearest', align_corners=None)[source]#
Recursively change the interpolation mode in the applied operation stacks, default to “nearest”.
See also:
monai.transform.inverse.InvertibleTransform- Parameters:
trans_info – applied operation stack, tracking the previously applied invertible transform.
mode – target interpolation mode to convert, default to “nearest” as it’s usually used to save the mode output.
align_corners – target align corner value in PyTorch interpolation API, need to align with the mode.
- monai.transforms.utils.convert_pad_mode(dst, mode)[source]#
Utility to convert padding mode between numpy array and PyTorch Tensor.
- Parameters:
dst – target data to convert padding mode for, should be numpy array or PyTorch Tensor.
mode – current padding mode.
- monai.transforms.utils.convert_to_contiguous(data, **kwargs)[source]#
Check and ensure the numpy array or PyTorch Tensor in data to be contiguous in memory.
- Parameters:
data – input data to convert, will recursively convert the numpy array or PyTorch Tensor in dict and sequence.
kwargs – if x is PyTorch Tensor, additional args for torch.contiguous, more details: https://pytorch.org/docs/stable/generated/torch.Tensor.contiguous.html#torch.Tensor.contiguous.
- monai.transforms.utils.copypaste_arrays(src_shape, dest_shape, srccenter, destcenter, dims)[source]#
Calculate the slices to copy a sliced area of array in src_shape into array in dest_shape.
The area has dimensions dims (use 0 or None to copy everything in that dimension), the source area is centered at srccenter index in src and copied into area centered at destcenter in dest. The dimensions of the copied area will be clipped to fit within the source and destination arrays so a smaller area may be copied than expected. Return value is the tuples of slice objects indexing the copied area in src, and those indexing the copy area in dest.
Example
src_shape = (6,6) src = np.random.randint(0,10,src_shape) dest = np.zeros_like(src) srcslices, destslices = copypaste_arrays(src_shape, dest.shape, (3, 2),(2, 1),(3, 4)) dest[destslices] = src[srcslices] print(src) print(dest) >>> [[9 5 6 6 9 6] [4 3 5 6 1 2] [0 7 3 2 4 1] [3 0 0 1 5 1] [9 4 7 1 8 2] [6 6 5 8 6 7]] [[0 0 0 0 0 0] [7 3 2 4 0 0] [0 0 1 5 0 0] [4 7 1 8 0 0] [0 0 0 0 0 0] [0 0 0 0 0 0]]
- monai.transforms.utils.create_control_grid(spatial_shape, spacing, homogeneous=True, dtype=<class 'float'>, device=None, backend=numpy)[source]#
control grid with two additional point in each direction
- monai.transforms.utils.create_grid(spatial_size, spacing=None, homogeneous=True, dtype=<class 'float'>, device=None, backend=numpy)[source]#
compute a spatial_size mesh.
when
homogeneous=True, the output shape is (N+1, dim_size_1, dim_size_2, …, dim_size_N)when
homogeneous=False, the output shape is (N, dim_size_1, dim_size_2, …, dim_size_N)
- Parameters:
spatial_size – spatial size of the grid.
spacing – same len as
spatial_size, defaults to 1.0 (dense grid).homogeneous – whether to make homogeneous coordinates.
dtype – output grid data type, defaults to float.
device – device to compute and store the output (when the backend is “torch”).
backend – APIs to use,
numpyortorch.
- monai.transforms.utils.create_rotate(spatial_dims, radians, device=None, backend=numpy)[source]#
create a 2D or 3D rotation matrix
- Parameters:
spatial_dims – {
2,3} spatial rankradians – rotation radians when spatial_dims == 3, the radians sequence corresponds to rotation in the 1st, 2nd, and 3rd dim respectively.
device – device to compute and store the output (when the backend is “torch”).
backend – APIs to use,
numpyortorch.
- Raises:
ValueError – When
radiansis empty.ValueError – When
spatial_dimsis not one of [2, 3].
- monai.transforms.utils.create_scale(spatial_dims, scaling_factor, device=None, backend=numpy)[source]#
create a scaling matrix
- Parameters:
spatial_dims – spatial rank
scaling_factor – scaling factors for every spatial dim, defaults to 1.
device – device to compute and store the output (when the backend is “torch”).
backend – APIs to use,
numpyortorch.
- monai.transforms.utils.create_shear(spatial_dims, coefs, device=None, backend=numpy)[source]#
create a shearing matrix
- Parameters:
spatial_dims – spatial rank
coefs –
shearing factors, a tuple of 2 floats for 2D, a tuple of 6 floats for 3D), take a 3D affine as example:
[ [1.0, coefs[0], coefs[1], 0.0], [coefs[2], 1.0, coefs[3], 0.0], [coefs[4], coefs[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
device – device to compute and store the output (when the backend is “torch”).
backend – APIs to use,
numpyortorch.
- Raises:
NotImplementedError – When
spatial_dimsis not one of [2, 3].
- monai.transforms.utils.create_translate(spatial_dims, shift, device=None, backend=numpy)[source]#
create a translation matrix
- Parameters:
spatial_dims – spatial rank
shift – translate pixel/voxel for every spatial dim, defaults to 0.
device – device to compute and store the output (when the backend is “torch”).
backend – APIs to use,
numpyortorch.
- monai.transforms.utils.distance_transform_edt(img, sampling=None, return_distances=True, return_indices=False, distances=None, indices=None, *, block_params=None, float64_distances=False)[source]#
Euclidean distance transform, either GPU based with CuPy / cuCIM or CPU based with scipy. To use the GPU implementation, make sure cuCIM is available and that the data is a torch.tensor on a GPU device.
Note that the results of the libraries can differ, so stick to one if possible. For details, check out the SciPy and cuCIM documentation.
- Parameters:
img – Input image on which the distance transform shall be run. Has to be a channel first array, must have shape: (num_channels, H, W [,D]). Can be of any type but will be converted into binary: 1 wherever image equates to True, 0 elsewhere. Input gets passed channel-wise to the distance-transform, thus results from this function will differ from directly calling
distance_transform_edt()in CuPy or SciPy.sampling – Spacing of elements along each dimension. If a sequence, must be of length equal to the input rank -1; if a single number, this is used for all axes. If not specified, a grid spacing of unity is implied.
return_distances – Whether to calculate the distance transform.
return_indices – Whether to calculate the feature transform.
distances – An output array to store the calculated distance transform, instead of returning it. return_distances must be True.
indices – An output array to store the calculated feature transform, instead of returning it. return_indicies must be True.
block_params – This parameter is specific to cuCIM and does not exist in SciPy. For details, look into cuCIM.
float64_distances – This parameter is specific to cuCIM and does not exist in SciPy. If True, use double precision in the distance computation (to match SciPy behavior). Otherwise, single precision will be used for efficiency.
- Returns:
- The calculated distance transform. Returned only when return_distances is True and distances is not supplied.
It will have the same shape and type as image. For cuCIM: Will have dtype torch.float64 if float64_distances is True, otherwise it will have dtype torch.float32. For SciPy: Will have dtype np.float64.
- indices: The calculated feature transform. It has an image-shaped array for each dimension of the image.
The type will be equal to the type of the image. Returned only when return_indices is True and indices is not supplied. dtype np.float64.
- Return type:
distances
- monai.transforms.utils.equalize_hist(img, mask=None, num_bins=256, min=0, max=255)[source]#
Utility to equalize input image based on the histogram. If skimage installed, will leverage skimage.exposure.histogram, otherwise, use np.histogram instead.
- Parameters:
img – input image to equalize.
mask – if provided, must be ndarray of bools or 0s and 1s, and same shape as image. only points at which mask==True are used for the equalization.
num_bins – number of the bins to use in histogram, default to 256. for more details: https://numpy.org/doc/stable/reference/generated/numpy.histogram.html.
min – the min value to normalize input image, default to 0.
max – the max value to normalize input image, default to 255.
- monai.transforms.utils.extreme_points_to_image(points, label, sigma=0.0, rescale_min=-1.0, rescale_max=1.0)[source]#
Please refer to
monai.transforms.AddExtremePointsChannelfor the usage.Applies a gaussian filter to the extreme points image. Then the pixel values in points image are rescaled to range [rescale_min, rescale_max].
- Parameters:
points – Extreme points of the object/organ.
label – label image to get extreme points from. Shape must be (1, spatial_dim1, [, spatial_dim2, …]). Doesn’t support one-hot labels.
sigma – if a list of values, must match the count of spatial dimensions of input data, and apply every value in the list to 1 spatial dimension. if only 1 value provided, use it for all spatial dimensions.
rescale_min – minimum value of output data.
rescale_max – maximum value of output data.
- monai.transforms.utils.fill_holes(img_arr, applied_labels=None, connectivity=None)[source]#
Fill the holes in the provided image.
The label 0 will be treated as background and the enclosed holes will be set to the neighboring class label. What is considered to be an enclosed hole is defined by the connectivity. Holes on the edge are always considered to be open (not enclosed).
Note
The performance of this method heavily depends on the number of labels. It is a bit faster if the list of applied_labels is provided. Limiting the number of applied_labels results in a big decrease in processing time.
If the image is one-hot-encoded, then the applied_labels need to match the channel index.
- Parameters:
img_arr – numpy array of shape [C, spatial_dim1[, spatial_dim2, …]].
applied_labels – Labels for which to fill holes. Defaults to None, that is filling holes for all labels.
connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. Defaults to a full connectivity of
input.ndim.
- Returns:
numpy array of shape [C, spatial_dim1[, spatial_dim2, …]].
- monai.transforms.utils.generate_label_classes_crop_centers(spatial_size, num_samples, label_spatial_shape, indices, ratios=None, rand_state=None, allow_smaller=False, warn=True)[source]#
Generate valid sample locations based on the specified ratios of label classes. Valid: samples sitting entirely within image, expected input shape: [C, H, W, D] or [C, H, W]
- Parameters:
spatial_size – spatial size of the ROIs to be sampled.
num_samples – total sample centers to be generated.
label_spatial_shape – spatial shape of the original label data to unravel selected centers.
indices – sequence of pre-computed foreground indices of every class in 1 dimension.
ratios – ratios of every class in the label to generate crop centers, including background class. if None, every class will have the same ratio to generate crop centers.
rand_state – numpy randomState object to align with other modules.
allow_smaller – if False, an exception will be raised if the image is smaller than the requested ROI in any dimension. If True, any smaller dimensions will be set to match the cropped size (i.e., no cropping in that dimension).
warn – if True prints a warning if a class is not present in the label.
- monai.transforms.utils.generate_pos_neg_label_crop_centers(spatial_size, num_samples, pos_ratio, label_spatial_shape, fg_indices, bg_indices, rand_state=None, allow_smaller=False)[source]#
Generate valid sample locations based on the label with option for specifying foreground ratio Valid: samples sitting entirely within image, expected input shape: [C, H, W, D] or [C, H, W]
- Parameters:
spatial_size – spatial size of the ROIs to be sampled.
num_samples – total sample centers to be generated.
pos_ratio – ratio of total locations generated that have center being foreground.
label_spatial_shape – spatial shape of the original label data to unravel selected centers.
fg_indices – pre-computed foreground indices in 1 dimension.
bg_indices – pre-computed background indices in 1 dimension.
rand_state – numpy randomState object to align with other modules.
allow_smaller – if False, an exception will be raised if the image is smaller than the requested ROI in any dimension. If True, any smaller dimensions will be set to match the cropped size (i.e., no cropping in that dimension).
- Raises:
ValueError – When the proposed roi is larger than the image.
ValueError – When the foreground and background indices lengths are 0.
- monai.transforms.utils.generate_spatial_bounding_box(img, select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True)[source]#
Generate the spatial bounding box of foreground in the image with start-end positions (inclusive). Users can define arbitrary function to select expected foreground from the whole image or specified channels. And it can also add margin to every dim of the bounding box. The output format of the coordinates is:
[1st_spatial_dim_start, 2nd_spatial_dim_start, …, Nth_spatial_dim_start], [1st_spatial_dim_end, 2nd_spatial_dim_end, …, Nth_spatial_dim_end]
This function returns [0, 0, …], [0, 0, …] if there’s no positive intensity.
- Parameters:
img – a “channel-first” image of shape (C, spatial_dim1[, spatial_dim2, …]) to generate bounding box from.
select_fn – function to select expected foreground, default is to select values > 0.
channel_indices – if defined, select foreground only on the specified channels of image. if None, select foreground on the whole image.
margin – add margin value to spatial dims of the bounding box, if only 1 value provided, use it for all dims.
allow_smaller – when computing box size with margin, whether to allow the image edges to be smaller than the final box edges. If True, the bounding boxes edges are aligned with the input image edges, if False, the bounding boxes edges are aligned with the final box edges. Default to True.
- monai.transforms.utils.get_extreme_points(img, rand_state=None, background=0, pert=0.0)[source]#
Generate extreme points from an image. These are used to generate initial segmentation for annotation models. An optional perturbation can be passed to simulate user clicks.
- Parameters:
img – Image to generate extreme points from. Expected Shape is
(spatial_dim1, [, spatial_dim2, ...]).rand_state – np.random.RandomState object used to select random indices.
background – Value to be consider as background, defaults to 0.
pert – Random perturbation amount to add to the points, defaults to 0.0.
- Returns:
A list of extreme points, its length is equal to 2 * spatial dimension of input image. The output format of the coordinates is:
[1st_spatial_dim_min, 1st_spatial_dim_max, 2nd_spatial_dim_min, …, Nth_spatial_dim_max]
- Raises:
ValueError – When the input image does not have any foreground pixel.
- monai.transforms.utils.get_largest_connected_component_mask(img, connectivity=None, num_components=1)[source]#
Gets the largest connected component mask of an image.
- Parameters:
img – Image to get largest connected component from. Shape is (spatial_dim1 [, spatial_dim2, …])
connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. If
None, a full connectivity ofinput.ndimis used. for more details: https://scikit-image.org/docs/dev/api/skimage.measure.html#skimage.measure.label.num_components – The number of largest components to preserve.
- monai.transforms.utils.get_number_image_type_conversions(transform, test_data, key=None)[source]#
Get the number of times that the data need to be converted (e.g., numpy to torch). Conversions between different devices are also counted (e.g., CPU to GPU).
- Parameters:
transform – composed transforms to be tested
test_data – data to be used to count the number of conversions
key – if using dictionary transforms, this key will be used to check the number of conversions.
- monai.transforms.utils.get_transform_backends()[source]#
Get the backends of all MONAI transforms.
- Returns:
Dictionary, where each key is a transform, and its corresponding values are a boolean list, stating whether that transform supports (1) torch.Tensor, and (2) np.ndarray as input without needing to convert.
- monai.transforms.utils.get_unique_labels(img, is_onehot, discard=None)[source]#
Get list of non-background labels in an image.
- Parameters:
img – Image to be processed. Shape should be [C, W, H, [D]] with C=1 if not onehot else num_classes.
is_onehot – Boolean as to whether input image is one-hotted. If one-hotted, only return channels with
discard – Can be used to remove labels (e.g., background). Can be any value, sequence of values, or None (nothing is discarded).
- Returns:
Set of labels
- monai.transforms.utils.has_status_keys(data, status_key, default_message='No message provided')[source]#
Checks whether a given tensor is has a particular status key message on any of its applied operations. If it doesn’t, it returns the tuple (False, None). If it does it returns a tuple of True and a list of status messages for that status key.
Status keys are defined in
TraceStatusKeys.This function also accepts:
dictionaries of tensors
lists or tuples of tensors
list or tuples of dictionaries of tensors
In any of the above scenarios, it iterates through the collections and executes itself recursively until it is operating on tensors.
- Parameters:
data (
Tensor) – a torch.Tensor or MetaTensor or collections of torch.Tensor or MetaTensor, as described abovestatus_key (
Any) – the status key to look for, from TraceStatusKeysdefault_message (
str) – a default message to use if the status key entry doesn’t have a message set
- Returns:
A tuple. The first entry is False or True. The second entry is the status messages that can be used for the user to help debug their pipelines.
- monai.transforms.utils.img_bounds(img)[source]#
Returns the minimum and maximum indices of non-zero lines in axis 0 of img, followed by that for axis 1.
- monai.transforms.utils.in_bounds(x, y, margin, maxx, maxy)[source]#
Returns True if (x,y) is within the rectangle (margin, margin, maxx-margin, maxy-margin).
- Return type:
bool
- monai.transforms.utils.is_empty(img)[source]#
Returns True if img is empty, that is its maximum value is not greater than its minimum.
- monai.transforms.utils.is_positive(img)[source]#
Returns a boolean version of img where the positive values are converted into True, the other values are False.
- monai.transforms.utils.map_binary_to_indices(label, image=None, image_threshold=0.0)[source]#
Compute the foreground and background of input label data, return the indices after fattening. For example:
label = np.array([[[0, 1, 1], [1, 0, 1], [1, 1, 0]]])foreground indices = np.array([1, 2, 3, 5, 6, 7])andbackground indices = np.array([0, 4, 8])- Parameters:
label – use the label data to get the foreground/background information.
image – if image is not None, use
label = 0 & image > image_thresholdto define background. so the output items will not map to all the voxels in the label.image_threshold – if enabled image, use
image > image_thresholdto determine the valid image content area and select background only in this area.
- monai.transforms.utils.map_classes_to_indices(label, num_classes=None, image=None, image_threshold=0.0, max_samples_per_class=None)[source]#
Filter out indices of every class of the input label data, return the indices after fattening. It can handle both One-Hot format label and Argmax format label, must provide num_classes for Argmax label.
For example:
label = np.array([[[0, 1, 2], [2, 0, 1], [1, 2, 0]]])and num_classes=3, will return a list which contains the indices of the 3 classes:[np.array([0, 4, 8]), np.array([1, 5, 6]), np.array([2, 3, 7])]- Parameters:
label – use the label data to get the indices of every class.
num_classes – number of classes for argmax label, not necessary for One-Hot label.
image – if image is not None, only return the indices of every class that are within the valid region of the image (
image > image_threshold).image_threshold – if enabled image, use
image > image_thresholdto determine the valid image content area and select class indices only in this area.max_samples_per_class – maximum length of indices in each class to reduce memory consumption. Default is None, no subsampling.
- monai.transforms.utils.map_spatial_axes(img_ndim, spatial_axes=None, channel_first=True)[source]#
Utility to map the spatial axes to real axes in channel first/last shape. For example: If channel_first is True, and img has 3 spatial dims, map spatial axes to real axes as below: None -> [1, 2, 3] [0, 1] -> [1, 2] [0, -1] -> [1, -1] If channel_first is False, and img has 3 spatial dims, map spatial axes to real axes as below: None -> [0, 1, 2] [0, 1] -> [0, 1] [0, -1] -> [0, -2]
- Parameters:
img_ndim – dimension number of the target image.
spatial_axes – spatial axes to be converted, default is None. The default None will convert to all the spatial axes of the image. If axis is negative it counts from the last to the first axis. If axis is a tuple of ints.
channel_first – the image data is channel first or channel last, default to channel first.
- monai.transforms.utils.print_transform_backends()[source]#
Prints a list of backends of all MONAI transforms.
- monai.transforms.utils.rand_choice(prob=0.5)[source]#
Returns True if a randomly chosen number is less than or equal to prob, by default this is a 50/50 chance.
- Return type:
bool
- monai.transforms.utils.remove_small_objects(img, min_size=64, connectivity=1, independent_channels=True, by_measure=False, pixdim=None)[source]#
Use skimage.morphology.remove_small_objects to remove small objects from images. See: https://scikit-image.org/docs/dev/api/skimage.morphology.html#remove-small-objects.
Data should be one-hotted.
- Parameters:
img – image to process. Expected shape: C, H,W,[D]. Expected to only have singleton channel dimension, i.e., not be one-hotted. Converted to type int.
min_size – objects smaller than this size are removed.
connectivity – Maximum number of orthogonal hops to consider a pixel/voxel as a neighbor. Accepted values are ranging from 1 to input.ndim. If
None, a full connectivity ofinput.ndimis used. For more details refer to linked scikit-image documentation.independent_channels – Whether to consider each channel independently.
by_measure – Whether the specified min_size is in number of voxels. if this is True then min_size represents a surface area or volume value of whatever units your image is in (mm^3, cm^2, etc.) default is False.
pixdim – the pixdim of the input image. if a single number, this is used for all axes. If a sequence of numbers, the length of the sequence must be equal to the image dimensions.
- monai.transforms.utils.rescale_array(arr, minv=0.0, maxv=1.0, dtype=<class 'numpy.float32'>)[source]#
Rescale the values of numpy array arr to be from minv to maxv. If either minv or maxv is None, it returns (a - min_a) / (max_a - min_a).
- Parameters:
arr – input array to rescale.
minv – minimum value of target rescaled array.
maxv – maximum value of target rescaled array.
dtype – if not None, convert input array to dtype before computation.
- monai.transforms.utils.rescale_array_int_max(arr, dtype=<class 'numpy.uint16'>)[source]#
Rescale the array arr to be between the minimum and maximum values of the type dtype.
- Return type:
ndarray
- monai.transforms.utils.rescale_instance_array(arr, minv=0.0, maxv=1.0, dtype=<class 'numpy.float32'>)[source]#
Rescale each array slice along the first dimension of arr independently.
- monai.transforms.utils.reset_ops_id(data)[source]#
find MetaTensors in list or dict data and (in-place) set
TraceKeys.IDtoTracekeys.NONE.
- monai.transforms.utils.resize_center(img, *resize_dims, fill_value=0.0, inplace=True)[source]#
Resize img by cropping or expanding the image from the center. The resize_dims values are the output dimensions (or None to use original dimension of img). If a dimension is smaller than that of img then the result will be cropped and if larger padded with zeros, in both cases this is done relative to the center of img. The result is a new image with the specified dimensions and values from img copied into its center.
- monai.transforms.utils.resolves_modes(interp_mode='constant', padding_mode='zeros', backend=torch, **kwargs)[source]#
Automatically adjust the resampling interpolation mode and padding mode, so that they are compatible with the corresponding API of the backend. Depending on the availability of the backends, when there’s no exact equivalent, a similar mode is returned.
- Parameters:
interp_mode – interpolation mode.
padding_mode – padding mode.
backend – optional backend of TransformBackends. If None, the backend will be decided from interp_mode.
kwargs – additional keyword arguments. currently support
torch_interpolate_spatial_nd, to provide additional information to determinelinear,bilinearandtrilinear;use_compiledto use MONAI’s precompiled backend (pytorch c++ extensions), default toFalse.
- monai.transforms.utils.scale_affine(spatial_size, new_spatial_size, centered=True)[source]#
Compute the scaling matrix according to the new spatial size
- Parameters:
spatial_size – original spatial size.
new_spatial_size – new spatial size.
centered (
bool) – whether the scaling is with respect to the image center (True, default) or corner (False).
- Returns:
the scaling matrix.
- monai.transforms.utils.soft_clip(arr, sharpness_factor=1.0, minv=None, maxv=None, dtype=<class 'numpy.float32'>)[source]#
Apply soft clip to the input array or tensor. The intensity values will be soft clipped according to f(x) = x + (1/sharpness_factor)*softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv)) From https://medium.com/life-at-hopper/clip-it-clip-it-good-1f1bf711b291
To perform one-sided clipping, set either minv or maxv to None. :param arr: input array to clip. :param sharpness_factor: the sharpness of the soft clip function, default to 1. :param minv: minimum value of target clipped array. :param maxv: maximum value of target clipped array. :param dtype: if not None, convert input array to dtype before computation.
- monai.transforms.utils.sync_meta_info(key, data_dict, t=True)[source]#
Given the key, sync up between metatensor data_dict[key] and meta_dict data_dict[key_transforms/meta_dict]. t=True: the one with more applied_operations in metatensor vs meta_dict is the output, False: less is the output.
- monai.transforms.utils.weighted_patch_samples(spatial_size, w, n_samples=1, r_state=None)[source]#
Computes n_samples of random patch sampling locations, given the sampling weight map w and patch spatial_size.
- Parameters:
spatial_size – length of each spatial dimension of the patch.
w – weight map, the weights must be non-negative. each element denotes a sampling weight of the spatial location. 0 indicates no sampling. The weight map shape is assumed
(spatial_dim_0, spatial_dim_1, ..., spatial_dim_n).n_samples – number of patch samples
r_state – a random state container
- Returns:
a list of n_samples N-D integers representing the spatial sampling location of patches.
- monai.transforms.utils.zero_margins(img, margin)[source]#
Returns True if the values within margin indices of the edges of img in dimensions 1 and 2 are 0.
- Return type:
bool
- monai.transforms.utils_pytorch_numpy_unification.allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False)[source]#
np.allclose with equivalent implementation for torch.
- Return type:
bool
- monai.transforms.utils_pytorch_numpy_unification.any_np_pt(x, axis)[source]#
np.any with equivalent implementation for torch.
For pytorch, convert to boolean for compatibility with older versions.
- Parameters:
x – input array/tensor.
axis – axis to perform any over.
- Returns:
Return a contiguous flattened array/tensor.
- monai.transforms.utils_pytorch_numpy_unification.argsort(a, axis=-1)[source]#
np.argsort with equivalent implementation for torch.
- Parameters:
a – the array/tensor to sort.
axis – axis along which to sort.
- Returns:
Array/Tensor of indices that sort a along the specified axis.
- monai.transforms.utils_pytorch_numpy_unification.argwhere(a)[source]#
np.argwhere with equivalent implementation for torch.
- Parameters:
a (~NdarrayTensor) – input data.
- Return type:
~NdarrayTensor
- Returns:
Indices of elements that are non-zero. Indices are grouped by element. This array will have shape (N, a.ndim) where N is the number of non-zero items.
- monai.transforms.utils_pytorch_numpy_unification.ascontiguousarray(x, **kwargs)[source]#
np.ascontiguousarray with equivalent implementation for torch (contiguous).
- Parameters:
x – array/tensor.
kwargs – if x is PyTorch Tensor, additional args for torch.contiguous, more details: https://pytorch.org/docs/stable/generated/torch.Tensor.contiguous.html.
- monai.transforms.utils_pytorch_numpy_unification.clip(a, a_min, a_max)[source]#
np.clip with equivalent implementation for torch.
- Return type:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.concatenate(to_cat, axis=0, out=None)[source]#
np.concatenate with equivalent implementation for torch (torch.cat).
- Return type:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.cumsum(a, axis=None, **kwargs)[source]#
np.cumsum with equivalent implementation for torch.
- Parameters:
a (
Union[ndarray,Tensor]) – input data to compute cumsum.axis – expected axis to compute cumsum.
kwargs – if a is PyTorch Tensor, additional args for torch.cumsum, more details: https://pytorch.org/docs/stable/generated/torch.cumsum.html.
- Return type:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.floor_divide(a, b)[source]#
np.floor_divide with equivalent implementation for torch.
As of pt1.8, use torch.div(…, rounding_mode=”floor”), and before that, use torch.floor_divide.
- Parameters:
a (
Union[ndarray,Tensor]) – first array/tensorb – scalar to divide by
- Return type:
Union[ndarray,Tensor]- Returns:
Element-wise floor division between two arrays/tensors.
- monai.transforms.utils_pytorch_numpy_unification.in1d(x, y)[source]#
np.in1d with equivalent implementation for torch.
- monai.transforms.utils_pytorch_numpy_unification.isfinite(x)[source]#
np.isfinite with equivalent implementation for torch.
- Return type:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.isnan(x)[source]#
np.isnan with equivalent implementation for torch.
- Parameters:
x (
Union[ndarray,Tensor]) – array/tensor.- Return type:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.max(x, dim=None, **kwargs)[source]#
torch.max with equivalent implementation for numpy
- Parameters:
x – array/tensor.
- Returns:
the maximum of x.
- monai.transforms.utils_pytorch_numpy_unification.maximum(a, b)[source]#
np.maximum with equivalent implementation for torch.
- Parameters:
a (
Union[ndarray,Tensor]) – first array/tensor.b (
Union[ndarray,Tensor]) – second array/tensor.
- Return type:
Union[ndarray,Tensor]- Returns:
Element-wise maximum between two arrays/tensors.
- monai.transforms.utils_pytorch_numpy_unification.mean(x, dim=None, **kwargs)[source]#
torch.mean with equivalent implementation for numpy
- Parameters:
x – array/tensor.
- Returns:
the mean of x
- monai.transforms.utils_pytorch_numpy_unification.median(x, dim=None, **kwargs)[source]#
torch.median with equivalent implementation for numpy
- Parameters:
x – array/tensor.
- Returns
the median of x.
- monai.transforms.utils_pytorch_numpy_unification.min(x, dim=None, **kwargs)[source]#
torch.min with equivalent implementation for numpy
- Parameters:
x – array/tensor.
- Returns:
the minimum of x.
- monai.transforms.utils_pytorch_numpy_unification.mode(x, dim=-1, to_long=True)[source]#
torch.mode with equivalent implementation for numpy.
- Parameters:
x (~NdarrayTensor) – array/tensor.
dim (
int) – dimension along which to perform mode (referred to as axis by numpy).to_long (
bool) – convert input to long before performing mode.
- Return type:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.moveaxis(x, src, dst)[source]#
moveaxis for pytorch and numpy
- monai.transforms.utils_pytorch_numpy_unification.nonzero(x)[source]#
np.nonzero with equivalent implementation for torch.
- Parameters:
x (
Union[ndarray,Tensor]) – array/tensor.- Return type:
Union[ndarray,Tensor]- Returns:
Index unravelled for given shape
- monai.transforms.utils_pytorch_numpy_unification.percentile(x, q, dim=None, keepdim=False, **kwargs)[source]#
np.percentile with equivalent implementation for torch.
Pytorch uses quantile. For more details please refer to: https://pytorch.org/docs/stable/generated/torch.quantile.html. https://numpy.org/doc/stable/reference/generated/numpy.percentile.html.
- Parameters:
x – input data.
q – percentile to compute (should in range 0 <= q <= 100).
dim – the dim along which the percentiles are computed. default is to compute the percentile along a flattened version of the array.
keepdim – whether the output data has dim retained or not.
kwargs – if x is numpy array, additional args for np.percentile, more details: https://numpy.org/doc/stable/reference/generated/numpy.percentile.html.
- Returns:
Resulting value (scalar)
- monai.transforms.utils_pytorch_numpy_unification.ravel(x)[source]#
np.ravel with equivalent implementation for torch.
- Parameters:
x (
Union[ndarray,Tensor]) – array/tensor to ravel.- Return type:
Union[ndarray,Tensor]- Returns:
Return a contiguous flattened array/tensor.
- monai.transforms.utils_pytorch_numpy_unification.repeat(a, repeats, axis=None, **kwargs)[source]#
np.repeat with equivalent implementation for torch (repeat_interleave).
- Parameters:
a – input data to repeat.
repeats – number of repetitions for each element, repeats is broadcast to fit the shape of the given axis.
axis – axis along which to repeat values.
kwargs – if a is PyTorch Tensor, additional args for torch.repeat_interleave, more details: https://pytorch.org/docs/stable/generated/torch.repeat_interleave.html.
- monai.transforms.utils_pytorch_numpy_unification.searchsorted(a, v, right=False, sorter=None, **kwargs)[source]#
np.searchsorted with equivalent implementation for torch.
- Parameters:
a (~NdarrayTensor) – numpy array or tensor, containing monotonically increasing sequence on the innermost dimension.
v (
Union[ndarray,Tensor]) – containing the search values.right – if False, return the first suitable location that is found, if True, return the last such index.
sorter – if a is numpy array, optional array of integer indices that sort array a into ascending order.
kwargs – if a is PyTorch Tensor, additional args for torch.searchsorted, more details: https://pytorch.org/docs/stable/generated/torch.searchsorted.html.
- Return type:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.softplus(x)[source]#
stable softplus through np.logaddexp with equivalent implementation for torch.
- Parameters:
x (
Union[ndarray,Tensor]) – array/tensor.- Return type:
Union[ndarray,Tensor]- Returns:
Softplus of the input.
- monai.transforms.utils_pytorch_numpy_unification.stack(x, dim)[source]#
np.stack with equivalent implementation for torch.
- Parameters:
x (
Sequence[~NdarrayTensor]) – array/tensor.dim (
int) – dimension along which to perform the stack (referred to as axis by numpy).
- Return type:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.std(x, dim=None, unbiased=False)[source]#
torch.std with equivalent implementation for numpy
- Parameters:
x – array/tensor.
- Returns:
the standard deviation of x.
- monai.transforms.utils_pytorch_numpy_unification.unique(x, **kwargs)[source]#
torch.unique with equivalent implementation for numpy.
- Parameters:
x (~NdarrayTensor) – array/tensor.
- Return type:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.unravel_index(idx, shape)[source]#
np.unravel_index with equivalent implementation for torch.
- Parameters:
idx – index to unravel.
shape – shape of array/tensor.
- Return type:
Union[ndarray,Tensor]- Returns:
Index unravelled for given shape
- monai.transforms.utils_pytorch_numpy_unification.unravel_indices(idx, shape)[source]#
Computing unravel coordinates from indices.
- Parameters:
idx – a sequence of indices to unravel.
shape – shape of array/tensor.
- Return type:
Union[ndarray,Tensor]- Returns:
Stacked indices unravelled for given shape