Modules in v0.3.0¶
MONAI aims at supporting deep learning in medical image analysis at multiple granularities.
This figure shows a typical example of the end-to-end workflow in medical deep learning area:
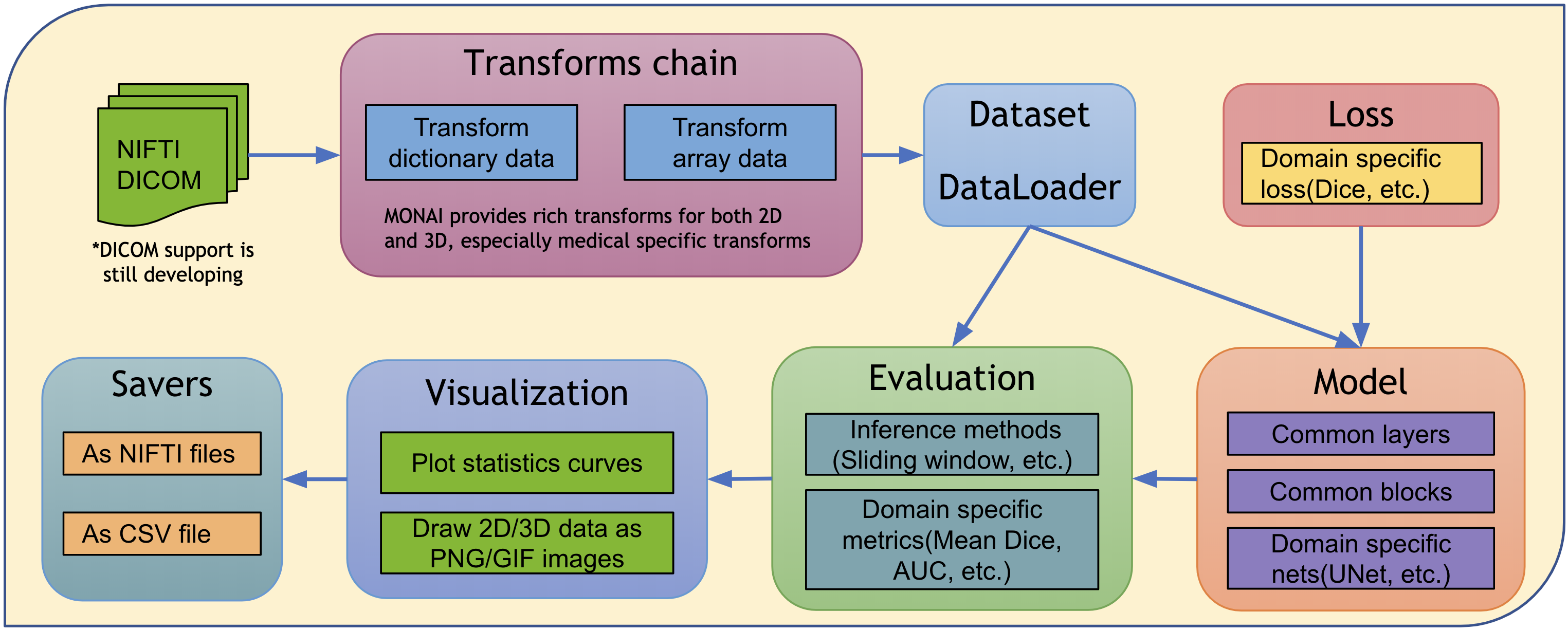
MONAI architecture¶
The design principle of MONAI is to provide flexible and light APIs for users with varying expertise.
All the core components are independent modules, which can be easily integrated into any existing PyTorch programs.
Users can leverage the workflows in MONAI to quickly set up a robust training or evaluation program for research experiments.
Rich examples and demos are provided to demonstrate the key features.
Researchers contribute implementations based on the state-of-the-art for the latest research challenges, including COVID-19 image analysis, Model Parallel, etc.
The overall architecture and modules are shown in the following figure:
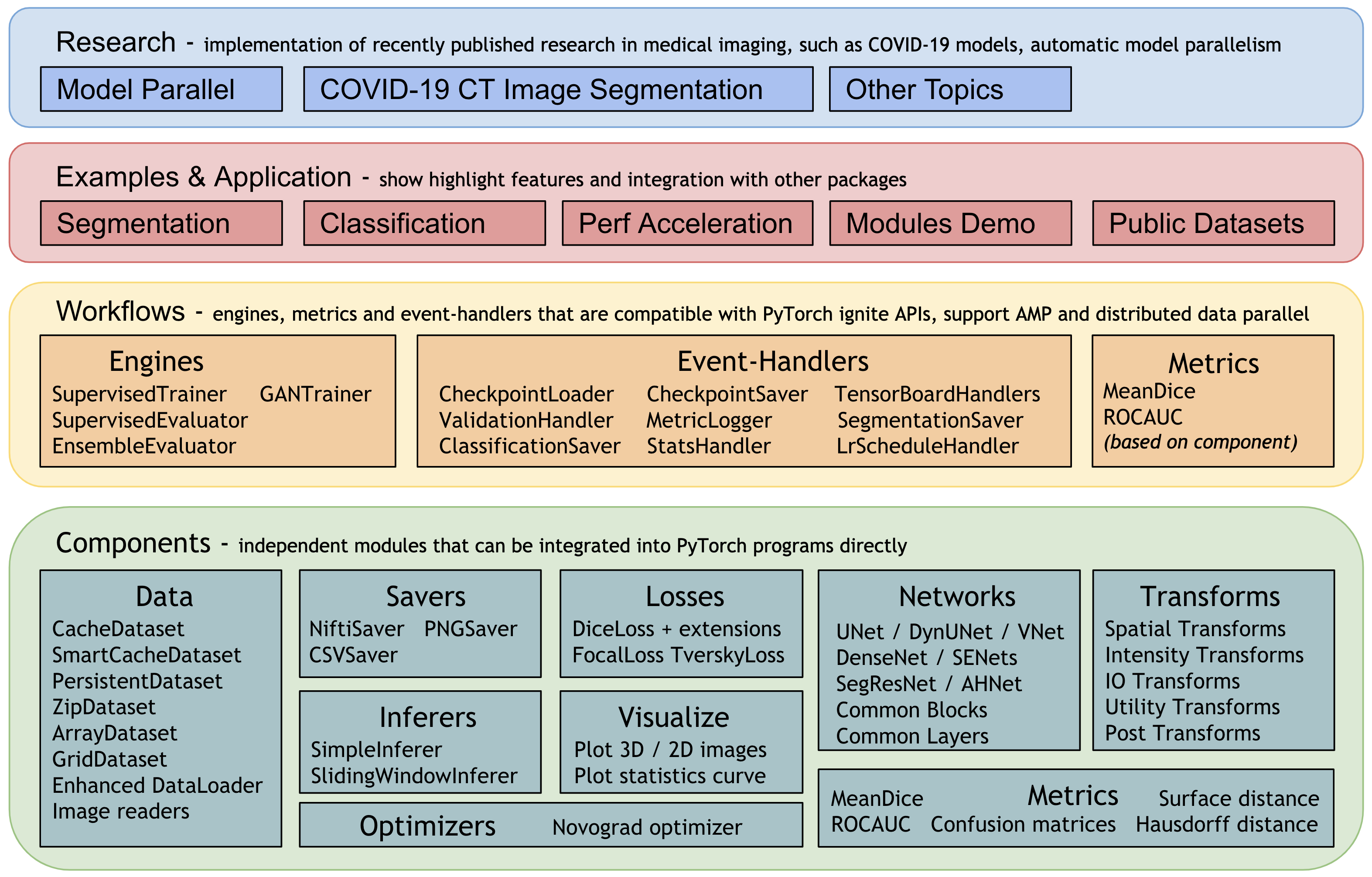 The rest of this page provides more details for each module.
The rest of this page provides more details for each module.
Medical image data I/O, processing and augmentation¶
Medical images require highly specialized methods for I/O, preprocessing, and augmentation. Medical images are often in specialized formats with rich meta-information, and the data volumes are often high-dimensional. These require carefully designed manipulation procedures. The medical imaging focus of MONAI is enabled by powerful and flexible image transformations that facilitate user-friendly, reproducible, optimized medical data pre-processing pipelines.
1. Transforms support both Dictionary and Array format data¶
The widely used computer vision packages (such as
torchvision) focus on spatially 2D array image processing. MONAI provides more domain-specific transformations for both spatially 2D and 3D and retains the flexible transformation “compose” feature.As medical image preprocessing often requires additional fine-grained system parameters, MONAI provides transforms for input data encapsulated in python dictionaries. Users can specify the keys corresponding to the expected data fields and system parameters to compose complex transformations.
There is a rich set of transforms in six categories: Crop & Pad, Intensity, IO, Post-processing, Spatial, and Utilities. For more details, please visit all the transforms in MONAI.
2. Medical specific transforms¶
MONAI aims at providing a comprehensive medical image specific transformations. These currently include, for example:
LoadNifti: Load Nifti format file from provided pathSpacing: Resample input image into the specifiedpixdimOrientation: Change the image’s orientation into the specifiedaxcodesRandGaussianNoise: Perturb image intensities by adding statistical noisesNormalizeIntensity: Intensity Normalization based on mean and standard deviationAffine: Transform image based on the affine parametersRand2DElastic: Random elastic deformation and affine in 2DRand3DElastic: Random elastic deformation and affine in 3D
2D transforms tutorial shows the detailed usage of several MONAI medical image specific transforms.

3. Fused spatial transforms and GPU acceleration¶
As medical image volumes are usually large (in multi-dimensional arrays), pre-processing performance affects the overall pipeline speed. MONAI provides affine transforms to execute fused spatial operations, supports GPU acceleration via native PyTorch for high performance.
For example:
# create an Affine transform
affine = Affine(
rotate_params=np.pi/4,
scale_params=(1.2, 1.2),
translate_params=(200, 40),
padding_mode='zeros',
device=torch.device('cuda:0')
)
# convert the image using bilinear interpolation
new_img = affine(image, spatial_size=(300, 400), mode='bilinear')
Experiments and test results are available at Fused transforms test.
Currently all the geometric image transforms (Spacing, Zoom, Rotate, Resize, etc.) are designed based on the PyTorch native interfaces. Geometric transforms tutorial indicates the usage of affine transforms with 3D medical images.

4. Randomly crop out batch images based on positive/negative ratio¶
Medical image data volume may be too large to fit into GPU memory. A widely-used approach is to randomly draw small size data samples during training and run a “sliding window” routine for inference. MONAI currently provides general random sampling strategies including class-balanced fixed ratio sampling which may help stabilize the patch-based training process. A typical example is in Spleen 3D segmentation tutorial, which achieves the class-balanced sampling with RandCropByPosNegLabel transform.
5. Deterministic training for reproducibility¶
Deterministic training support is necessary and important for deep learning research, especially in the medical field. Users can easily set the random seed to all the random transforms in MONAI locally and will not affect other non-deterministic modules in the user’s program.
For example:
# define a transform chain for pre-processing
train_transforms = monai.transforms.Compose([
LoadNiftid(keys=['image', 'label']),
RandRotate90d(keys=['image', 'label'], prob=0.2, spatial_axes=[0, 2]),
... ...
])
# set determinism for reproducibility
train_transforms.set_random_state(seed=0)
Users can also enable/disable deterministic at the beginning of training program:
monai.utils.set_determinism(seed=0, additional_settings=None)
6. Multiple transform chains¶
To apply different transforms on the same data and concatenate the results, MONAI provides CopyItems transform to make copies of specified items in the data dictionary and ConcatItems transform to combine specified items on the expected dimension, and also provides DeleteItems transform to delete unnecessary items to save memory.
Typical usage is to scale the intensity of the same image into different ranges and concatenate the results together.
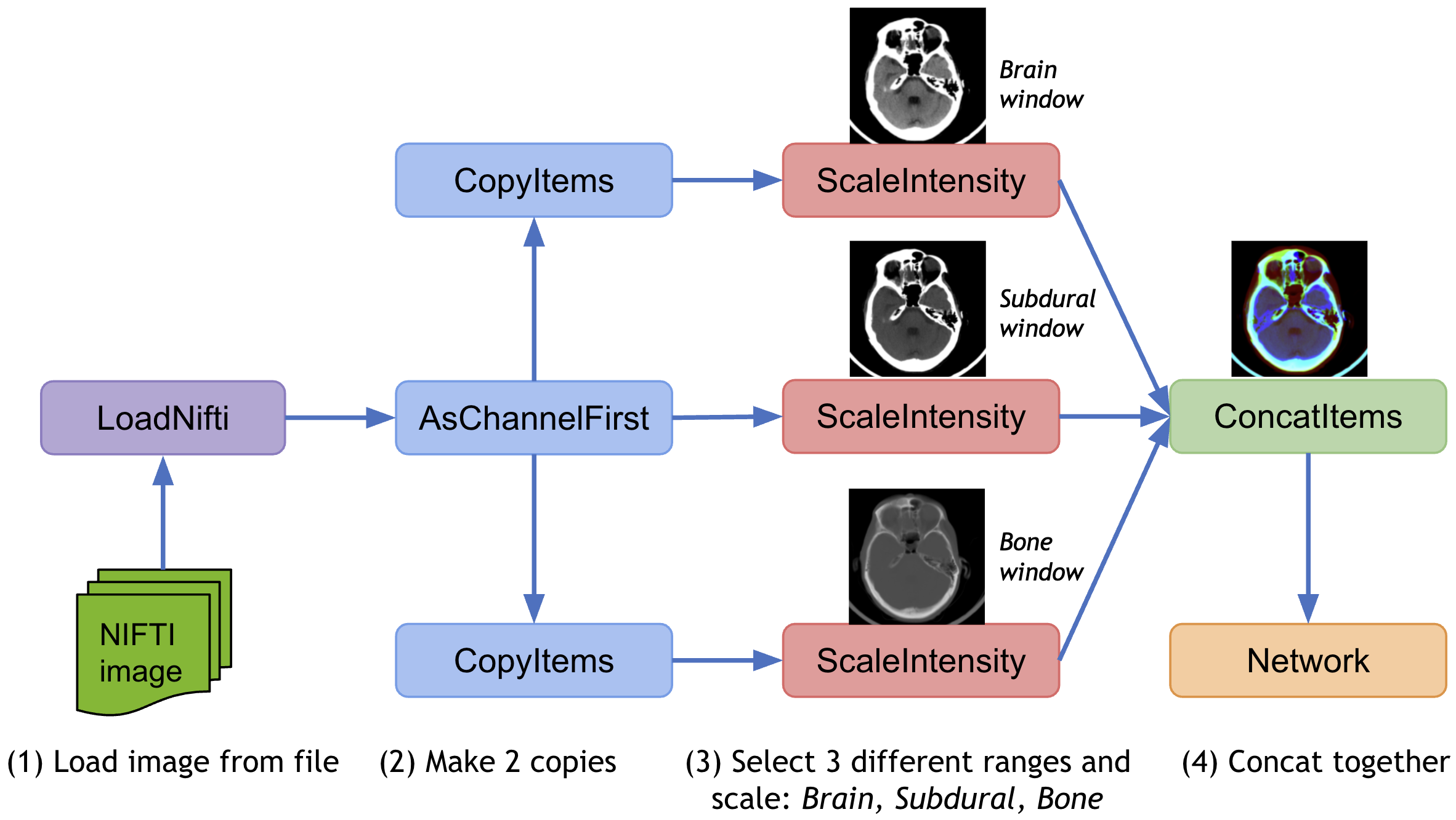
7. Debug transforms with DataStats¶
When transforms are combined with the “compose” function, it’s not easy to track the output of specific transform. To help debug errors in the composed transforms, MONAI provides utility transforms such as DataStats to print out intermediate data properties such as data shape, value range, data value, Additional information, etc. It’s a self-contained transform and can be integrated into any transform chain.
8. Post-processing transforms for model output¶
MONAI also provides post-processing transforms for handling the model outputs. Currently, the transforms include:
Adding activation layer (Sigmoid, Softmax, etc.).
Converting to discrete values (Argmax, One-Hot, Threshold value, etc), as below figure (b).
Splitting multi-channel data into multiple single channels.
Removing segmentation noise based on Connected Component Analysis, as below figure (c).
Extracting contour of segmentation result, which can be used to map to original image and evaluate the model, as below figure (d) and (e).
After applying the post-processing transforms, it’s easier to compute metrics, save model output into files or visualize data in the TensorBoard. Post transforms tutorial shows an example with several main post transforms.
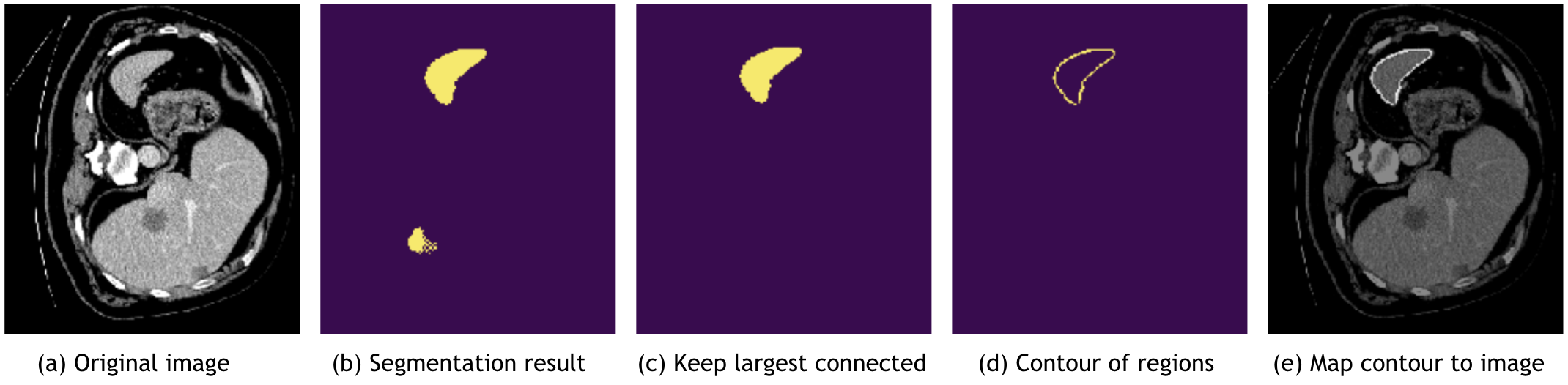
9. Integrate third-party transforms¶
The design of MONAI transforms emphasis code readability and usability. It works for array data or dictionary-based data. MONAI also provides Adaptor tools to accommodate different data format for 3rd party transforms. To convert the data shapes or types, utility transforms such as ToTensor, ToNumpy, SqueezeDim are also provided. So it’s easy to enhance the transform chain by seamlessly integrating transforms from external packages, including: ITK, BatchGenerator, TorchIO and Rising.
For more details, please check out the tutorial: integrate 3rd party transforms into MONAI program.
10. IO factory for medical image formats¶
Many popular image formats exist in the medical domain, and they are quite different with rich meta data information. To easily handle different medical image formats in the same pipeline, MONAI provides LoadImage transform, which uses ITKReader as the default image reader and also supports to register other readers, like NibabelReader, NumpyReader, and PILReader. The ImageReader API is quite straight-forward, users can easily extend for their own customized image readers.
With these pre-defined image readers, MONAI can load images in formats: NIfTI, DICOM, PNG, JPG, BMP, NPY/NPZ, etc.
Datasets¶
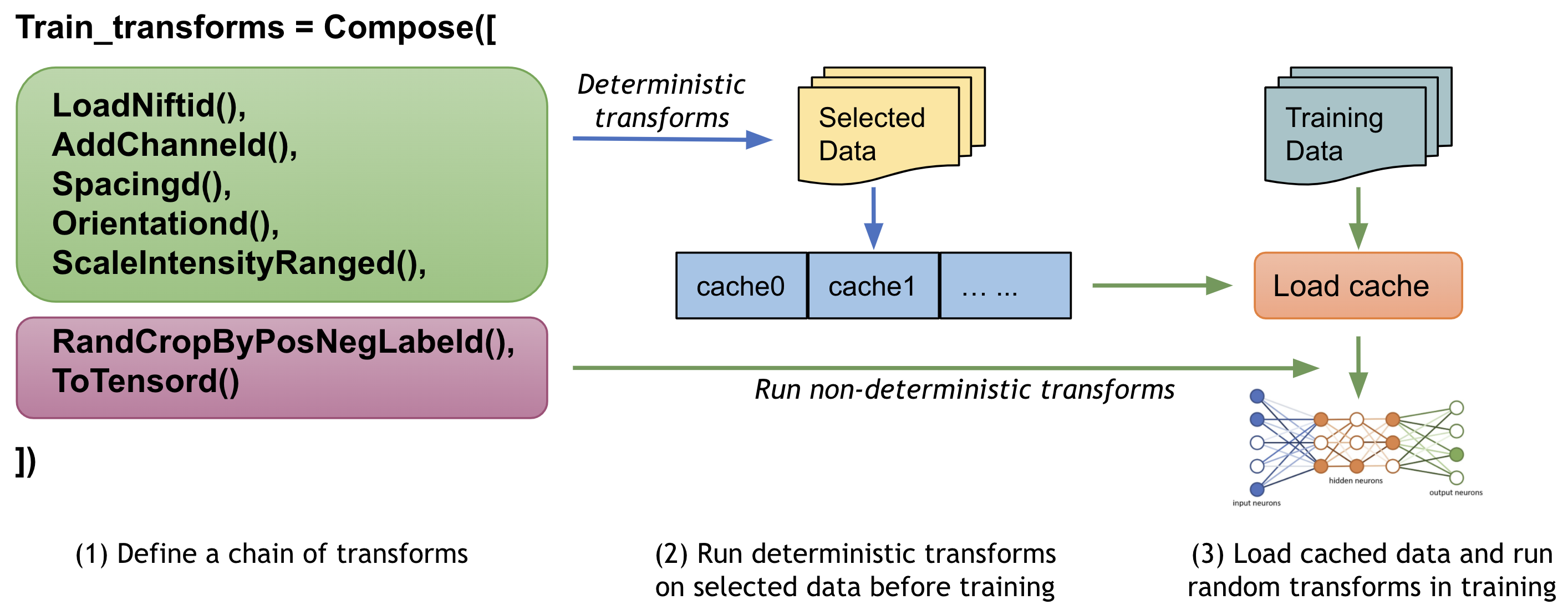
1. Cache IO and transforms data to accelerate training¶
Users often need to train the model with many (potentially thousands of) epochs over the data to achieve the desired model quality. A native PyTorch implementation may repeatedly load data and run the same preprocessing steps for every epoch during training, which can be time-consuming and unnecessary, especially when the medical image volumes are large.
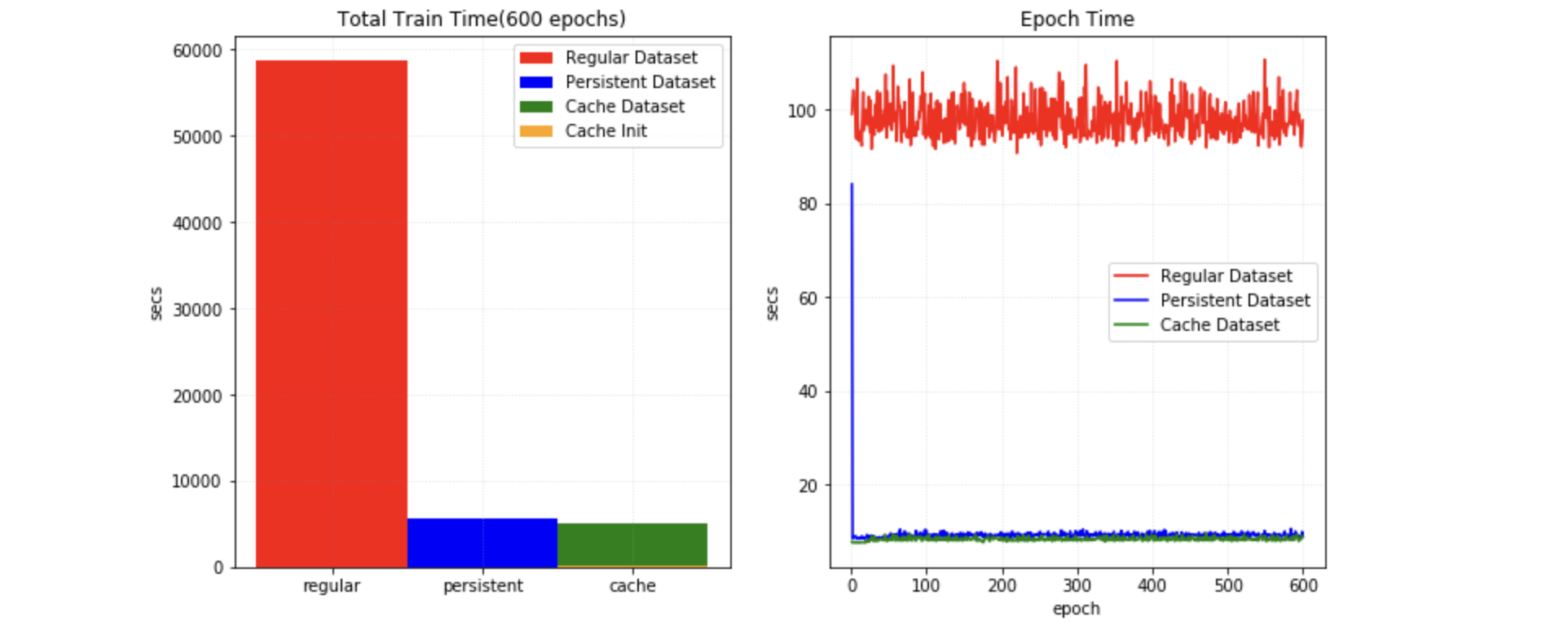
MONAI provides a multi-threads CacheDataset to accelerate these transformation steps during training by storing the intermediate outcomes before the first randomized transform in the transform chain. Enabling this feature could potentially give 10x training speedups in the Datasets experiment.
2. Cache intermediate outcomes into persistent storage¶
The PersistentDataset is similar to the CacheDataset, where the intermediate cache values are persisted to disk storage for rapid retrieval between experimental runs (as is the case when tuning hyperparameters), or when the entire data set size exceeds available memory. The PersistentDataset could achieve similar performance when comparing to CacheDataset in Datasets experiment.
3. SmartCache mechanism for big datasets¶
During training with very big volume dataset, an efficient approach is to only train with a subset of the dataset in an epoch and dynamically replace part of the subset in every epoch. It’s the SmartCache mechanism in NVIDIA Clara-train SDK.
MONAI provides a PyTorch version SmartCache as SmartCacheDataset. In each epoch, only the items in the cache are used for training, at the same time, another thread is preparing replacement items by applying the transform sequence to items not in cache. Once one epoch is completed, SmartCache replaces the same number of items with replacement items.
For example, if we have 5 images: [image1, image2, image3, image4, image5], and cache_num=4, replace_rate=0.25. So the actual training images cached and replaced for every epoch are as below:
epoch 1: [image1, image2, image3, image4]
epoch 2: [image2, image3, image4, image5]
epoch 3: [image3, image4, image5, image1]
epoch 3: [image4, image5, image1, image2]
epoch N: [image[N % 5] ...]
Full example of SmartCacheDataset is available at Distributed training with SmartCache.
4. Zip multiple PyTorch datasets and fuse the output¶
MONAI provides ZipDataset to associate multiple PyTorch datasets and combine the output data (with the same corresponding batch index) into a tuple, which can be helpful to execute complex training processes based on various data sources.
For example:
class DatasetA(Dataset):
def __getitem__(self, index: int):
return image_data[index]
class DatasetB(Dataset):
def __getitem__(self, index: int):
return extra_data[index]
dataset = ZipDataset([DatasetA(), DatasetB()], transform)
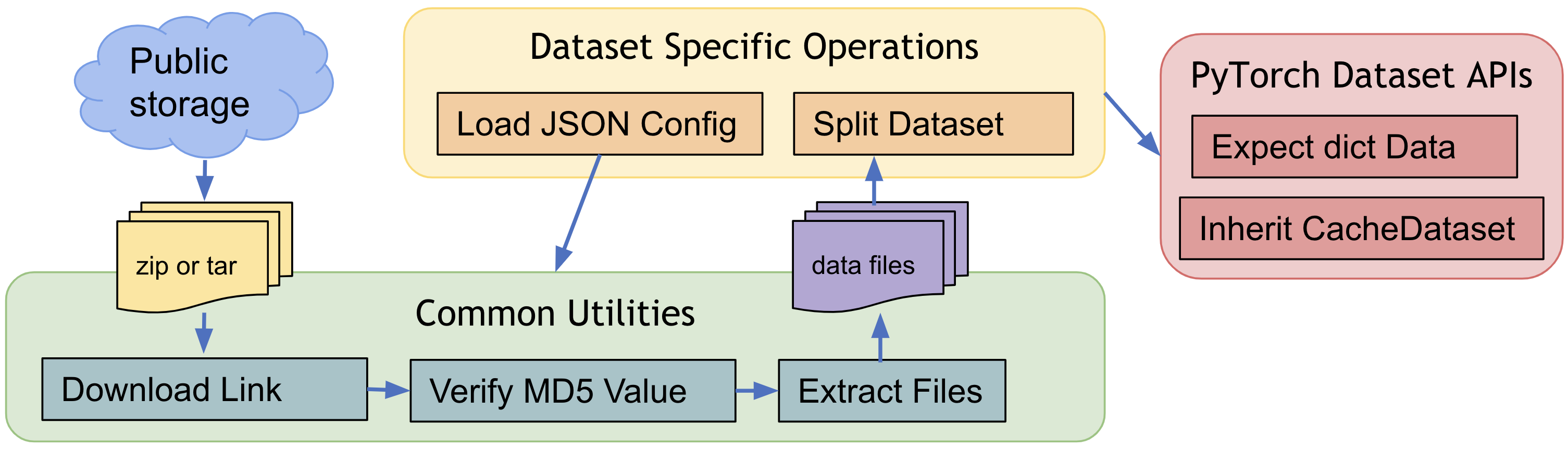
5. Predefined Datasets for public medical data¶
To quickly get started with popular training data in the medical domain, MONAI provides several data-specific Datasets(like: MedNISTDataset, DecathlonDataset, etc.), which include downloading from our AWS storage, extracting data files and support generation of training/evaluation items with transforms. And they are flexible that users can easily modify the JSON config file to change the default behaviors.
MONAI always welcome new contributions of public datasets, please refer to existing Datasets and leverage the download and extracting APIs, etc. Public datasets tutorial indicates how to quickly set up training workflows with MedNISTDataset and DecathlonDataset and how to create a new Dataset for public data.
The common workflow of predefined datasets:
Losses¶
There are domain-specific loss functions in the medical imaging research which are not typically used in the generic computer vision tasks. As an important module of MONAI, these loss functions are implemented in PyTorch, such as DiceLoss, GeneralizedDiceLoss, MaskedDiceLoss, TverskyLoss and FocalLoss, etc.
Network architectures¶
Some deep neural network architectures have shown to be particularly effective for medical imaging analysis tasks. MONAI implements reference networks with the aims of both flexibility and code readability.
To leverage the common network layers and blocks, MONAI provides several predefined layers and blocks which are compatible with 1D, 2D and 3D networks. Users can easily integrate the layer factories in their own networks.
For example:
# import MONAI’s layer factory
from monai.networks.layers import Conv
# adds a transposed convolution layer to the network
# which is compatible with different spatial dimensions.
name, dimension = Conv.CONVTRANS, 3
conv_type = Conv[name, dimension]
add_module('conv1', conv_type(in_channels, out_channels, kernel_size=1, bias=False))
And there are several 1D/2D/3D-compatible implementations of intermediate blocks and generic networks, such as UNet, DynUNet, DenseNet, GAN, AHNet, VNet, SENet(and SEResNet, SEResNeXt), SegResNet, etc.
Evaluation¶
To run model inferences and evaluate the model quality, MONAI provides reference implementations for the relevant widely-used approaches. Currently, several popular evaluation metrics and inference patterns are included:
1. Sliding window inference¶
For model inferences on large volumes, the sliding window approach is a popular choice to achieve high performance while having flexible memory requirements (alternatively, please check out the latest research on model parallel training using MONAI). It also supports overlap and blending_mode configurations to handle the overlapped windows for better performances.
A typical process is:
Select continuous windows on the original image.
Iteratively run batched window inferences until all windows are analyzed.
Aggregate the inference outputs to a single segmentation map.
Save the results to file or compute some evaluation metrics.
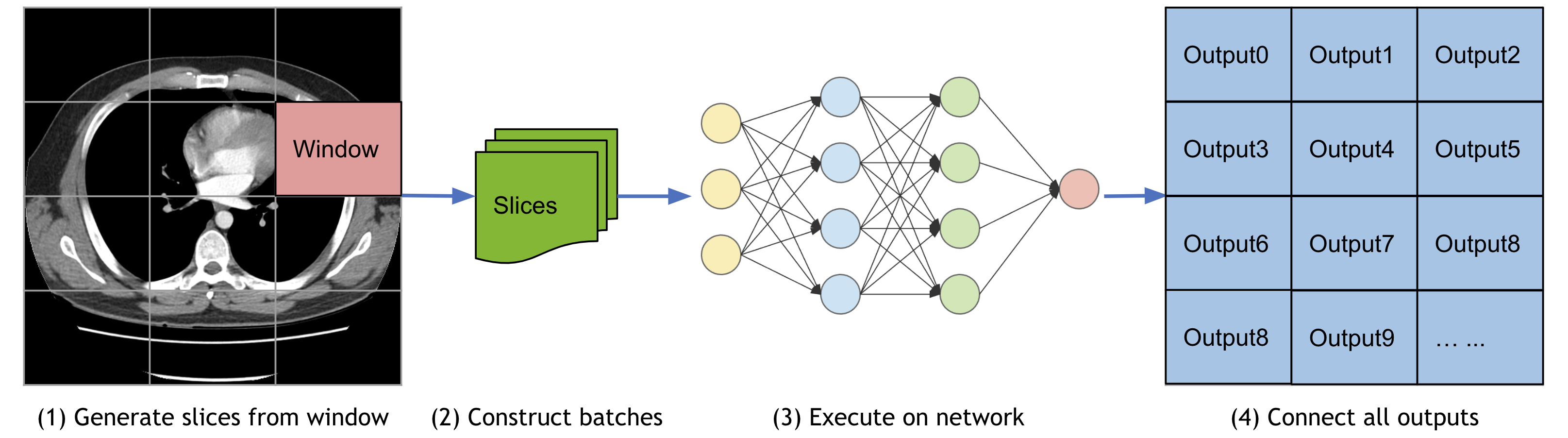
The Spleen 3D segmentation tutorial leverages SlidingWindow inference for validation.
2. Metrics for medical tasks¶
Various useful evaluation metrics have been used to measure the quality of medical image specific models. MONAI already implemented many medical domain-specific metrics, such as: Mean Dice, ROCAUC, Confusion Matrices, Hausdorff Distance, Surface Distance, etc.
For example, Mean Dice score can be used for segmentation tasks and the area under the ROC curve(ROCAUC) for classification tasks. We continue to integrate more options.
Visualization¶
Beyond the simple point and curve plotting, MONAI provides intuitive interfaces to visualize multidimensional data as GIF animations in TensorBoard. This could provide a quick qualitative assessment of the model by visualizing, for example, the volumetric inputs, segmentation maps, and intermediate feature maps. A runnable example with visualization is available at UNet training example.
Result writing¶
Currently MONAI supports writing the model outputs as NIfTI files or PNG files for segmentation tasks, and as CSV files for classification tasks. And the writers can restore the data spacing, orientation or shape according to the original_shape or original_affine information from the input image.
A rich set of formats will be supported soon, along with relevant statistics and evaluation metrics automatically computed from the outputs.
Workflows¶
To quickly set up training and evaluation experiments, MONAI provides a set of workflows to significantly simplify the modules and allow for fast prototyping.
These features decouple the domain-specific components and the generic machine learning processes. They also provide a set of unify APIs for higher level applications (such as AutoML, Federated Learning).
The trainers and evaluators of the workflows are compatible with pytorch-ignite Engine and Event-Handler mechanism. There are rich event handlers in MONAI to independently attach to the trainer or evaluator.
1. General workflows pipeline¶
The workflow and event handlers are shown as below:
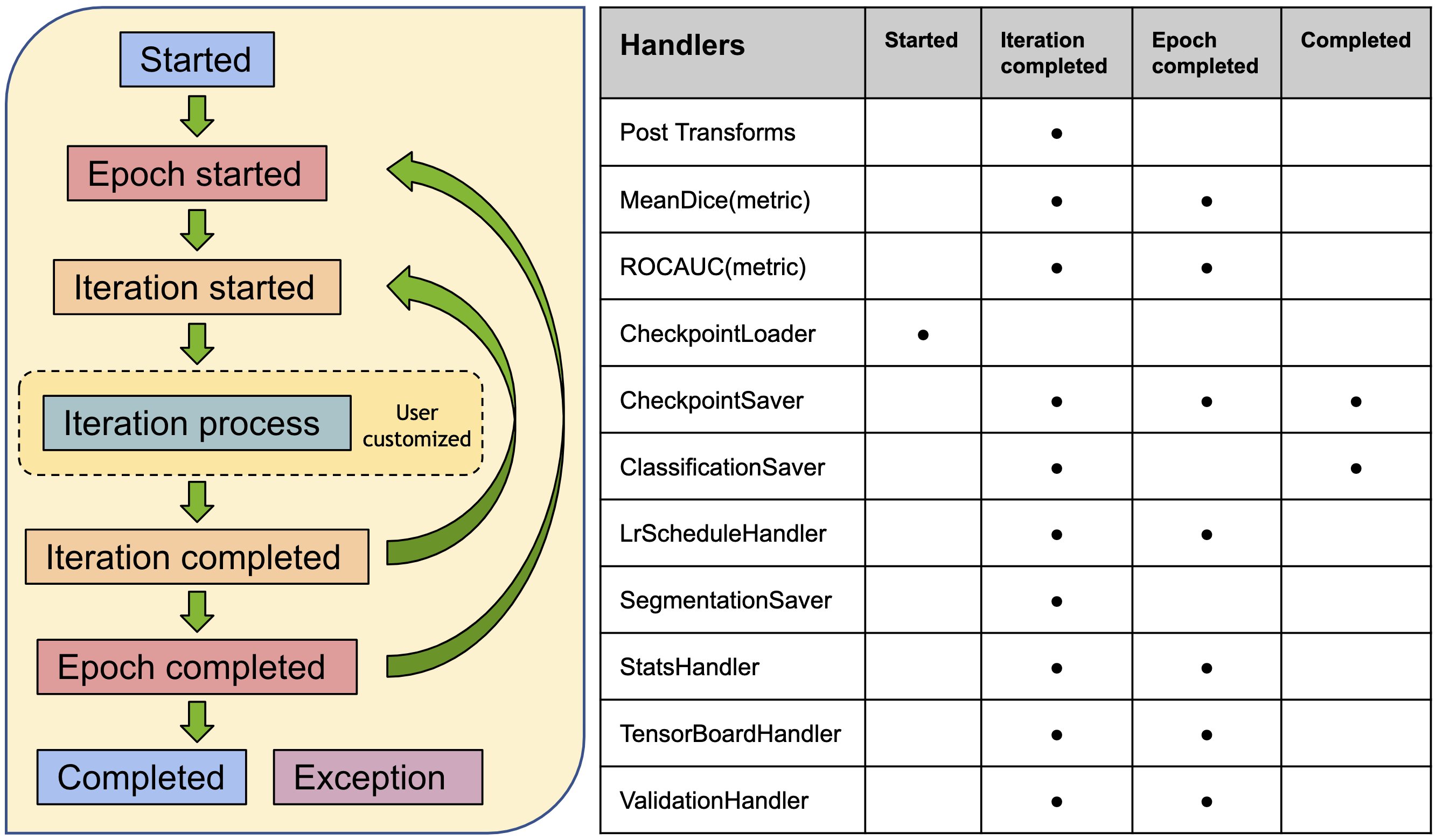
The end-to-end training and evaluation examples are available at Workflow examples.
2. EnsembleEvaluator¶
Models ensemble is a popular strategy in machine learning and deep learning areas to achieve more accurate and more stable outputs. A typical practice is:
Split all the training dataset into K folds.
Train K models with every K-1 folds data.
Execute inference on the test data with all the K models.
Compute the average values with weights or vote the most common value as the final result.
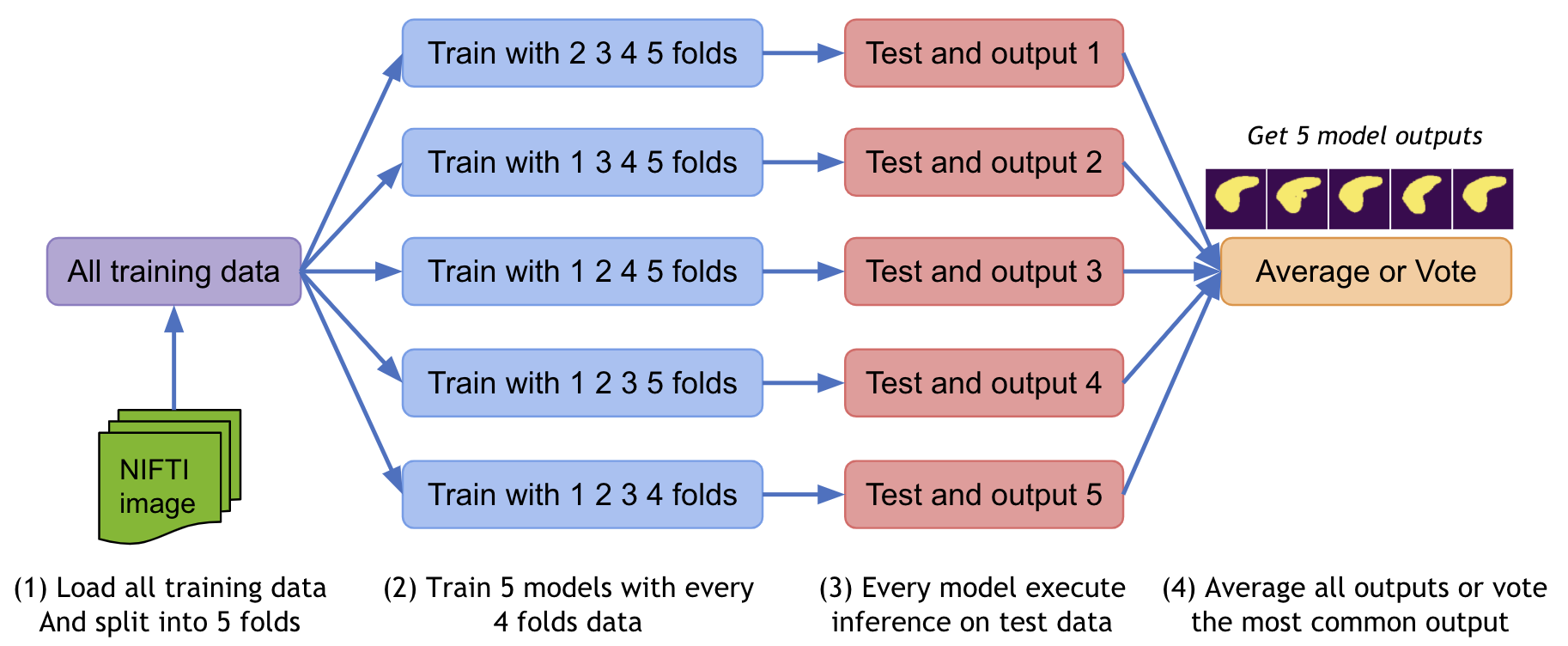 More details of practice is at Model ensemble tutorial.
More details of practice is at Model ensemble tutorial.
Research¶
There are several research prototypes in MONAI corresponding to the recently published papers that address advanced research problems. We always welcome contributions in forms of comments, suggestions, and code implementations.
The generic patterns/modules identified from the research prototypes will be integrated into MONAI core functionality.
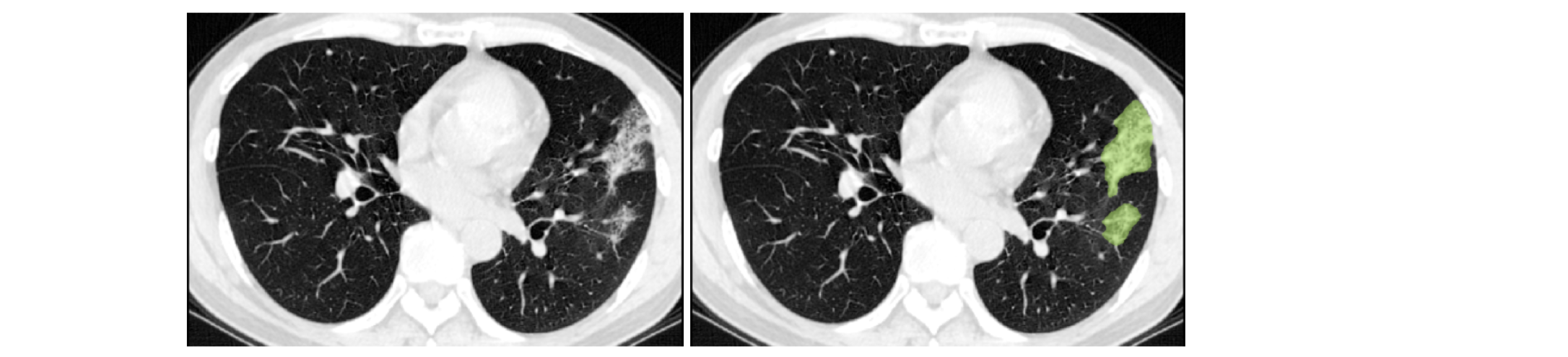
1. COPLE-Net for COVID-19 Pneumonia Lesion Segmentation¶
A reimplementation of the COPLE-Net originally proposed by:
G. Wang, X. Liu, C. Li, Z. Xu, J. Ruan, H. Zhu, T. Meng, K. Li, N. Huang, S. Zhang. (2020) “A Noise-robust Framework for Automatic Segmentation of COVID-19 Pneumonia Lesions from CT Images.” IEEE Transactions on Medical Imaging. 2020. DOI: 10.1109/TMI.2020.3000314
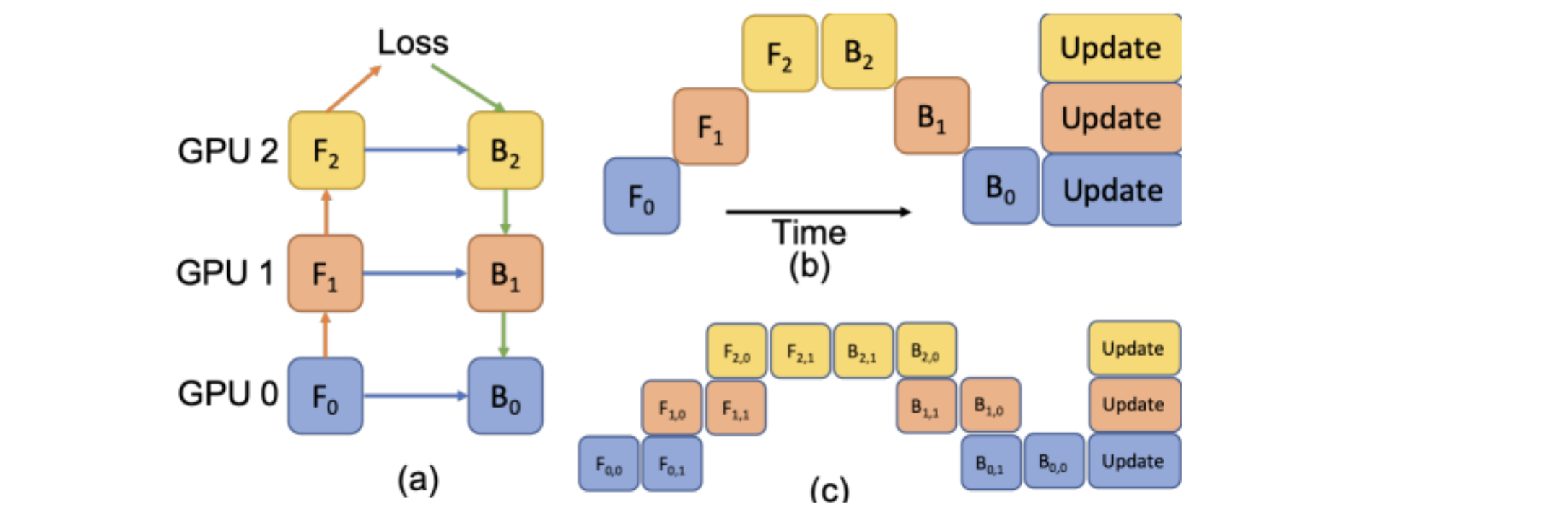
2. LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation¶
A reimplementation of the LAMP system originally proposed by:
Wentao Zhu, Can Zhao, Wenqi Li, Holger Roth, Ziyue Xu, and Daguang Xu (2020) “LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation.” MICCAI 2020 (Early Accept, paper link: https://arxiv.org/abs/2006.12575)
GPU acceleration¶
NVIDIA GPUs have been widely applied in many areas of deep learning training and evaluation, and the CUDA parallel computation shows obvious acceleration when comparing to traditional computation methods. To fully leverage GPU features, many popular mechanisms raised, like automatic mixed precision (AMP), distributed data parallel, etc. MONAI can support these features and provides rich examples.
1. Auto mixed precision(AMP)¶
In 2017, NVIDIA researchers developed a methodology for mixed-precision training, which combined single-precision (FP32) with half-precision (e.g. FP16) format when training a network, and it achieved the same accuracy as FP32 training using the same hyperparameters.
For the PyTorch 1.6 release, developers at NVIDIA and Facebook moved mixed precision functionality into PyTorch core as the AMP package, torch.cuda.amp.
MONAI workflows can easily set amp=True/False in SupervisedTrainer or SupervisedEvaluator during training or evaluation to enable/disable AMP. And we tried to compare the training speed if AMP ON/OFF on Tesla V100 GPU with CUDA 11 and PyTorch 1.6, got some benchmark for reference:
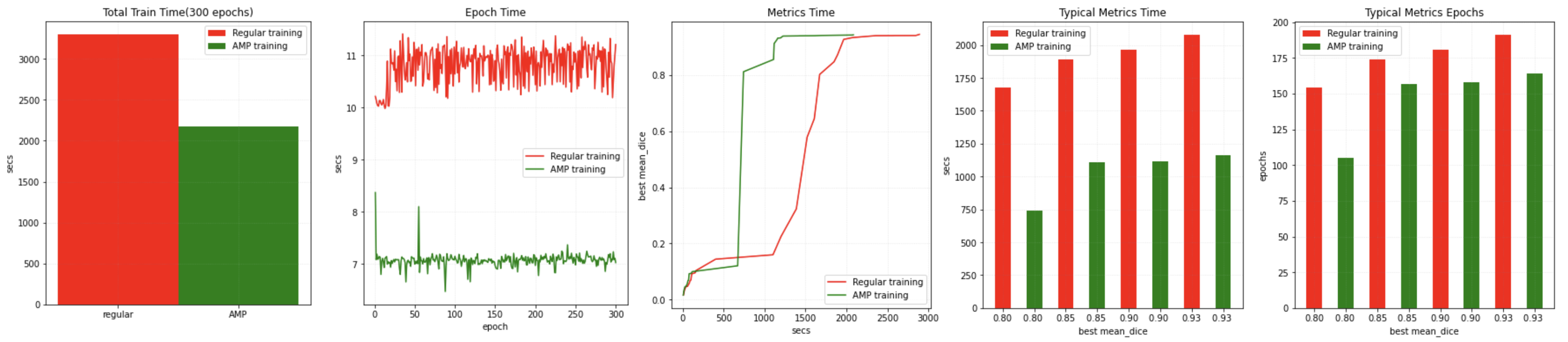 We also executed the same test program on Testa A100 GPU with the same software environment, got much faster benchmark for reference:
We also executed the same test program on Testa A100 GPU with the same software environment, got much faster benchmark for reference:
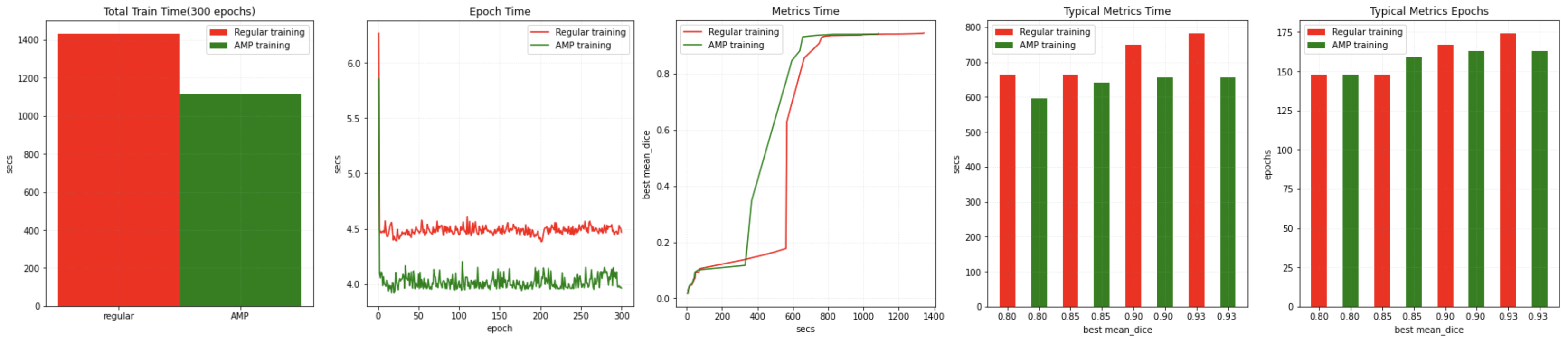 More details is available at AMP training tutorial.
We also tried to combine AMP with
More details is available at AMP training tutorial.
We also tried to combine AMP with CacheDataset and Novograd optimizer to achieve the fast training in MONAI, able to obtain approximately 12x speedup compared with a Pytorch native implementation when the training converges at a validation mean dice of 0.93. Benchmark for reference:
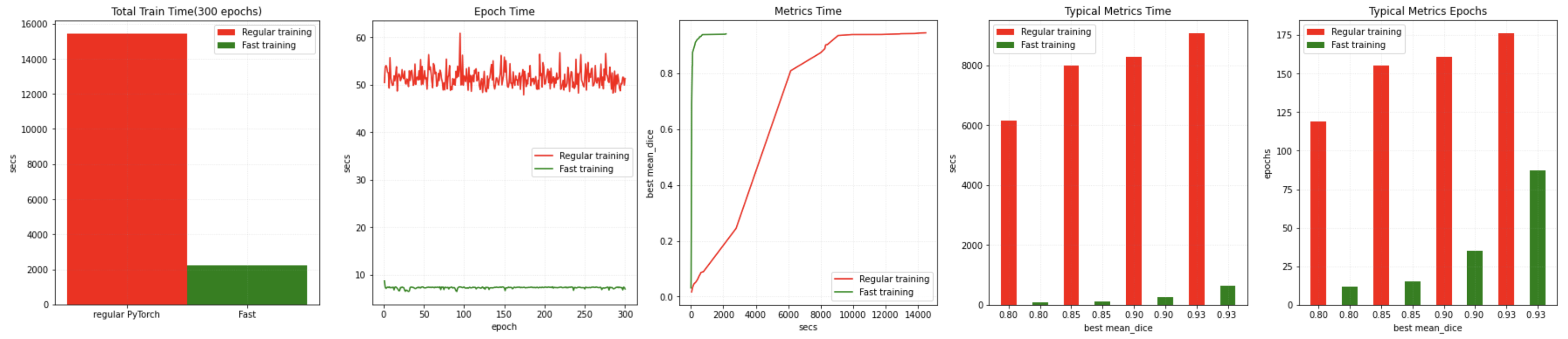 More details is available at Fast training tutorial.
More details is available at Fast training tutorial.
2. Distributed data parallel¶
Distributed data parallel is an important feature of PyTorch to connect multiple GPU devices on 1 node or several nodes to train or evaluate models. MONAI provides many demos for reference: train/evaluate with PyTorch DDP, train/evaluate with Horovod, train/evaluate with Ignite DDP, partition dataset and train with SmartCacheDataset, etc. And also provides a real world training example based on Decathlon challenge Task01 - Brain Tumor segmentation, it contains distributed caching, training, and validation. We tried to train this example on NVIDIA NGC server, got some performance benchmarks for reference(PyTorch 1.6, CUDA 11, Tesla V100 GPUs):
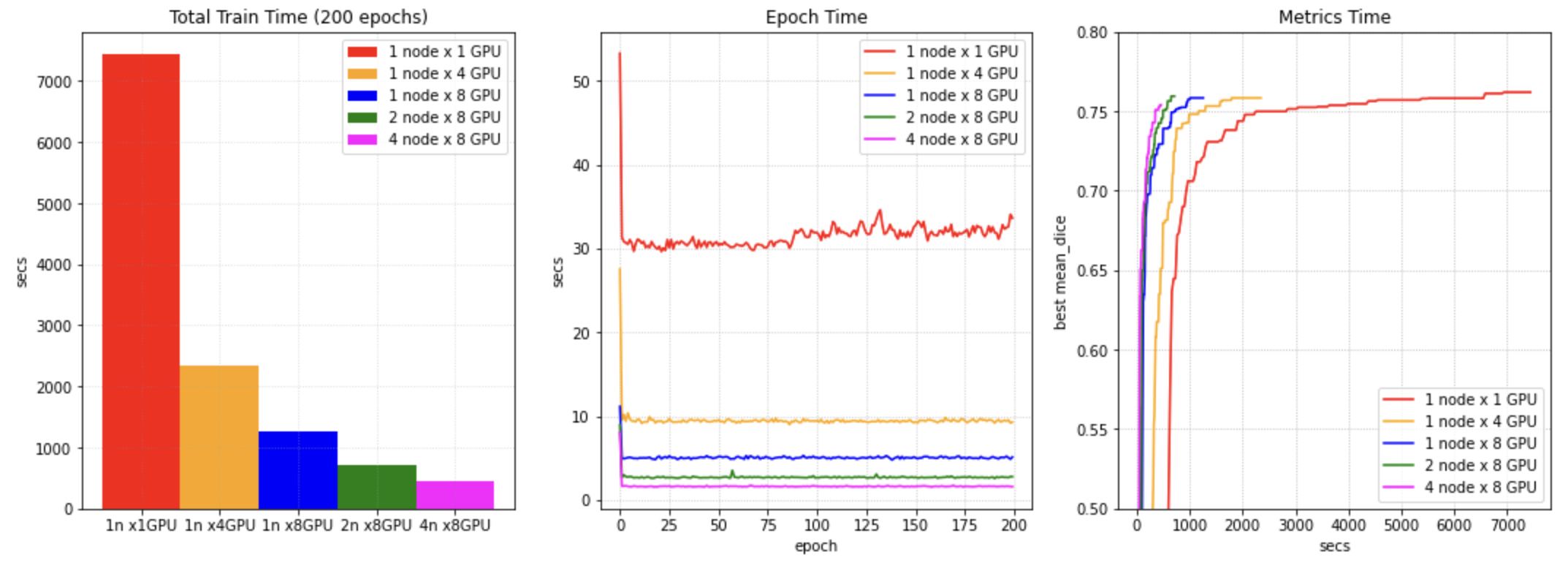
3. C++/CUDA optimized modules¶
To accelerate some heavy computation progress, C++/CUDA implementation can be an impressive method, which usually brings even hundreds of times faster performance. MONAI contains some C++/CUDA optimized modules, like Resampler,and fully support C++/CUDA programs in CI/CD and building package.