Precision and Accelerating#
Modern GPU architectures usually can use reduced precision tensor data or computational operations to save memory and increase throughput. However, in some cases, the reduced precision will cause numerical stability issues, and further cause reproducibility issues. Therefore, please ensure that you are using appropriate precision.
TensorFloat-32 (TF32)#
Introduction#
NVIDIA introduced a new math mode TensorFloat-32 (TF32) for NVIDIA Ampere GPUs and above, see Accelerating AI Training with NVIDIA TF32 Tensor Cores, TRAINING NEURAL NETWORKS WITH TENSOR CORES, CUDA 11 and Ampere architecture.
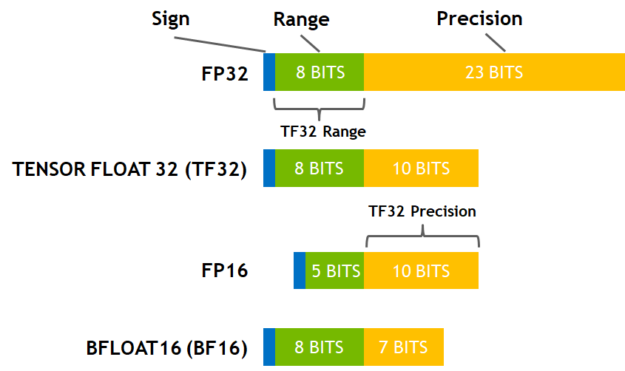
TF32 adopts 8 exponent bits, 10 bits of mantissa, and one sign bit.
Potential Impact#
Although NVIDIA has shown that TF32 mode can reach the same accuracy and convergence as float32 for most AI workloads, some users still find some significant effect on their applications, see PyTorch and TensorFloat32. Users who need high-precision matrix operation, such as traditional computer graphics operation and kernel method, may be affected by TF32 precision.
Note that all operations that use cuda.matmul may be affected
by TF32 mode so the impact is very wide.
Settings#
PyTorch TF32 default value:
torch.backends.cuda.matmul.allow_tf32 = False # in PyTorch 1.12 and later.
torch.backends.cudnn.allow_tf32 = True
Please note that there are environment variables that can override the flags above. For example, the environment variable NVIDIA_TF32_OVERRIDE mentioned in Accelerating AI Training with NVIDIA TF32 Tensor Cores and TORCH_ALLOW_TF32_CUBLAS_OVERRIDE used by PyTorch. Thus, in some cases, the flags may be accidentally changed or overridden.
If you are using an NGC PyTorch container, the container includes a layer ENV TORCH_ALLOW_TF32_CUBLAS_OVERRIDE=1.
The default value torch.backends.cuda.matmul.allow_tf32 will be overridden to True.
To restore the upstream default value, please run unset TORCH_ALLOW_TF32_CUBLAS_OVERRIDE in the container,
and use the Pytorch API torch.set_float32_matmul_precision, torch.backends.cudnn.allow_tf32=False accordingly.
We recommend that users print out these two flags for confirmation when unsure.
If you can confirm through experiments that your model has no accuracy or convergence issues in TF32 mode and you have NVIDIA Ampere GPUs or above, you can set the two flags above to True to speed up your model.